- The paper demonstrates that high duplicate rates can artificially inflate performance metrics, notably F1 scores.
- It employs metrics like Levenshtein Distance to systematically identify duplicates and near-duplicates across 20 social media datasets.
- The study recommends proactive deduplication methods during dataset preparation to ensure more reliable computational social science research.
Enhancing Data Quality through Simple De-duplication: Navigating Responsible Computational Social Science Research
Introduction
The study addresses the critical issue of data duplication in NLP datasets used for Computational Social Science (CSS) research. By analyzing 20 such datasets, the study identifies data duplication as a pivotal factor that could introduce noise, leading to label inconsistencies and data leakage. The research indicates that duplication may falsely inflate the perceived performance of state-of-the-art models, thereby impacting their reliability in practical scenarios.
Methodology and Key Findings
A systematic reevaluation was performed on 20 social media datasets used across several CSS tasks such as offensive language detection and misinformation detection. The key objectives included assessing the prevalence of duplicate and near-duplicate samples and understanding their impact on model performance. The study utilized metrics such as Levenshtein Distance to identify near-duplicate samples, and various experiments were conducted to understand the impact on F1 scores and accuracy.
Duplicate and Near-Duplicate Impacts
The study systematically evaluated the datasets to reveal a widespread presence of duplicates.
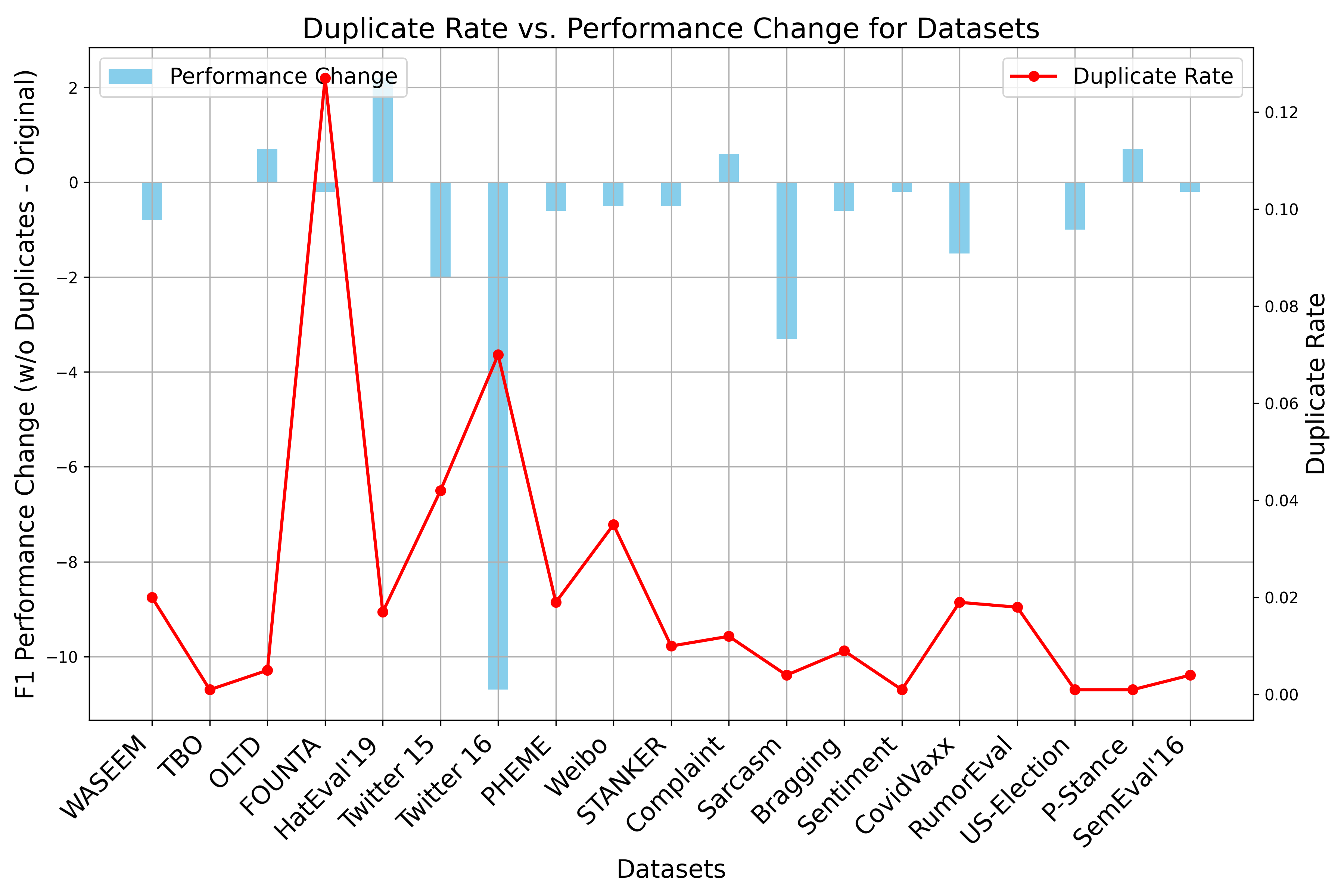
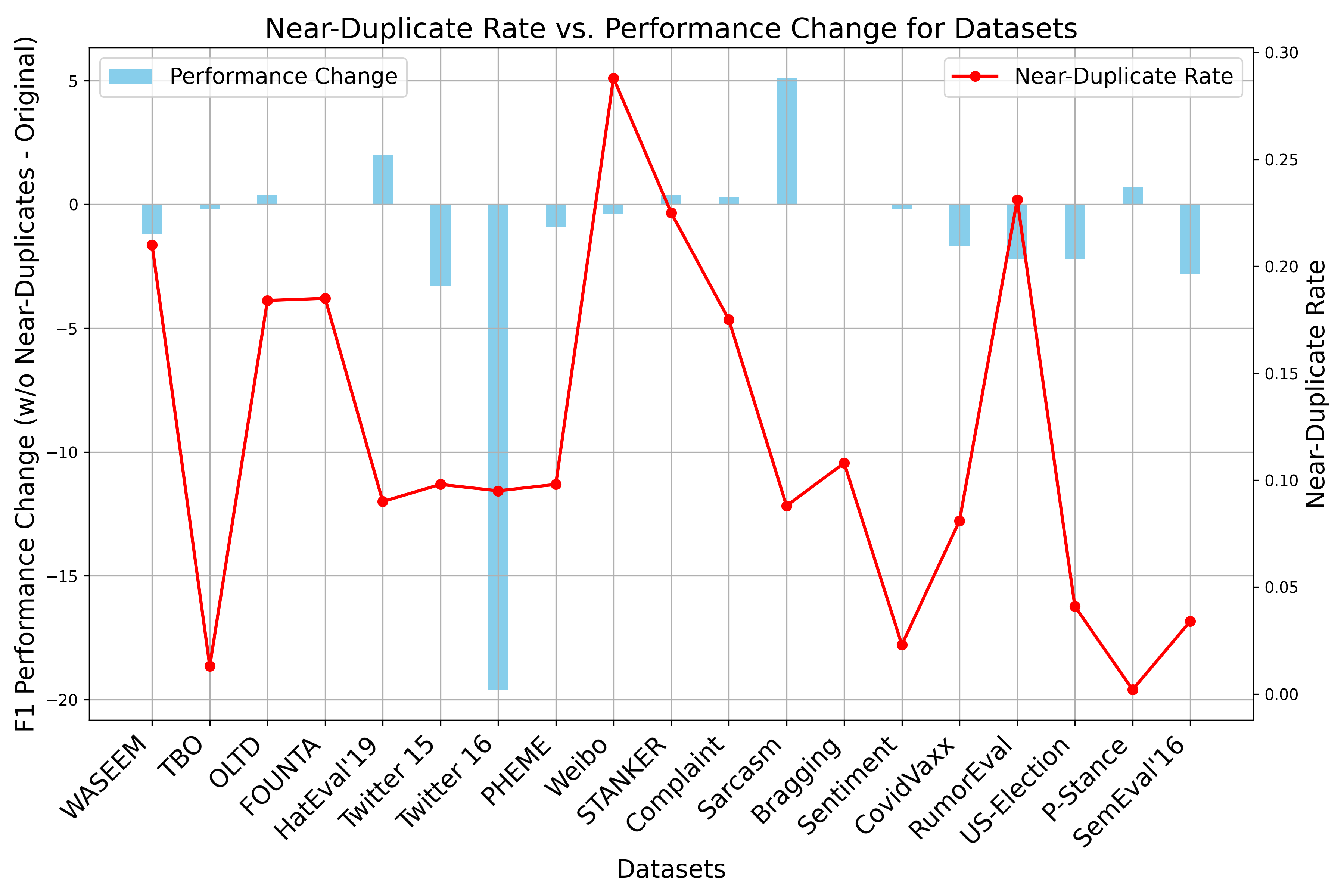
Figure 1: Duplicate (left) and Near-Duplicate (right) rates against performance changes in F1 scores. The positive values on the left y-axis (performance change) indicate improvement, whereas negative values suggest decline.
This comprehensive analysis indicated that the majority of datasets contained duplicates despite the data cleaning processes claimed by the original dataset creators. The research highlighted that high duplication rates correlate with inflated F1 score measurements, indicative of overestimated model performance.
Moreover, the presence of duplicates leads to label inconsistencies which can affect model training significantly. In scenarios where duplicates were removed, a reduction in model performance was noted across various datasets, supporting the hypothesis that duplications artificially enhance performance metrics.
Error Analysis
An additional layer of analysis was conducted to evaluate the specific implications of duplicate samples on misinformation detection tasks.
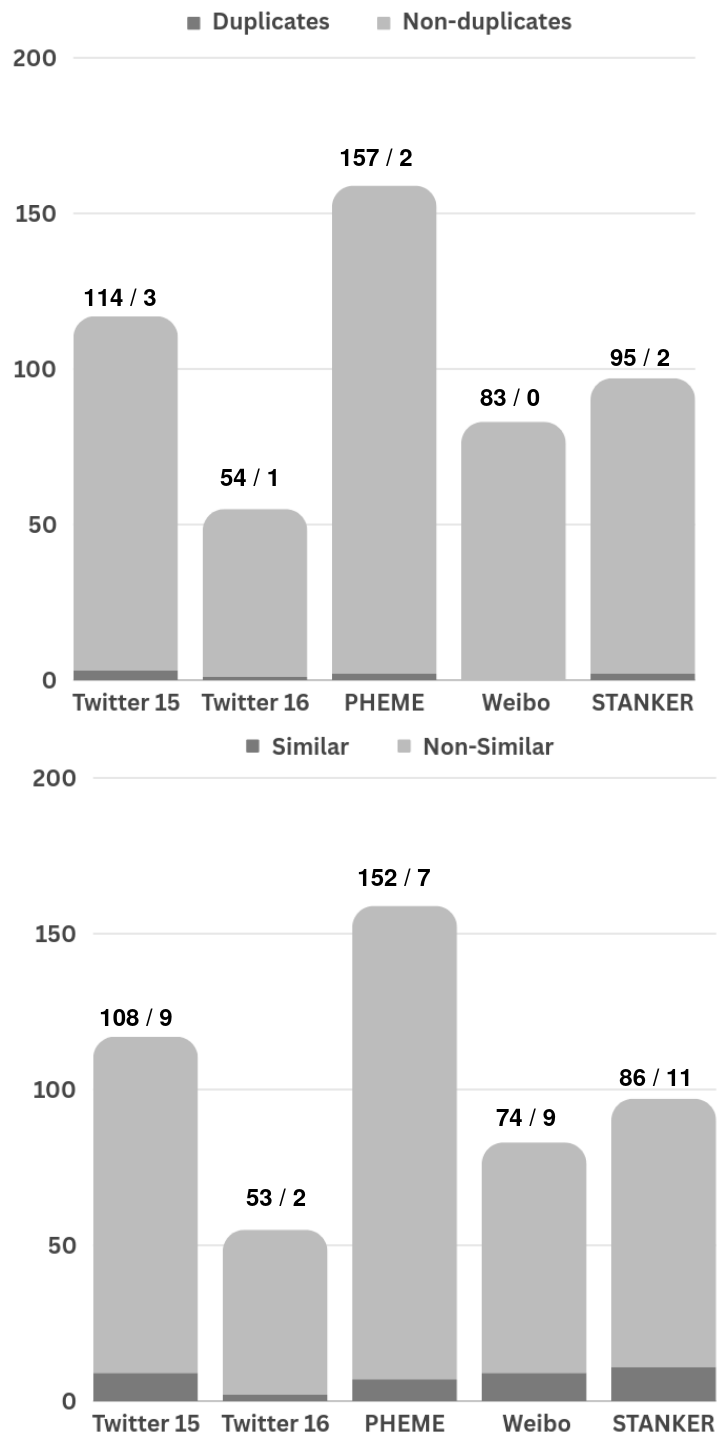
Figure 2: Ratio of duplicates (upper) and near-duplicates (bottom) in wrong predictions from five misinformation detection datasets.
The error analysis revealed a pronounced overestimation of performance metrics when duplicates were present in both the training and test datasets. It underscored that duplicate instances managed to obscure the real challenges contained within these datasets, giving rise to erroneous model evaluations.
Recommendations for Dataset Development
The study proposes strategic recommendations for enhancing dataset quality to ensure more responsible CSS research. These include:
- Pre-Annotation Deduplication: Conduct initial data cleaning, including deduplication before annotation tasks, thereby reducing cost and avoiding inconsistent labeling.
- Dual Versions of Datasets: Maintain datasets with and without near-duplicates to accommodate varying research needs.
- Enhanced Checklist Practices: Advocate for the inclusion of data deduplication processes in ethical and data management checklists used during dataset preparation.
Theoretical and Practical Implications
The findings hold significant implications both theoretically and practically. Theoretically, they encourage a reevaluation of existing dataset preparation norms and urge the academic community to adopt more rigorous practices. Practically, the insights provided can guide future dataset creators in developing more robust, reliable resources that improve CSS model reliability and applicability.
Conclusion
The paper provides a critical examination of the current state of data quality in NLP datasets for CSS and highlights the pervasive yet overlooked issue of data duplication. It offers actionable strategies for data curation and underscores the importance of methodological rigor in dataset preparation. This research is a call for more responsible and informed dataset management practices, emphasizing the significant impact even simple deduplication can have on the field of computational social science.