- The paper introduces a novel method that fuses neural network models through concatenation, structured pruning, and fine-tuning.
- It achieves improved accuracy, reduced memory overhead, and faster inference compared to traditional ensemble approaches.
- The technique scales across various architectures, offering practical benefits for efficient deployment in resource-constrained settings.
Model Fusion via Neuron Transplantation
The paper "Model Fusion via Neuron Transplantation" introduces a novel method to fuse neural network models through a technique termed Neuron Transplantation (NT). This method addresses the computational challenges associated with ensemble learning by reducing memory requirements and inference time while maintaining, and often enhancing, performance outcomes compared to individual models.
Neuron Transplantation Overview
Ensemble learning typically yields superior prediction performance but at the cost of increased computational and memory demands. Neuron Transplantation proposes a two-stage process to efficiently fuse models:
- Concatenation and Initial Pruning: Models of the same architecture are concatenated, effectively creating a supersized model. This large model is then pruned to discard low-magnitude neurons, focusing only on neurons contributing significantly to the performance.
- Fine-tuning: The pruned model is fine-tuned on the training data to recover any lost performance.
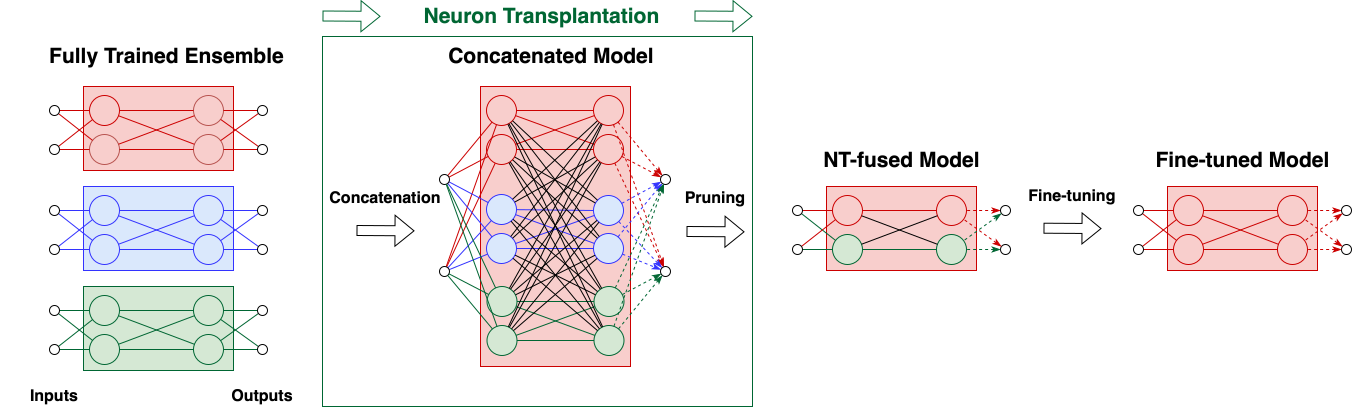
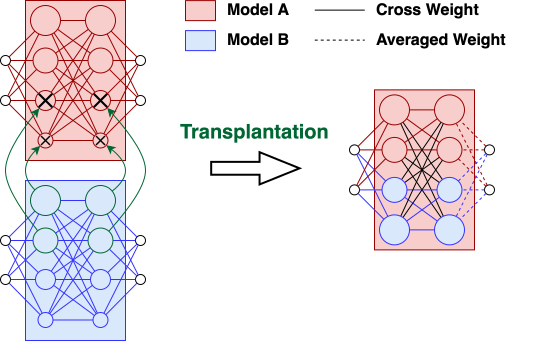
Figure 1: Neuron Transplantation. Low-magnitude neurons are replaced by large-magnitude ones from other models.
This approach contrasts with traditional weight-averaging techniques, which often suffer from a loss barrier due to alignment issues between models. NT focuses on important neurons, thus bypassing such issues.
Model Fusion Pipeline
The process of model fusion through Neuron Transplantation involves several structured steps as detailed below:
- Model Training: Each model in the ensemble is trained independently on the dataset using standard training protocols.
- Layer Concatenation: Non-output layers from all models are concatenated vertically, preserving individual model characteristics while output layers are averaged.
Figure 2: Pipeline of fusing multiple ensemble members. Multiple models are trained independently, concatenated into one large model, pruned down to the original size, and then fine-tuned.
- Structured Pruning: The concatenated model is pruned via structured magnitude pruning, effectively reducing the number of parameters to that of a single model. This step ensures that the fused network retains only the neurons with the highest impact on performance.
- Fine-tuning: The resulting model is fine-tuned to fill any performance gaps left by the pruning stage, enhancing overall predictive capabilities and sometimes exceeding the performance of the best single model in the ensemble.
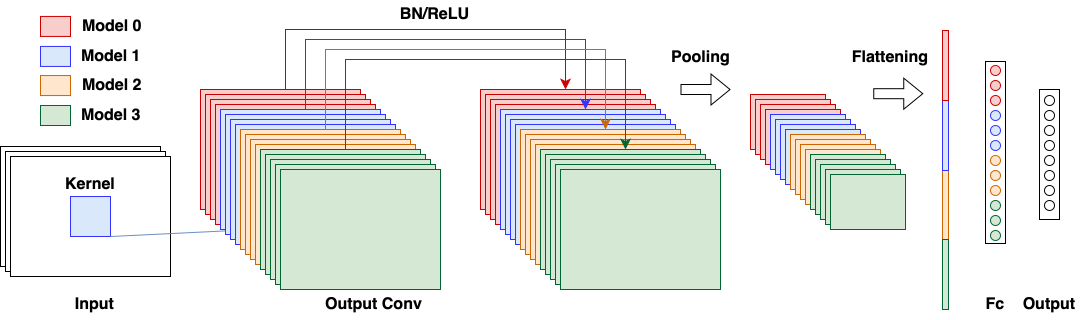
Figure 3: Concatenating 2D convolution layers. Channels are stacked, batch normalization and pooling operations are preserved.
Evaluation and Results
The paper evaluates NT against state-of-the-art methods such as Optimal Transport (OT) fusion and traditional averaging. Key findings include:
- Speed and Memory Efficiency: NT requires significantly less computational overhead than OT, which involves solving large-scale permutation alignments.
- Performance: Post-fusion, NT-fused models achieve higher accuracy sooner compared to other methods, often surpassing the performance of individual models after a few epochs.
- Scalability: The fusion of a larger number of models demonstrates diminishing returns, but NT maintains efficiency across various architectures and datasets.
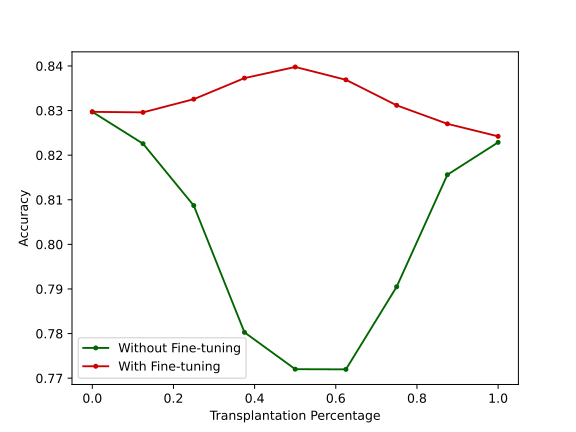
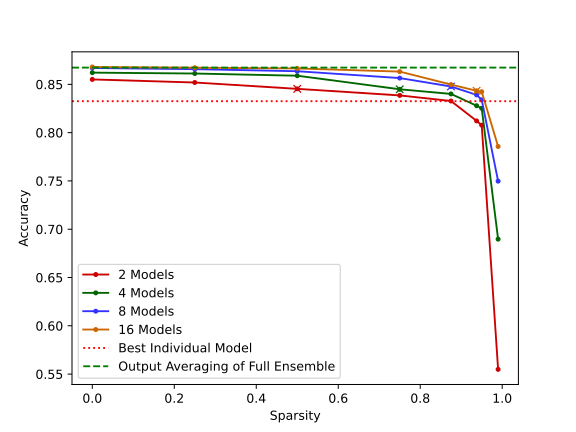
Figure 4: Left: Transplanting different neuron amounts of one model into another. Right: Fusing multiple models and pruning to specific sparsity ratios followed by 30 epochs of fine-tuning.
Practical Implications and Future Work
The practical implications of Neuron Transplantation are significant for fields requiring model compression and efficient deployment, such as federated learning and on-device AI. The method's compatibility with various neural architectures suggests broad applicability.
Future directions include extending NT to non-convolutional architectures like transformers and investigating its integration into distributed learning frameworks. A potential exploration is the formulation of heuristics for assessing model diversity, ensuring NT is applied optimally to diverse enough models to leverage its full benefits.
Conclusion
Neuron Transplantation presents a scalable and effective model fusion technique that addresses computational constraints inherent in ensemble methods. By replacing less significant neurons with impactful ones, NT not only improves efficiency but enhances performance through a structured, computationally economical process.