- The paper introduces Dolphin, a framework automating scientific research through iterative idea generation, experimental verification, and feedback.
- It employs literature retrieval, LLM-based filtering, and exception-traceback-guided debugging to enhance research quality and code execution success.
- Evaluations on benchmarks like ModelNet40 show Dolphin’s potential to achieve state-of-the-art performance in tasks such as 3D point cloud classification.
Dolphin: Closed-Loop Auto-Research Through Thinking, Practice, and Feedback
The paper introduces Dolphin, a closed-loop, open-ended framework for automatic scientific research, which integrates idea generation, experimental verification, and results feedback (2501.03916). This framework aims to address limitations in existing AI-assisted research methods by automating the entire research process and incorporating experimental outcomes to refine subsequent ideas. Dolphin enhances research efficiency by improving the quality of generated ideas and the success rate of code execution, demonstrating its potential in tasks such as 3D point cloud classification.
Framework Overview
Dolphin's framework operates in a closed loop, mimicking the iterative nature of human scientific research (Figure 1).
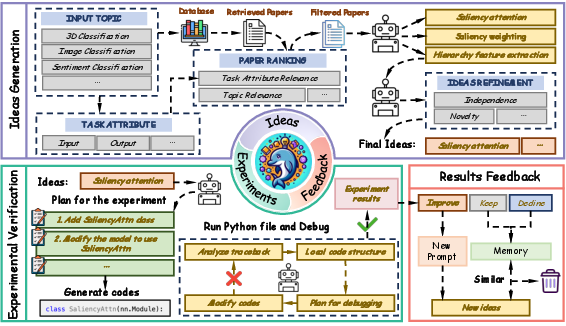
Figure 1: Dolphin generates ideas, conducts experiments, and analyzes results in a closed-loop framework.
The framework begins with retrieving relevant papers based on a given research topic. It then filters these papers by topic and task attribute relevance to ensure the generation of high-quality ideas. Following idea generation, Dolphin formulates experimental plans, generates code, and debugs using an error-traceback-guided debugging process. Finally, the experimental results are automatically analyzed and fed back into the idea generation phase to guide subsequent iterations.
Key Components and Methodologies
Idea Generation
Dolphin's idea generation process is designed to emulate human researchers by first conducting literature reviews and then formulating ideas based on the reviewed material. The process involves paper retrieval and ranking, followed by idea generation and filtering. Relevant papers are retrieved using the Semantic Scholar API and ranked based on their relevance to the input topic and the alignment of their task attributes. LLMs score papers, and those scoring below a threshold are discarded. Ideas are then generated by prompting an LLM to produce novel and non-redundant concepts, each including a title, experimental plan, and summary. The generated ideas undergo filtering to eliminate redundant or non-novel concepts. Independence is checked by extracting sentence-level embeddings and comparing cosine similarity with existing ideas stored in a bank, discarding ideas exceeding a similarity threshold. Novelty is assessed by prompting LLMs to determine if the idea is novel based on the searched papers.
Experimental Verification
Experimental verification is crucial for validating AI-generated ideas, which many existing studies lack. Dolphin generates detailed experimental plans and modifies reference codes accordingly. To improve the execution success rate, an exception-traceback-guided debugging process is employed. This process analyzes the local code structure related to the error-traceback to guide debugging. Dolphin extracts information from exception tracebacks, including function names, lines, and code, focusing on custom codes while excluding library function calls. The LLM generates the code structure under the guidance of this information and makes necessary modifications to enable automatic code execution (Figure 2).

Figure 2: Debugging is performed using traceback information to guide modifications to the local code structure.
This debugging process repeats until successful execution or a maximum number of attempts is reached.
Results Feedback
Dolphin analyzes experimental results, categorizing them as improvement, maintenance, or decline compared to reference codes. The system discourages ideas leading to stagnant or declining performance while promoting those that enhance model performance. Embeddings of summaries from ideas that maintain or improve performance are incorporated into an idea bank. Ideas are filtered out if they are similar to previous ineffective ideas, avoiding redundant verification. Performance-enhancing ideas are integrated into the idea generation prompt for subsequent loops.
Experimental Evaluation
The framework's effectiveness was evaluated on benchmark datasets such as ModelNet40, CIFAR-100, and SST-2, covering 2D image classification, 3D point cloud classification, and sentiment classification. Results show that Dolphin generates ideas that improve performance compared to baselines like PointNet, WideResNet, and BERT-base. For instance, Dolphin proposed methods based on PointNet achieved performance comparable to state-of-the-art 3D classification methods. Quality of generated ideas improved through feedback, validating the effectiveness of the closed-loop design.
Case Studies
Case studies highlight Dolphin's ability to generate effective ideas and corresponding code (Figure 3).

Figure 3: The case studies compare ideas and codes generated by Dolphin with those of human researchers.
One example involves a PointNet-based method that achieved an overall accuracy of 93.9% on ModelNet40, outperforming many human-designed methods and achieving comparable performance to state-of-the-art approaches like GPSFormer. Further analysis revealed that Dolphin's approach, PointNet-CSR, achieved better and faster performance than existing methods through a more concise architecture.
Conclusion
Dolphin presents a significant step toward automating scientific research by integrating idea generation, experimental verification, and results feedback in a closed-loop system. The framework's ability to generate effective ideas and improve performance on various tasks highlights its potential for advancing AI-driven scientific discovery. Future developments may involve enhancing code models, integrating multi-disciplinary knowledge, and developing more powerful code models for understanding and modifying project-level code.