- The paper presents Distill-DKP, a novel framework that uses a depth-based teacher model to guide an RGB-based student model for improved human keypoint detection.
- It employs cross-modal knowledge distillation with cosine similarity loss, achieving significant reductions in keypoint localization errors across multiple datasets.
- Ablation studies confirm that late-layer distillation enhances the transfer of depth information, boosting accuracy in complex visual scenarios.
Depth-Guided Self-Supervised Human Keypoint Detection via Cross-Modal Distillation
The paper "Depth-Guided Self-Supervised Human Keypoint Detection via Cross-Modal Distillation" introduces a novel framework, Distill-DKP, which leverages depth maps in a self-supervised learning (SSL) setting to enhance human keypoint detection. This approach is set against the backdrop of contemporary challenges in keypoint detection, particularly in distinguishing foreground objects from structured backgrounds without the need for annotated datasets.
Introduction
The task of human keypoint detection is pivotal in computer vision applications such as human pose estimation and activity recognition. Traditional unsupervised methods that rely solely on 2D RGB images often struggle to distinguish keypoint locations due to the lack of depth information. The proposed Distill-DKP framework aims to overcome these limitations by implementing cross-modal knowledge distillation (KD) from depth maps to RGB images.
Distill-DKP includes a depth-based teacher model that guides an image-based student model, allowing the latter to inherit depth perception capabilities while using RGB images alone during inference. By distilling rich spatial information from depth maps, the student model achieves superior keypoint accuracy in complex scenarios where previous methods often falter.
Methodology
Distill-DKP employs a teacher-student setup where the teacher model is trained on depth maps generated by the MiDaS 3.1 model. These depth maps are critical in providing a structural hierarchy that emphasizes foreground features while suppressing background noise. The student model, on the other hand, operates on RGB images and learns from the depth-derived embeddings using KD.
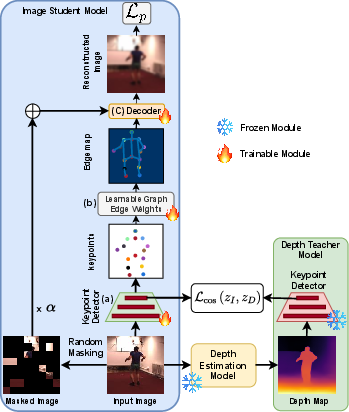
Figure 1: Distill-DKP Framework. The Image student model is trained with knowledge distilled from depth-based teacher model output.
AutoLink Integration
The framework integrates the AutoLink SSL approach, which models keypoints as a graph, connecting points (nodes) with learnable edges. Keypoint detection in AutoLink is facilitated by a keypoint detector using a ResNet architecture, combined with edge map generation to reliably connect keypoints.
Cross-modal KD is applied through cosine similarity loss between teacher and student model embeddings. This approach allows the student model to grasp depth insights directly from the teacher's learned representation, significantly improving upon simple 2D-based methods.
Experiments
The efficacy of Distill-DKP is demonstrated through comprehensive evaluations across the Human3.6M, DeepFashion, and Taichi datasets. The key metric improvements include a 27.8% reduction in mean L2 error on Human3.6M, a 1.3% gain in keypoint accuracy on DeepFashion, and a 5.67% lower Mean Average Error (MAE) on Taichi.

Figure 2: Qualitative comparison showing the improved keypoint localization of Distill-DKP in different datasets.
These results underscore not only the robustness of depth-guided learning in capturing intricate spatial details but also its viability as an unsupervised learning framework for keypoint detection.
Analysis and Ablation Studies
In-depth ablation studies reveal that late-layer distillation consistently outperforms early-layer KD in terms of overall accuracy. The study demonstrates that focusing KD efforts on the later stages of the network leads to better knowledge transfer, particularly in datasets with complex backgrounds.
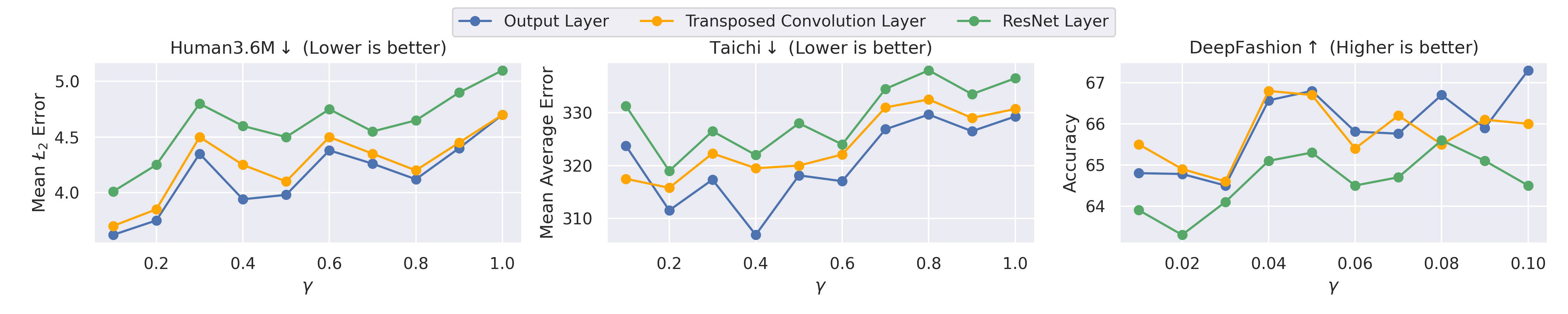
Figure 3: KD sensitivity plots across different layers and gamma settings, indicating optimal performance with output layer distillation.
The results suggest that while depth maps provide critical structural insights, the student model maintains this understanding even when solely working with RGB images during the inference phase.
Conclusion
Distill-DKP establishes a noteworthy advancement in self-supervised human keypoint detection by harnessing depth information through cross-modal distillation. This approach effectively handles scenarios involving intricate background challenges without relying on labeled data. Future work can explore extending this framework to 3D keypoint detection and further enhancing keypoint localization in heavily occluded environments. The success of Distill-DKP in various datasets highlights its potential for broad application in computer vision tasks where distinguishing foreground from background is essential.

