- The paper introduces a modular blueprint that organizes RLM components into a toolbox to democratize advanced reasoning capabilities.
- The paper details a novel architecture with inference, training, and data generation pipelines that leverage MCTS for structured decision making.
- The paper demonstrates the x1 framework, which scales using multi-GPU optimization and employs metrics like variance and entropy for robust evaluation.
Reasoning LLMs: A Blueprint
This essay provides a detailed summary of the paper "Reasoning LLMs: A Blueprint" (2501.11223), which addresses the challenges posed by the high cost, proprietary nature, and complex architectures of Reasoning LLMs (RLMs). The paper introduces a modular framework that organizes RLM components, aiming to democratize advanced reasoning capabilities and foster innovation in the field.
Addressing the RLM Accessibility Gap
The paper identifies a growing divide between "rich AI" and "poor AI" due to the inaccessibility of state-of-the-art RLMs. It argues that the high cost and proprietary nature of models developed by organizations like OpenAI exacerbate existing inequities. To mitigate these challenges, the paper proposes a comprehensive blueprint for constructing, analyzing, and experimenting with RLMs. This blueprint aims to clarify the intricate design of RLMs by organizing their core components into a modular toolbox, complete with architectural diagrams, mathematical formulations, and algorithmic specifications.

Figure 1: Summary of the contributions made by this paper.
Evolution and Foundations of Reasoning LMs
The development of reasoning-capable LLMs is presented as a convergence of three critical threads: advances in LLMs, RL designs, and HPC resources. LLMs serve as repositories of world knowledge, while RL provides a framework for decision-making and exploration. HPC resources enable the scalability and efficiency required to train and deploy these models. The paper distinguishes between interpolation performed by standard LLMs and extrapolation enabled by RLMs, highlighting RLMs' ability to navigate uncharted areas of the solution space. A hierarchy of reasoning-related models is also introduced, categorizing them into implicit and explicit reasoning models.
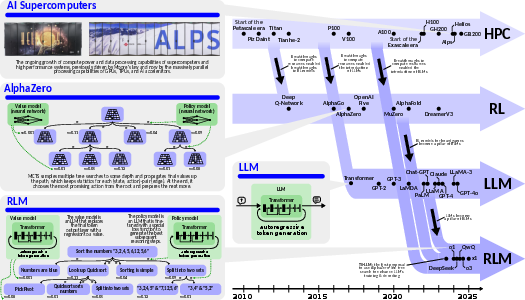
Figure 2: The history of RLMs. This class of models has been the result of the development of three lines of works: (1) Reinforcement Learning based models such as AlphaZero [silver2018general], (2) LLM and Transformer based models such as GPT-4o [openai2024hello], and (3) the continuous growth of compute power and data processing capabilities of supercomputers and high performance systems.
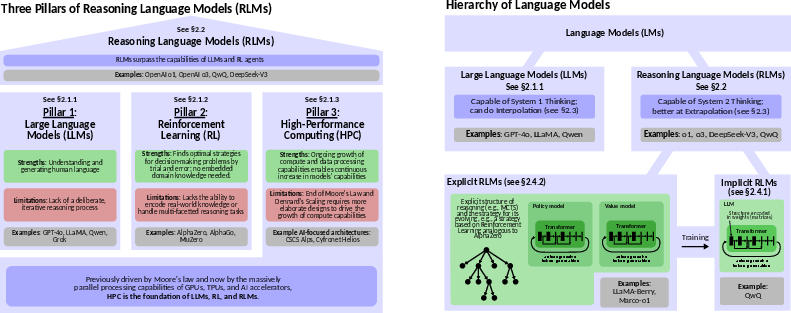
Figure 3: Hierarchy of LLMs (right) and the three pillars of RLMs (left).
Core RLM Architecture and Concepts
The paper describes the general architecture of RLMs, consisting of three main pipelines: inference, training, and data generation. The inference pipeline serves user requests using models provided by the training pipeline, while data generation mirrors the inference pipeline to generate data for retraining the models. The inference process involves constructing a reasoning structure, typically a tree, where each node represents a reasoning step. The evolution of this structure is governed by MCTS, enhanced with policy and value models. The training framework includes both supervised and unsupervised training pipelines, with data collected from inference and synthetic data generation.
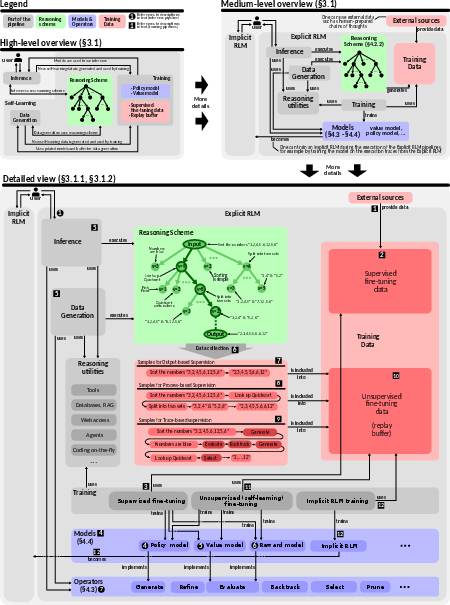
Figure 4: Overview of a general RLM design and core concepts. We provide a high-level overview (the top-left part), a more detailed medium-level overview (the top-right part), and a very detailed diagram showing the inference and training pipelines (the bottom part). A detailed specification of the inference pipeline can be found in Appendix~\ref{sec:mcts_algo_description} and in Algorithm~\ref{alg:mcts_star}.
A Modular Blueprint for RLM Construction
The paper introduces a blueprint that specifies a toolbox of components for building arbitrary RLMs. The blueprint includes a reasoning scheme (specifying a reasoning structure and strategy), a set of operators (e.g., Refine) that can be applied to the reasoning structure, models (e.g., Policy Model) used to implement the operators, and a set of pipelines that orchestrate the interaction between the reasoning scheme and the operators. Reasoning structures can include chains, trees, graphs, and nested structures. Reasoning strategies include MCTS, Beam Search, and ensemble methods. Operators are categorized into structure operators, traversal operators, update operators, and evaluate operators.
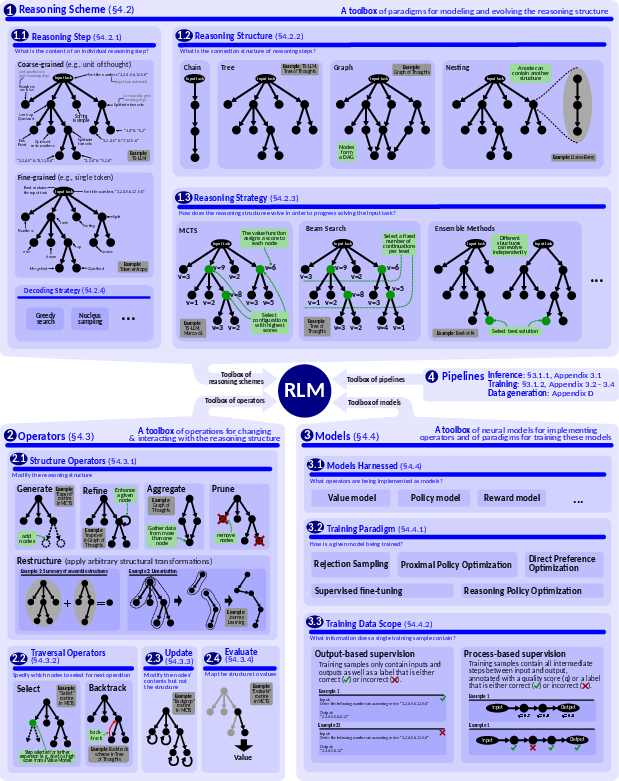
Figure 5: A blueprint for reasoning LMs. It consists of four main toolboxes: the reasoning scheme (the top part), operators (the bottom-left part), and models (the bottom-right part); pipelines are mentioned in the center and detailed in Appendix~\ref{sec:mcts_algo_description}.
x1 Framework: Implementation and Design
To demonstrate the utility of the blueprint, the paper introduces x1, an extensible and minimalist framework for designing and experimenting with RLMs. The x1 framework employs a tree reasoning structure with MCTS, and implements operators for generating, traversing, evaluating, and updating the reasoning tree. The framework includes value and policy models, and is designed to scale to multiple GPUs on multiple nodes. Key optimizations include batching, quantization, and KV caching. The framework also enables detailed analyses of strategies for generating and selecting fine-grained token-based reasoning steps using metrics like variance, entropy, and the Gini coefficient.
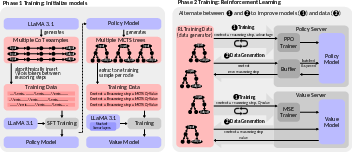
Figure 6: An overview of the x1 framework is presented, highlighting its two-phase training process. In phase 1, the models are initialized, while in phase 2, the models are iteratively refined by alternating between constructing a sufficient number of MCTS trees and training the models on data derived from these trees.
Key Insights for Effective RLMs
The paper provides several insights for effective RLM design, including the importance of process-based evaluation, using a two-phase training strategy (SFT and RL), training on familiar distributions, and being cautious when prompting LLMs to critique and evaluate their own outputs. It suggests that relying solely on prompting for self-correction often leads to instability, and that structured training approaches and careful operator design are crucial for self-improvement capabilities in RLMs.
Benchmarking RLMs for Robust Evaluation
The paper emphasizes the importance of robust benchmarking for RLMs, highlighting the need for sufficiently large sample sizes to ensure fair comparisons. It recommends benchmarks with at least 200 samples per category and a minimum of 500 samples evaluated per category to ensure robust performance comparisons due to the increased output variance that comes with including multiple models in a reasoning scheme. The paper also suggests utilizing templated versions of benchmarks where available to minimize contamination from prior exposure during model training.
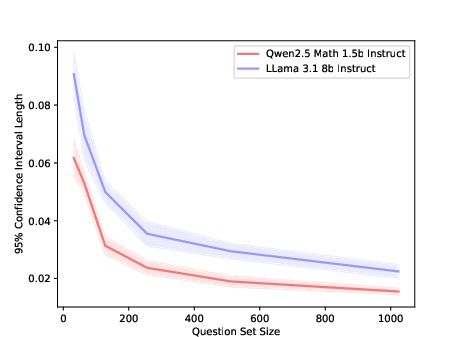
Figure 7: Estimated 95\%-confidence interval length for different question set sizes using sampled generated answers from a subset of 1000 questions with eight generated answers per question at temperature 1. The confidence interval is calculated over the eight different pass@1 subsets of each question with 32 sets randomly sampled with replacement for each set size.
Conclusion
The paper presents a comprehensive blueprint for RLMs, along with a practical implementation in the form of the x1 framework. By providing a modular and accessible framework, this work aims to democratize advanced reasoning capabilities and foster innovation in the field. The blueprint and implementation pave the way for future advancements in reasoning AI, inspiring the development of new RLM architectures and enabling researchers to experiment with refined training paradigms and adaptive search strategies.

