- The paper introduces a multi-turn benchmark to evaluate RAG systems in realistic dialogue scenarios across diverse domains.
- It demonstrates that retrieval noise in multi-turn interactions significantly degrades the performance of both retrieval models and language generators.
- The study highlights a mismatch between automated metrics and human judgment, underscoring the need for more robust retrieval and generation strategies.
MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Introduction
In this paper, the authors introduce MTRAG, a novel multi-turn conversational benchmark designed to evaluate retrieval-augmented generation (RAG) systems more effectively. The benchmark addresses key challenges in evaluating RAG systems, particularly in scenarios involving multiple conversational turns where context and follow-up questions play pivotal roles. The study emphasizes the necessity for both strong retrieval mechanisms and adept generation capabilities, highlighting the limitations of state-of-the-art systems when confronted with complex conversational dynamics.
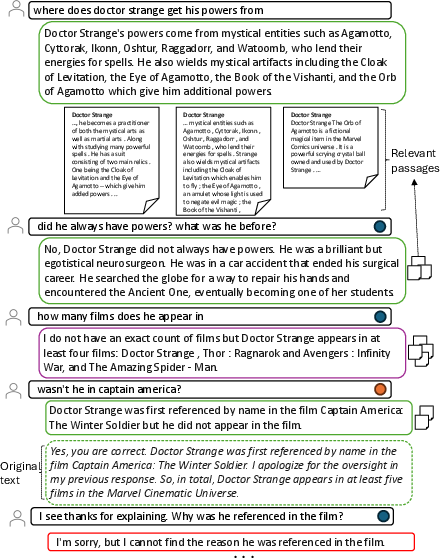
Figure 1: 5/8 turns of a conversation from the nq domain. The conversation is enriched with question dimensions, passage diversity, and repair.
Benchmark Design
MTRAG is structured around four diverse domains, encapsulating 110 conversations with an average of 7.7 turns per conversation. This setup results in a total of 842 tasks. The design focuses on several dimensions crucial for evaluating RAG systems: question types, multi-turn interactions, answerability, and domain variety. The benchmark employs human-generated conversations enhanced by live interactions with RAG agents, ensuring the realism and challenge of the tasks.
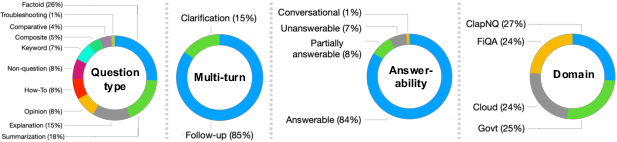
Figure 2: Distribution of tasks in mt based on each of the benchmark's dimensions.
The paper explores various retrieval strategies, emphasizing the complexity introduced by multi-turn conversations and non-standalone questions. Retrieval models like BM25, BGE-base, and Elser are evaluated, with the latter showing superior performance. The authors advocate for using query rewriting techniques to improve retrieval outcomes, particularly for non-standalone and contextually nuanced questions.
Generation Evaluation
Nine LLMs were tested on MTRAG, under different retrieval settings: Reference, Reference + RAG, and Full RAG. The study reveals consistent degradation in performance with increased retrieval noise and highlights significant challenges faced by models in handling unanswerable and multi-turn queries. The need for advancements in both faithful generation and retrieval-dense setups is evident.

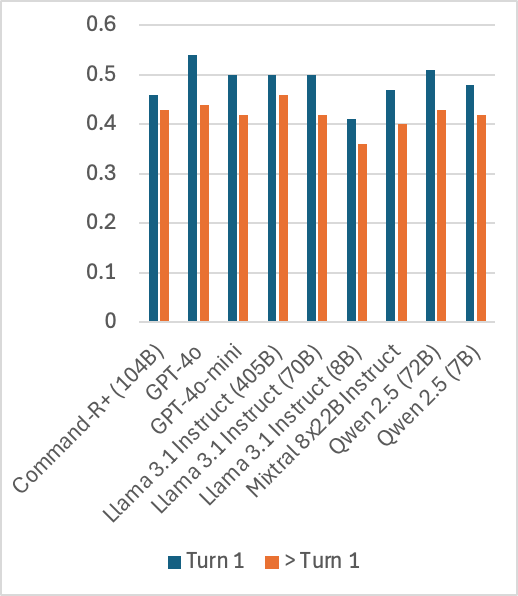
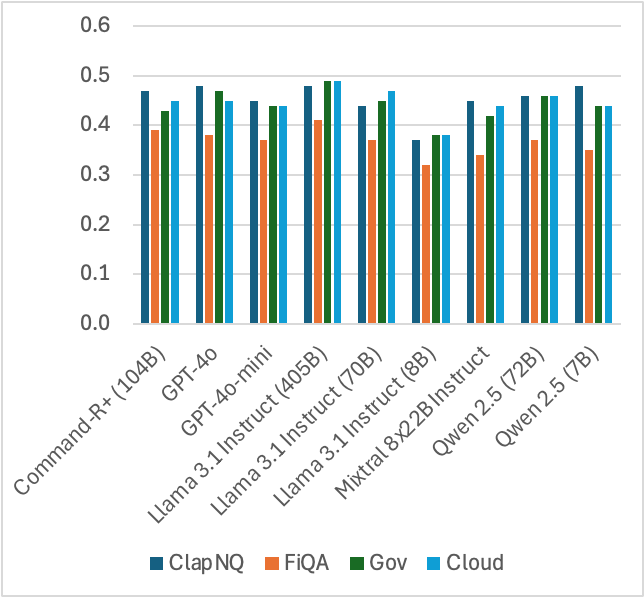
Figure 3: By question answerability.
Human and Automated Evaluations
Human evaluations corroborate the automated scores, demonstrating that LLMs frequently struggle with faithfulness and completeness in more challenging conversational scenarios. The study underscores the importance of developing metrics that align closely with human judgment, emphasizing a gap in current automated metrics for multi-turn settings.
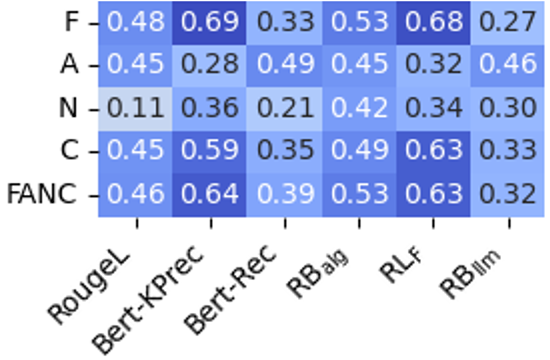
Figure 4: Weighted Spearman correlation of human evaluation with the automated metrics on the answerable subset for the GPT-4o and Llama 3.1 405B Inst. models.
Implications and Future Directions
The implications of MTRAG are substantial for researchers focused on conversational AI and RAG systems. By highlighting the difficulties LLMs face in maintaining conversational context and generating accurate, contextually aware responses, the paper sets a direction for future innovations aimed at improving retrieval methodologies and generation fidelity. The benchmark also opens avenues for exploring synthetic data generation, although initial findings suggest that human-generated data remains superior in complexity and depth.
Conclusion
MTRAG provides a comprehensive framework for assessing multi-turn RAG systems, demonstrating the need for further research in more robust retrieval mechanisms and generation strategies that handle context-rich interactions. By addressing the limitations inherent in current benchmarks, the study contributes significantly to the advancement of conversational AI, setting the stage for future development and innovation in the field.