- The paper introduces Parameter-Reduced Kolmogorov-Arnold Networks that leverage attention mechanisms, convolutional layers, and feature weight vectors to significantly reduce parameter demands.
- It applies techniques like dimension summation and global attention to maintain robust network performance while cutting down on parameter counts compared to traditional MLPs.
- Experimental evaluations on MNIST and Fashion-MNIST show that PRKAN models achieve competitive validation accuracy with a fraction of the parameters typically required.
PRKAN: Parameter-Reduced Kolmogorov-Arnold Networks
Introduction to Kolmogorov-Arnold Networks
Kolmogorov-Arnold Networks (KANs) offer an innovative approach in neural network design, stemming from the Kolmogorov-Arnold Representation Theorem (KART). This theorem states that any multivariate continuous function can be decomposed into a sum of univariate continuous functions, which laid the foundation for KANs. Having seen limited initial adoption due to computational inefficiency relative to MLPs, recent efforts have introduced several blends of activation functions such as B-splines and RBFs, aimed at competitively capturing data features compared to traditional neural network architectures.
Addressing Parameter Inefficiency in KANs
KAN layers typically demand a higher number of parameters than MLP layers, primarily due to complex function representations required to approximate the multivariate functions they aim to model. This paper introduces Parameter-Reduced KANs (PRKANs) to bridge this parameter efficiency gap by leveraging several methods, notably attention mechanisms and convolutional layers, that seek to significantly reduce parameter usage while maintaining robust network structures.
Methodology of PRKAN
PRKANs explore several techniques to achieve parameter efficiency:
- Attention Mechanism: Inspired by global attention architectures, this method applies a multiplicative attention mechanism with a softmax function to emphasize pertinent input features.
- Convolutional Layers: Applied either individually or in conjunction with pooling layers, these are used to reduce data dimensionality while enhancing feature extraction capability.
- Dimension Summation: This simple yet efficient approach involves summing the basis-function-generated features, providing a lightweight mechanism to maintain parameter parsimony.
- Feature Weight Vectors: By using learnable vectors to reduce feature dimensionality in spline-transformed data, this vector-based approach effectively compresses data representation.
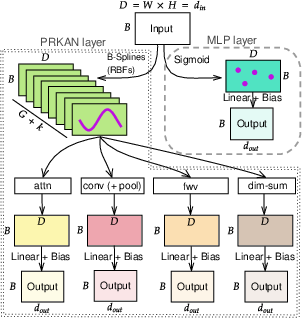
Figure 1: The diagram illustrates how the input (B,D) is passed through both MLP and PRKAN layers to produce the output $(B, d_{\text{out})$.
Experimental Evaluation
The paper provides thorough empirical evaluation using datasets such as MNIST and Fashion-MNIST. Findings suggest that PRKANs, particularly the variants using attention mechanisms, demonstrate competitive validation accuracy while maintaining a parameter count comparable to MLPs.
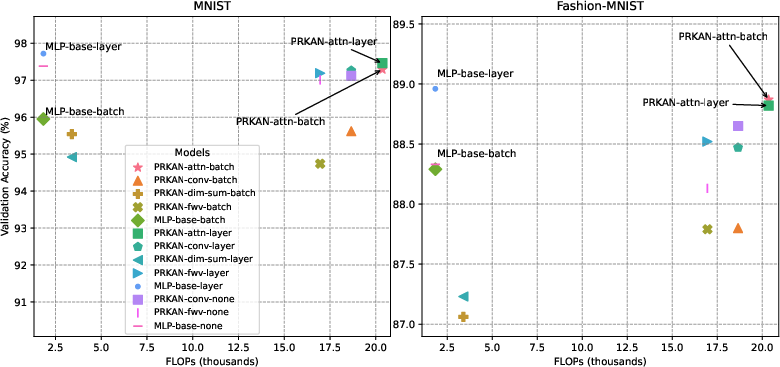
Figure 2: Models by FLOPs and validation accuracy values. PRKAN-conv{additional_guidance}pool models are excluded due to their massive use of FLOPs.
Additionally, the employment of Radial Basis Functions (GRBFs) demonstrated superior performance efficiency over traditional B-Splines when integrated with PRKANs, aligning with claims regarding GRBFs' computational advantage.
Comparison with Other KAN Models
When compared with existing Kolmogorov-Arnold Networks, PRKANs showcase significant advantages, managing to perform exceptionally well with a constrained parameter and FLOP budget. This further reiterates that with thoughtful architectural adjustments, PRKANs can emulate or surpass performance benchmarks set by traditional models.
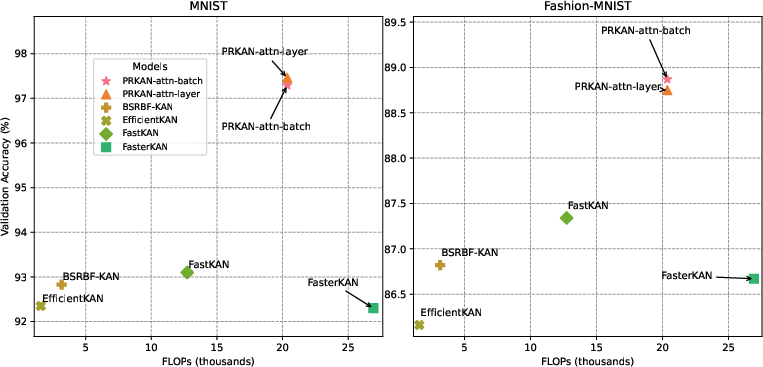
Figure 3: PRKAN-attn models with batch and layer normalization are compared to other existing KANs in terms of FLOPs and validation accuracy.
Implications and Future Directions
PRKANs provide a promising direction for reducing inefficiencies within legacy KANs, opening pathways for future exploration in deeper network structures where KANs historically struggle. The inclusion of advanced techniques like tensor decomposition or matrix factorization could further augment PRKANs, offering additional benefits in computational savings and accuracy elevation.
Conclusion
In establishing PRKANs, this paper makes strides in enhancing the practical applicability of Kolmogorov-Arnold Networks, resolving their long-standing inefficiency issues. Future work will likely explore broader architectural implications, seeking to blend the compactness and efficiency of PRKANs with the robustness required for more complex tasks.
By harnessing the potential of these reduced-parameter networks, the path is paved for more energy-efficient, scalable neural network architectures that retain high accuracy, charting a promising course for subsequent research and application in AI system design and deployment.