Think before you speak: Training Language Models With Pause Tokens
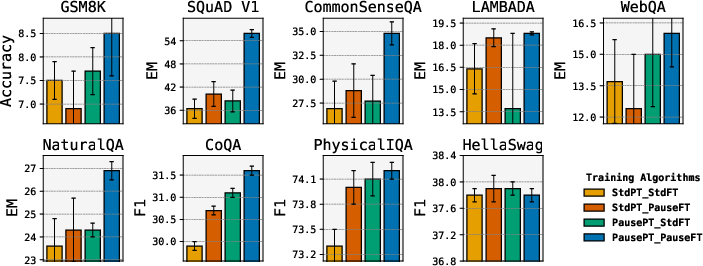
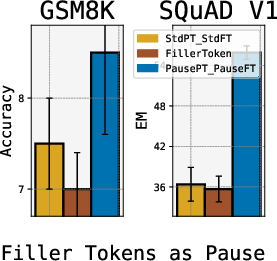
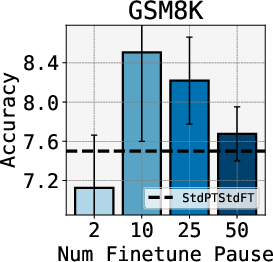
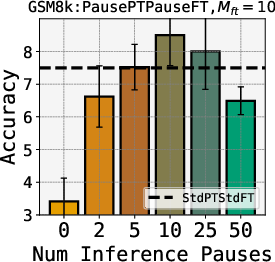
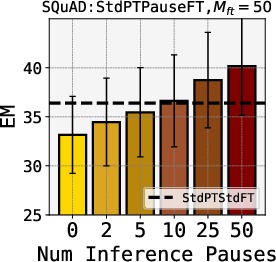
Abstract: LLMs generate responses by producing a series of tokens in immediate succession: the $(K+1){th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1){th}$ token? We operationalize this idea by performing training and inference on LLMs with a (learnable) $\textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $\textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18\%$ EM score on the QA task of SQuAD, $8\%$ on CommonSenseQA and $1\%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
- Rl4f: Generating natural language feedback with reinforcement learning for repairing model outputs. In Annual Meeting of the Association for Computational Linguistics, 2023. URL https://api.semanticscholar.org/CorpusID:258685337.
- Semantic parsing on Freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pp. 1533–1544, Seattle, Washington, USA, October 2013. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/D13-1160.
- Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence, 2020.
- Recurrent memory transformer. In NeurIPS, 2022.
- Memory transformer. arXiv preprint arXiv:2006.11527, 2020.
- Multi-cls bert: An efficient alternative to traditional ensembling, 2023.
- Training verifiers to solve math word problems, 2021.
- Vision transformers need registers, 2023.
- Bert: Pre-training of deep bidirectional transformers for language understanding, 2019.
- Critic: Large language models can self-correct with tool-interactive critiquing. ArXiv, abs/2305.11738, 2023. URL https://api.semanticscholar.org/CorpusID:258823123.
- WARP: Word-level Adversarial ReProgramming. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 4921–4933, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.381. URL https://aclanthology.org/2021.acl-long.381.
- Natural questions: a benchmark for question answering research. Transactions of the Association of Computational Linguistics, 2019.
- Learning to reason and memorize with self-notes, 2023.
- Measuring faithfulness in chain-of-thought reasoning, 2023.
- The power of scale for parameter-efficient prompt tuning, 2021.
- Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 4582–4597, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.353. URL https://aclanthology.org/2021.acl-long.353.
- Gpt understands, too, 2021.
- P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks, 2022.
- Yang Liu. Fine-tune bert for extractive summarization, 2019.
- Few-shot sequence learning with transformers, 2020.
- Text and patterns: For effective chain of thought, it takes two to tango, 2022.
- Self-refine: Iterative refinement with self-feedback, 2023.
- Show your work: Scratchpads for intermediate computation with language models, 2021.
- The lambada dataset: Word prediction requiring a broad discourse context, 2016.
- Learning how to ask: Querying LMs with mixtures of soft prompts. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5203–5212, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.410. URL https://aclanthology.org/2021.naacl-main.410.
- Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv e-prints, 2019.
- Squad: 100,000+ questions for machine comprehension of text, 2016.
- CoQA: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266, 2019. doi: 10.1162/tacl˙a˙00266. URL https://aclanthology.org/Q19-1016.
- It’s not just size that matters: Small language models are also few-shot learners, 2021.
- Challenging big-bench tasks and whether chain-of-thought can solve them, 2022.
- CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4149–4158, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1421. URL https://aclanthology.org/N19-1421.
- John Thickstun. The transformer model in equations. University of Washington: Seattle, WA, USA, 2021.
- Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting, 2023.
- Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, pp. 5998–6008, 2017.
- Towards understanding chain-of-thought prompting: An empirical study of what matters, 2023a.
- Self-consistency improves chain of thought reasoning in language models, 2023b.
- Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS, 2022.
- An embarrassingly simple model for dialogue relation extraction. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, may 2022. doi: 10.1109/icassp43922.2022.9747486. URL https://doi.org/10.1109%2Ficassp43922.2022.9747486.
- Tree of thoughts: Deliberate problem solving with large language models, 2023a.
- Retroformer: Retrospective large language agents with policy gradient optimization, 2023b.
- Star: Bootstrapping reasoning with reasoning, 2022.
- Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
- Factual probing is [MASK]: Learning vs. learning to recall. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5017–5033, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.398. URL https://aclanthology.org/2021.naacl-main.398.
- Least-to-most prompting enables complex reasoning in large language models, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.