- The paper demonstrates that only 77.9% of the gold answers match the highest plausibility ratings, highlighting significant semantic misalignments.
- The methodology involved sampling 250 MCQs and collecting 5,000 Likert-scale judgments to assess answer plausibility against benchmark labels.
- Results imply that ambiguous benchmarks may introduce evaluation noise for LLMs, underscoring the need for refined, semantically aligned datasets.
Plausibly Problematic Questions in Multiple-Choice Benchmarks for Commonsense Reasoning
Introduction
The paper examines the reliability of multiple-choice question (MCQ) benchmarks in commonsense reasoning by analyzing independent plausibility judgments on such answer choices. By scrutinizing two specific datasets, Social IQa and CommonsenseQA, the study identifies a significant subset of items where the most plausible answers as rated by humans do not align with the benchmark's gold label answers, revealing problems of ambiguity and semantic mismatch.
Methodology
The study employs the following methodologies to explore the issue:
- Sampling and Annotation: 250 MCQ items were sampled, collecting 5,000 plausibility judgments across these samples.
- Human Data Collection: Utilizing a Likert-scale for plausibility ratings, annotators independently rated each answer choice, allowing for a comparison with the original gold answers.
- Comparison Criteria: The analysis compared three definitions of a "correct" answer: original gold answers, majority-vote once all answers provided, and answer choice with the highest mean plausibility rating.
Multiple figures are instrumental in illustrating key points, such as mean Likert scores, error analysis frequencies, and model performance correlations.
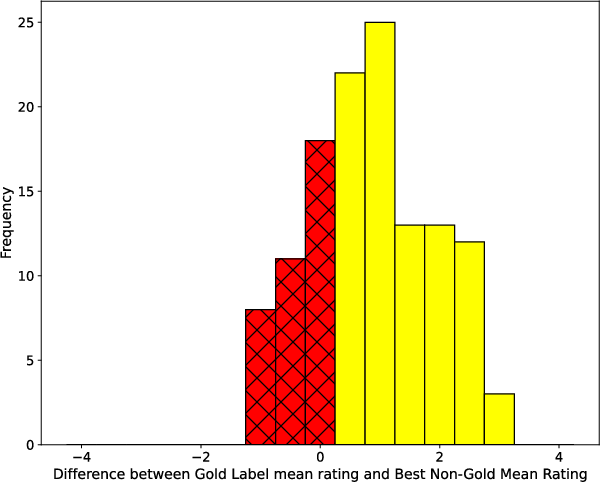
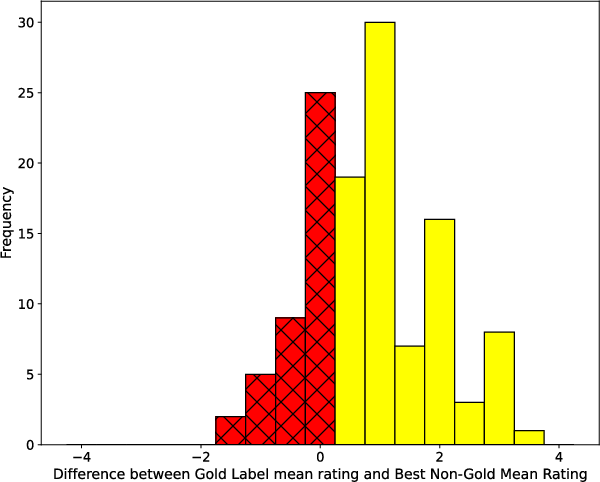
Figure 1: Social IQa showcases a question where the most plausible answer did not match the gold label.
Results
The results showed:
Implications for AI and LLM Evaluation
The findings have implications for AI model evaluation:
- LLM performance is highly variable on these problematic sets, indicating these benchmarks could introduce noise.
- Human annotators identified ambiguity and semantic mismatches effectively providing qualitative insights missed by LLMs.
Advanced LLM models show a significant performance drop on these problematic subsets, suggesting they offer limited reliability for grounding AI capabilities in commonsense reasoning.

Figure 3: In-context learning examples from Social IQa for isolated settings.
Conclusion
The paper provides a basis for improving commonsense MCQ benchmarks. Future works should integrate plausibility judgments into benchmark creation, ensuring questions are clear and answers are semantically aligned. This will aid in developing benchmarks that accurately assess the commonsense reasoning capabilities of AI models.
Future Directions
Additional research could investigate enhancing dataset creation strategies to ensure alignment in MCQ benchmarks. Incorporating "None of the above" options could also mitigate issues where questions may not align with plausible answers.
By refining these methodologies, commonsense AI evaluations can become more robust, ensuring models are correctly assessed on their intended reasoning capabilities.


