- The paper identifies that super weights, a minimal set of LLM parameters, have a disproportionately large impact on model performance.
- It employs a data-free detection method using activation spikes in down_proj features to precisely map critical weights.
- The study demonstrates that preserving super weights improves quantization efficiency and overall accuracy, offering actionable insights for fine-tuning LLMs.
The Super Weight in LLMs
Introduction
The paper "The Super Weight in LLMs" presents a comprehensive investigation into the significance of specific parameters within LLMs that have a disproportionate impact on model quality. It introduces the concept of "super weights," a tiny subset of parameters whose pruning can catastrophically degrade the text generation capability of an LLM, and proposes a methodology for identifying these parameters with minimal computation. The study explores the origins and consequences of super weights and super activations, revealing their essential role in retaining model accuracy and facilitating quantization processes.

Figure 1: Super weights can completely destroy an LLM's text generation ability.
Super Weights and Their Identification
Super weights are found to be integral to model performance, although they comprise an exceedingly small fraction of the parameter space. The findings demonstrate that pruning just one super weight increases model perplexity drastically and reduces zero-shot accuracy to random guessing levels. This phenomenon contradicts the expectation that many weights would contribute evenly to model performance, highlighting the outsized role of super weights.
The identification of super weights is conducted via a data-free method, leveraging the detection of massive activation spikes in the "down_proj" feature across layers. This process requires only a single forward pass and provides a layer-specific map of super weights critical for model integrity.
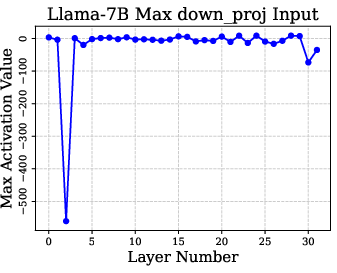
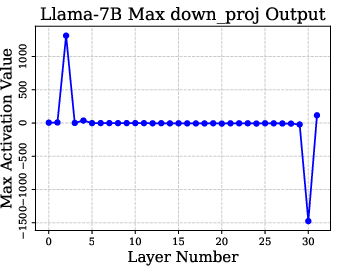
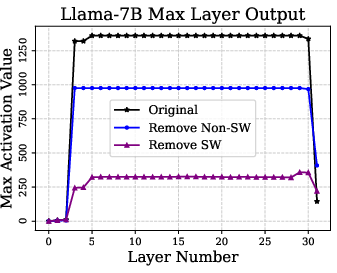
Figure 2: Visualization of activation input and output in down projection for detecting super weights.
Implications of Super Weights
Super weights are found to induce large-magnitude super activations, which propagate through the model, preserving the linguistic qualities essential for accurate text generation. When super weights are removed, these super activations are suppressed, subsequently altering token likelihoods—particularly amplifying stopword probabilities—and causing semantic disruption in model outputs.
Quantitatively, restoring super activations without super weights partially recovers model quality, indicating their combined importance. Amplifying super weights can further enhance accuracy, revealing an intriguing sensitivity that could be leveraged in fine-tuning strategies for improved performance.
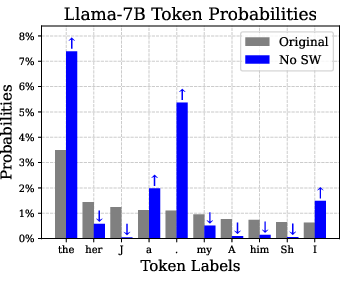
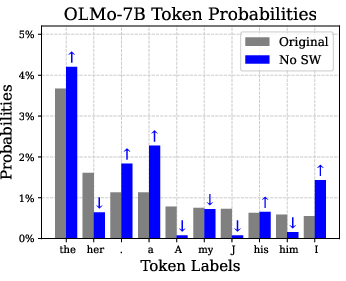
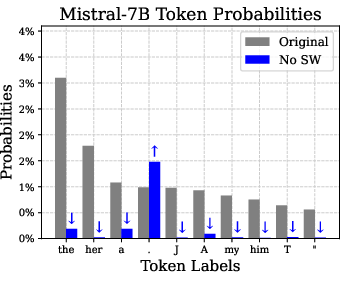
Figure 3: Removing super weights results in significantly increased stopword probabilities.
A pivotal contribution of this research is the enhancement of quantization algorithms by preserving super weights. Traditional quantization increases model efficiency but often sacrifices accuracy, commonly due to handling outliers. By recognizing and preserving super weights, the study proposes a novel quantization approach where only super weights affect the range calculations and are restored after quantization.
This method effectively competes with advanced quantization techniques like SmoothQuant, yet requires less complexity and no calibration data, representing a robust alternative especially beneficial for hardware constraints inherent in mobile and edge computing devices.
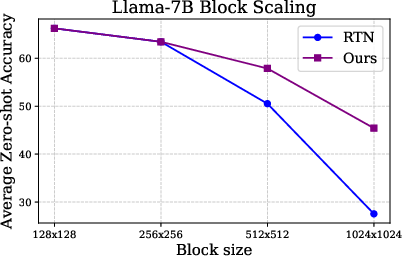
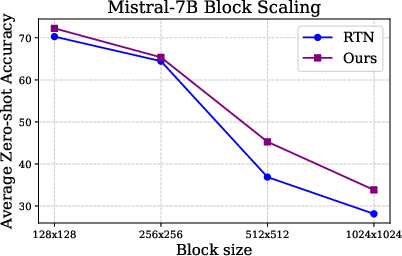
Figure 4: Super weight preservation allows more effective scaling of block sizes during quantization.
Conclusion
"The Super Weight in LLMs" articulates a significant advancement in understanding the internal dynamics of LLMs concerning sparse yet vital parameters. By identifying and managing super weights, the paper informs strategies not only for preserving model quality but also for optimizing computational efficiency through tailored quantization. It opens avenues for future research exploring deeper implications of parameter criticality and encourages adopting methodologies that leverage these insights for both theoretical exploration and practical application in AI model deployment.

