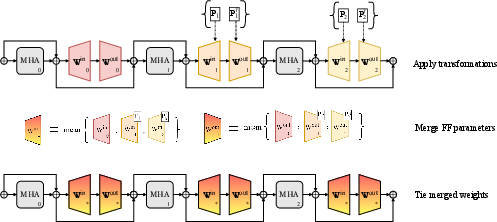
- The paper demonstrates that merging redundant feed-forward sublayers preserves nearly full performance while substantially reducing model parameters.
- It employs permutation-based neuron alignment to consolidate similar sublayers, effectively decreasing model complexity.
- Empirical evaluations across GPT-2, ViT, and OPUS-MT models show the method outperforming layer-dropping baselines in compression efficiency.
Introduction
The paper "Merging Feed-Forward Sublayers for Compressed Transformers" (2501.06126) addresses the ongoing need for effective model compression techniques in the context of increasingly large deep learning models. Traditional methods such as distillation, quantization, and pruning have generally focused on eliminating parameters deemed less important. In contrast, this research proposes a novel methodology centered on the identification and merging of redundant feature sets, specifically targeting the feed-forward (FF) sublayers of Transformers. This approach seeks to maintain or even improve performance while significantly reducing model size.
Methodology: Merging Feed-Forward Sublayers
The proposed merging technique introduces an innovative compression strategy that focuses on aligning and consolidating similar FF sublayers within Transformer architectures. The process is motivated by the inherent redundancy that exists across these sublayers, making them prime candidates for compression without significant performance loss. The key steps involved in the method include:
Empirical Evaluation
The efficacy of the proposed merging strategy is validated across multiple domains, including language modeling, image classification, and machine translation, utilizing GPT-2, Vision Transformer (ViT), and OPUS-MT models respectively. Noteworthy results from these experiments include:
- Near-original Performance: The merging strategy retains nearly the full performance of the uncompressed models even after a third of FF sublayers are merged. Specifically, for the ViT model, more than 21% of parameters were removed while retaining 99% of the original accuracy (Figure 2).
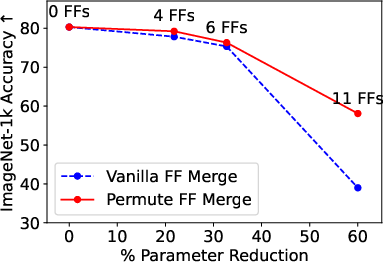
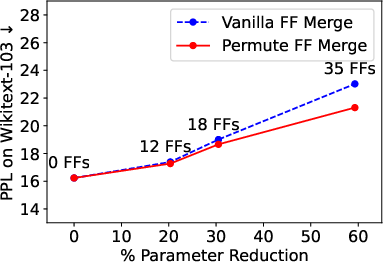
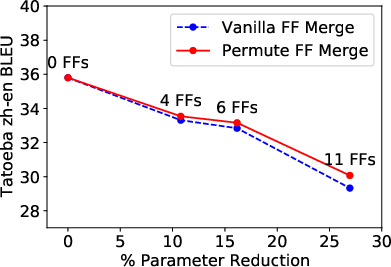
Figure 2: Results across all three tasks depicting compression versus performance results.
- Comparison with Layer-Dropping Baselines: When compared against a robust layer-dropping baseline, the merging method consistently matches or outperforms it across different levels of parameter reductions (Figure 3).
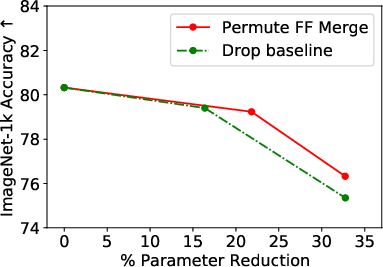
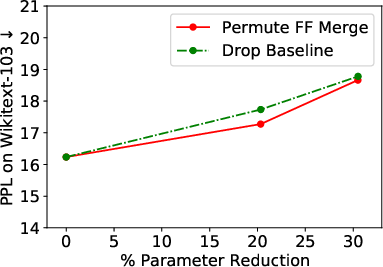
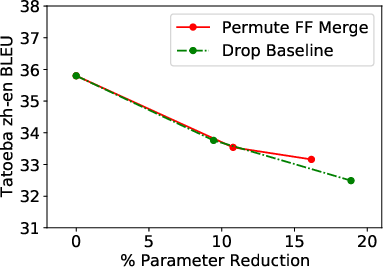
Figure 3: Results across all three tasks depicting compression versus performance for our method and a strong layer-dropping baseline method.
Theoretical Implications and Future Work
The successful application of merging FF sublayers suggests a reevaluation of compression strategies focusing on parameter redundancy. This insight propels future research directions, including the exploration of merging techniques on architectures beyond Transformers and investigating methods to achieve concurrent improvements in inference speed. Moreover, the demonstrated extension of this approach to various domains underscores its potential utility across diverse machine learning applications.
Present trends in neural network architecture suggest a continuous increase in model size, necessitating innovative compression techniques that balance computational efficiency and performance fidelity. The permutation-based merging approach introduced in this research presents a compelling alternative to traditional compression methodologies by targeting and exploiting sublayer similarities within existing models.
Conclusion
The introduction of a merging-based compression framework highlights a promising avenue for achieving substantial model size reduction while maintaining high performance in Transformer models. Through careful alignment and merging of FF sublayers, the research elucidates a practical, yet powerful, method for enhancing model deployability across varying hardware constraints. This work invites further exploration into redundancy exploitation and opens potential pathways for integrating similar compression strategies into broader neural architectures.