- The paper demonstrates that using RPE enables transformers to reliably capture previous token information compared to APE.
- It develops an associative memory framework that balances in-context cues with global bigram knowledge for accurate next-token prediction.
- Experimental results validate that RPE improves length generalization and analogical reasoning in language models.
Rethinking Associative Memory Mechanism in Induction Head
This paper investigates the interplay between in-context information and pretrained knowledge within LLMs, with a specific focus on the induction head mechanism. By leveraging the theoretical framework of associative memory, the authors analyze how transformers process prompts generated from a bigram model, examining the conditions under which in-context knowledge is either overlooked or prioritized over global knowledge.
Theoretical Framework
The authors theoretically analyze a two-layer transformer architecture, focusing on the impact of positional encoding on the oversight of in-context knowledge. They demonstrate that transformers employing RPE can consistently attend to the preceding token, regardless of the input sequence length. This is contrasted with transformers using APE, where the learning of the previous token head can fail, leading to prediction errors, especially with longer sequences. The paper also introduces a three-layer transformer without positional encoding, showing that it can implement the induction head mechanism.
The authors define an associative memory transformer as a model incorporating an induction head and a feed-forward network storing pretrained knowledge. Through theoretical analysis, they explore how this model balances in-context knowledge and global knowledge when generating outputs. The analysis considers scenarios with limited input sequences and introduces the concept of a "stronger" associative memory transformer, characterized by weighted sums of individual terms in the weight matrices. This leads to the derivation of properties concerning the model's reliance on either global bigram knowledge or in-context knowledge, depending on the bigram conditionals and the frequency of token patterns in the context.
Experimental Validation
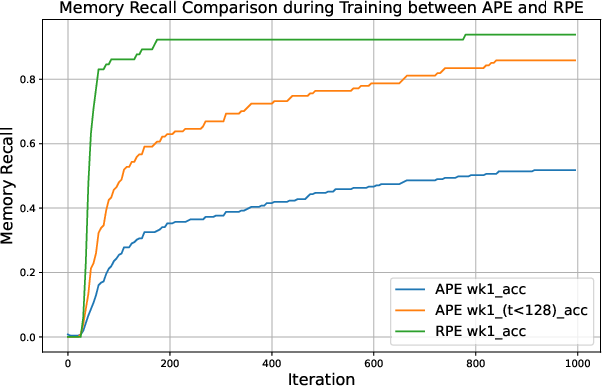
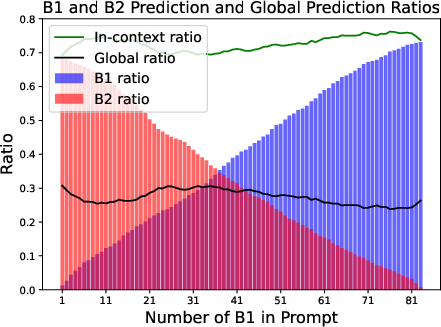
Figure 1: Comparison of a two-layer transformer with APE and RPE in capturing previous token information.
The theoretical results are validated through a series of experiments using both real and synthetic data. The first set of experiments investigates the training process of the previous token head, comparing transformers with APE and RPE. The results, shown in (Figure 1), indicate that TFRPE consistently attends to previous tokens, while TFAPE struggles to maintain attention over longer sequences.
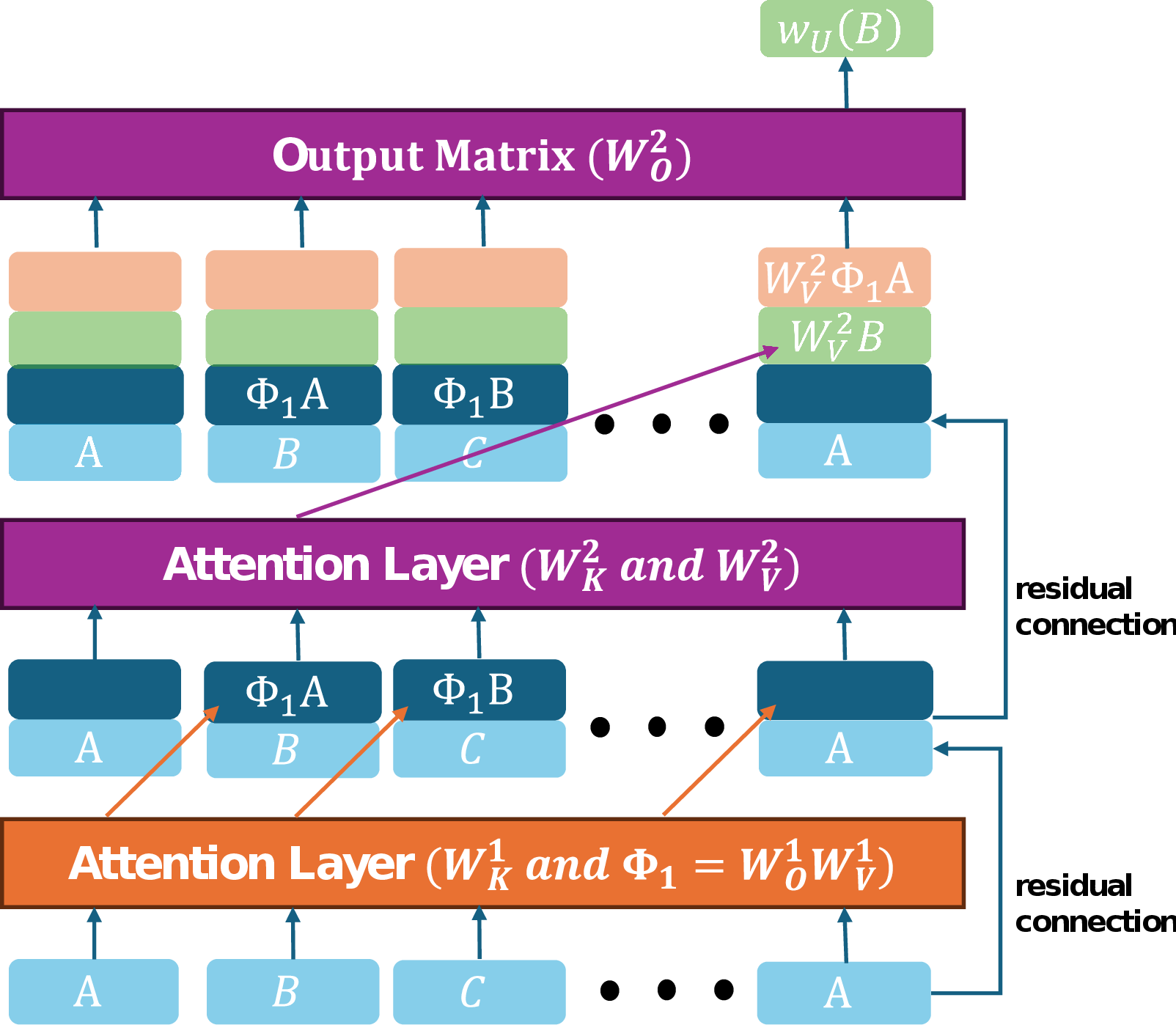
Figure 2: The visualization of induction head mechanism.
Another set of experiments focuses on the analogical reasoning task, using the "capital-world" analogy type of questions from the Google Analogy Dataset. The authors construct prompts using word pairs and train TFRPE to predict the next token. The results, displayed in (Figure 2), demonstrate that the model predicts either a token based on global knowledge or the token that appears in the context, consistent with the theoretical findings.
Implications and Future Directions
The research highlights the importance of relative positional encoding for length generalization in transformers and provides insights into how transformers balance in-context and global knowledge during next-token prediction. The findings have implications for the design and training of LLMs, suggesting strategies to improve their ability to leverage in-context information and avoid knowledge hijacking. Future research could extend the analysis to deeper transformers and explore the role of other mechanisms beyond induction heads in ICL.
Conclusion
This paper provides a comprehensive analysis of the interaction between global bigram knowledge and in-context knowledge in two-layer transformers, using the framework of associative memory. Through theoretical and experimental validation, the authors demonstrate the benefits of RPE for length generalization and shed light on the mechanisms underlying next-token prediction in transformers trained with global knowledge and induction heads.