- The paper introduces SewingLDM, a multimodal latent diffusion model that enhances garment pattern generation by integrating text prompts, sketches, and body shapes.
- The paper employs a two-step training strategy that first establishes a text-guided diffusion baseline and then fuses detailed garment sketches with body shape data.
- The model compresses complex sewing patterns into a compact latent space, enabling efficient reconstruction and superior adaptation to diverse garment details.
Multimodal Latent Diffusion Model for Complex Sewing Pattern Generation
Introduction
The paper "Multimodal Latent Diffusion Model for Complex Sewing Pattern Generation" addresses the challenge of generating complex sewing patterns that are simultaneously controlled by text prompts, body shapes, and garment sketches. These sewing patterns are crucial for applications in computer graphics (CG) pipelines due to their flexibility and compatibility with physical simulation and animation processes. Previous methods have struggled with intricate garment details and adaptability to various body shapes, creating a gap that this paper aims to fill with the proposed SewingLDM framework.
SewingLDM Architecture
The SewingLDM architecture introduces significant innovations to overcome limitations in previous models. The core of this architecture is a multimodal generative model that operates in two phases: representation enhancement and generation in a latent diffusion space.
- Enhanced Representation: Traditional sewing pattern representations are extended to incorporate detailed garment features. This includes additional edge types like cubic and circle lines, and attachment constraints that mimic real-world garment adjustments for better fitting and aesthetic appeal.
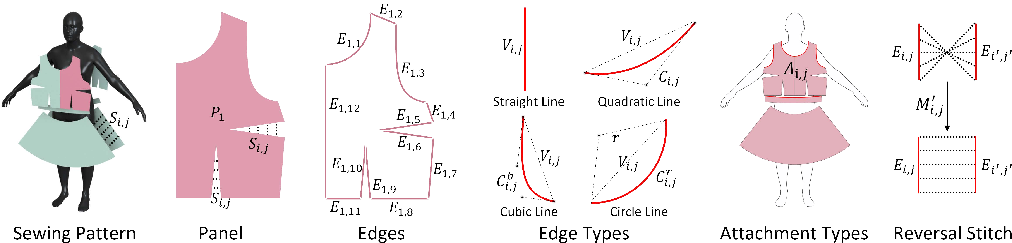
Figure 1: Sewing pattern. Sewing patterns are CAD representations of garments, containing 2D shapes and 3D placement of cloth. They consist of panels, and panels consist of edges joined from beginning to end. Between panels or inner panels, stitches are used to connect edges to form clothes.
- Latent Space Compression: The complex sewing patterns are compressed into a compact latent space using an autoencoder. This space is bounded and facilitates efficient training without excessive GPU consumption. The latency of the latent space is also meticulously quantized to enhance the reconstruction quality while keeping the computational demand manageable.
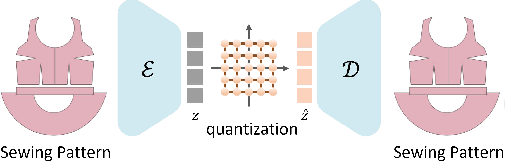
Figure 2: Sewing pattern compression. We compress the sewing pattern representations into a bound and compact latent space.
- Two-step Training Strategy: The training process is split into two distinct stages. Initially, a text-guided diffusion model is developed to establish a baseline semantic understanding. In the subsequent phase, detailed garment sketches and body shape data are incorporated into the model, enabling nuanced control of garment features and ensuring their suitability across diverse body types.
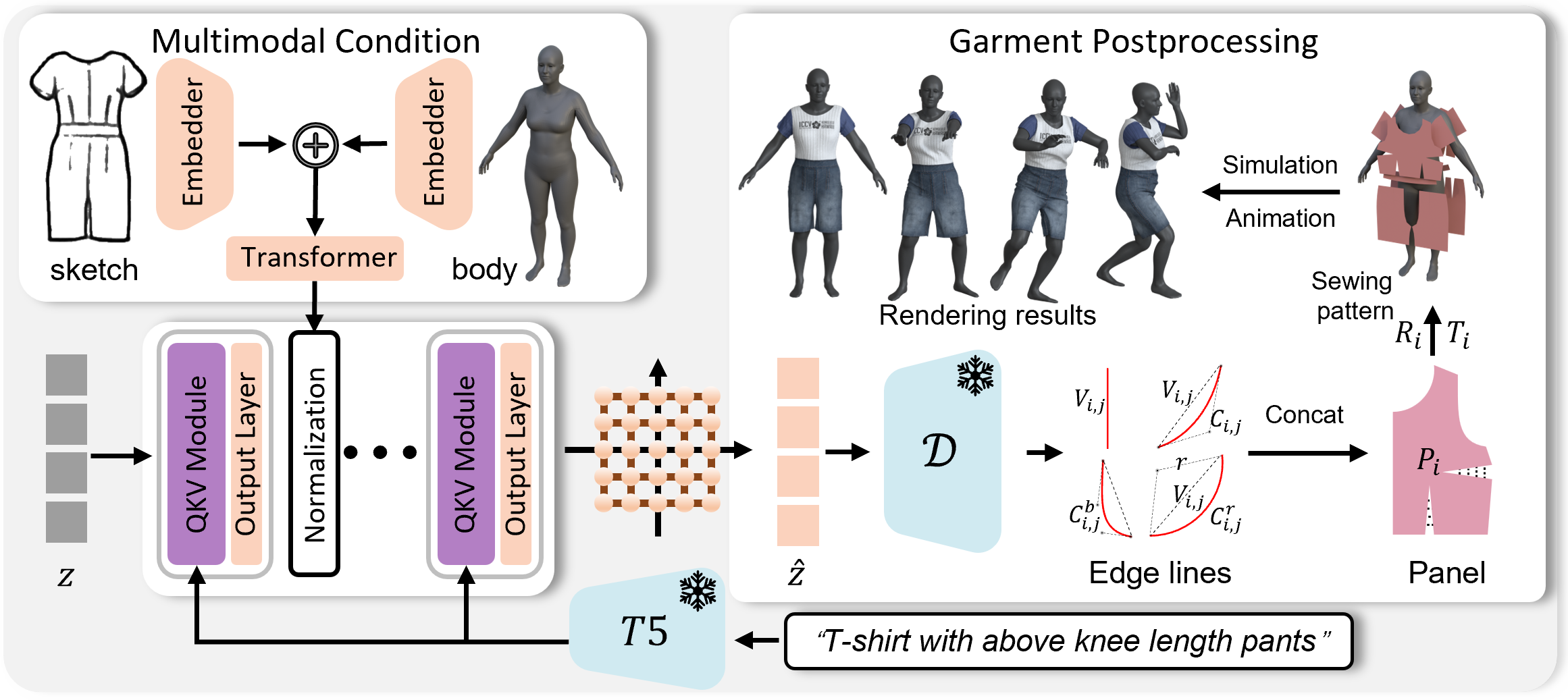
Figure 3: Multimodal latent diffusion model. After training the text-guided diffusion model, we fuse the features of sketches and body shapes, which are then normalized and integrated into the diffusion model.
Experimental Evaluation
The experimental results highlighted significant improvements in garment generation capabilities. Qualitative and quantitative analyses demonstrated that SewingLDM effectively outperformed state-of-the-art methods for both 3D mesh and pattern generation. Notable improvements were observed in:
- Visual Quality: The generated garments exhibited superior visual aesthetics and close fitting to diverse body types. This was evident in both controlled experiments and user studies comparing SewingLDM against contemporary mesh generation methods like Wonder3D.

Figure 4: Comparison with 3D mesh generation method. Our method successfully generates modern design garments with remarkable visual quality and close fitting to various body shapes.
- Complexity and Adaptability: The model's ability to generate complex designs aligned with user-provided sketches and text prompts for various body shapes was superior. In contrast, other methods struggled with adaptability and complexity, often failing to maintain fitting across different body shapes.

Figure 5: Comparison of sewing pattern generation for various body shapes. Our method can generate complicated sewing patterns aligned with sketch conditions and text prompts, draping on various body shapes effectively.
Ablation Studies and Limitations
The paper provides comprehensive ablation studies to illustrate the importance of each architectural component and training strategy. The two-step training strategy proved crucial for achieving balance in multimodal conditions, preventing failures seen in simpler one-step models. Although promising, limitations remain, particularly in generating garments with extremely intricate details such as bridal gowns with accessories. Future research could explore more sophisticated architectural alterations to expand the garment complexity the model can handle.
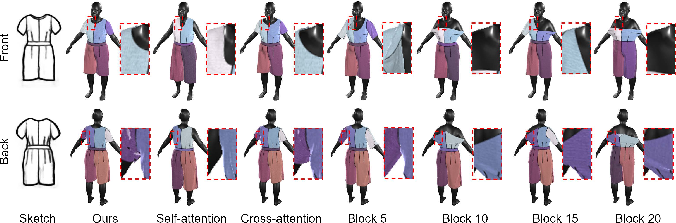
Figure 6: Ablation of the multi-modal condition. Experiments showed importance of training parameters on attention modules and the injection positions.

Figure 7: Limitations. Our method may struggle with intricate sketches such as bridal gowns.
Conclusion
The SewingLDM model represents a significant advancement in the domain of garment pattern generation, providing a robust framework for creating complex, body-adaptive garments under multimodal conditions. This work not only enriches the computational textile design landscape but also sets a foundation for integrating AI-driven models into fashion design and production. Further exploration into enhancing detailed garment features and addressing current limitations promises to expand the applicability of such models in various industrial and creative fields.

