- The paper presents LLM-Pilot, a system that benchmarks and optimizes LLM inference services across diverse GPU setups.
- It employs a realistic workload generator using production traces to simulate inference requests and fine-tune configuration parameters.
- Leveraging an XGBoost regressor, the tool achieves a 33% improvement in performance adherence and a 60% reduction in deployment costs.
The paper "LLM-Pilot: Characterize and Optimize Performance of your LLM Inference Services" introduces a system designed to optimize the deployment of LLMs by characterizing their performance across various GPUs and recommending efficient deployment strategies. The work addresses a critical challenge in modern AI: deploying expansive LLMs in a cost-effective manner while meeting performance requirements. This essay explores the LLM-Pilot's architecture, functionality, and implications.
Introduction to LLM-Pilot
LLM-Pilot is a system aimed at benchmarking and optimizing the deployment of LLM inference services across heterogeneous GPU environments. The tool comprises two core components: the performance characterization tool and the GPU recommendation tool. The characterization tool benchmarks LLMs under realistic workloads using a novel workload generator, optimizing configuration parameters such as the maximum batch weight to enhance performance.
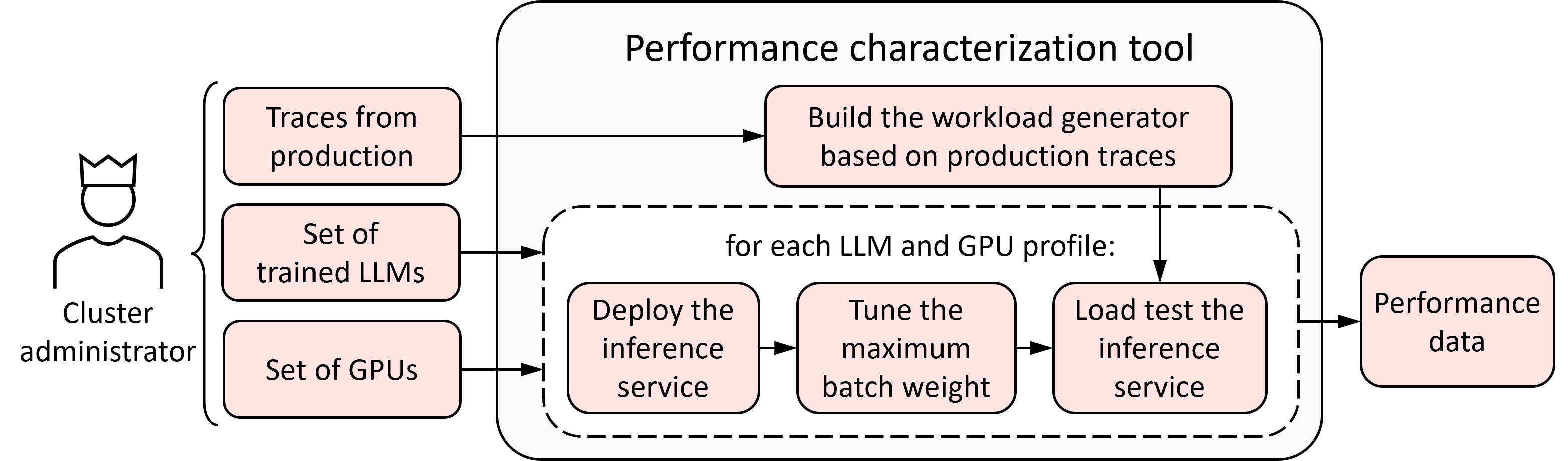
Figure 1: Architecture of the performance characterization tool.
The GPU recommendation tool employs predictive modeling to recommend the most cost-effective GPU setup for deploying a given LLM, ensuring it meets specific performance SLAs. It predicts latency metrics using a regression model trained on characterization data, maximizing performance predictions where it matters most near SLA constraints.
One of the foundational elements of LLM-Pilot is its workload generator, which models real-world LLM usage by analyzing production traces. This generator incorporates correlated request parameters, preserving statistical features critical to accurately reflecting inference workload distributions.
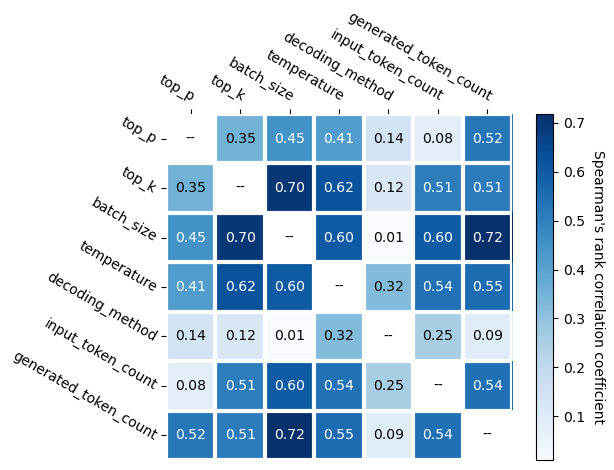
Figure 2: Correlation between selected parameters of requests from the production traces.
These traces include over 17 million requests and incorporate complex parameters impacting LLM performance, such as input/output tokens and batch sizes. The generator’s efficiency and accuracy are critical for realistic benchmarking, reducing reliance on large trace datasets and speeding up simulation time.
The GPU recommendation tool leverages a predictive model to evaluate the required computational resources for new LLM deployments. It employs an XGBoost regressor, enhanced with constraints and weight adjustments to prioritize predictions near SLA boundaries, thereby focusing on deployment scenarios critical to operational success.
The recommendation process considers both the hardware configuration and expected workload, efficiently determining a deployment strategy that balances performance and cost. This method has shown a 33% improvement in meeting performance requirements with a 60% reduction in costs over existing methods.
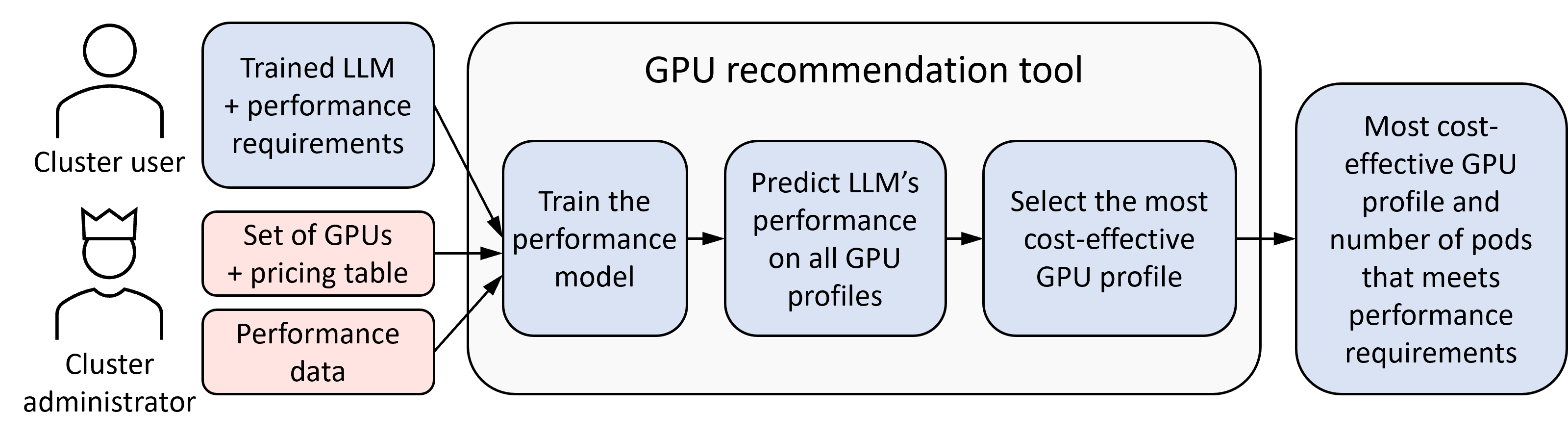
Figure 3: Architecture of the GPU recommendation tool.
Evaluation and Results
LLM-Pilot’s evaluation involved benchmarking multiple LLMs across diverse GPU setups, demonstrating its ability to significantly enhance deployment recommendations. The system outperformed several baselines, effectively balancing the trade-offs between cost and performance.
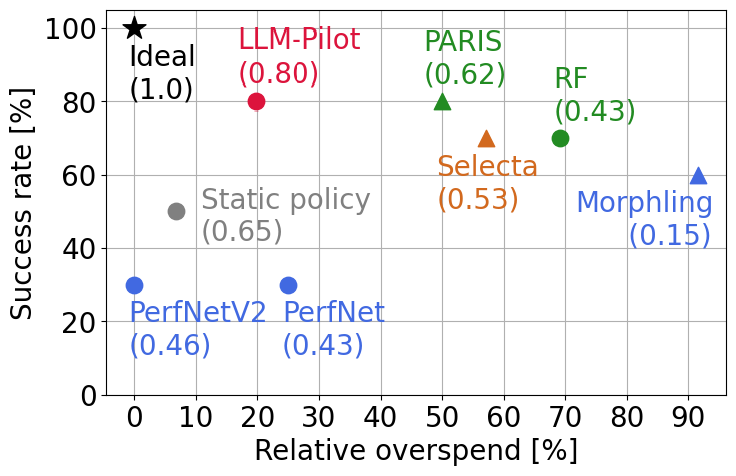
Figure 4: Evaluation of the quality of recommendations made by LLM-Pilot and baselines. Numbers in parentheses present the S/O scores achieved by each method. We mark methods which make reference performance measurements using ▲, and methods which make no reference evaluations with $\CIRCLE$. Additionally, ★ marks the theoretical ideal performance.
The tool's predictive accuracy is bolstered by comprehensive data collection and feature engineering, with performance measured in terms of latency metrics such as TTFT and ITL. These metrics are crucial to understanding the real-world performance potential of LLM deployments.
Implications and Future Work
By addressing the complexities of LLM deployment, LLM-Pilot facilitates the effective utilization of GPU clusters, which is pivotal given the growing computational demands of state-of-the-art LLMs. The tool supports informed decision-making for deploying these models in cost-efficient and performant manners.
Future work could extend LLM-Pilot to multi-tenant environments, further optimizing resource sharing among concurrent LLM deployments. Additionally, integrating real-time performance feedback could refine recommendation accuracy and address dynamic computational environments more effectively.
Conclusion
LLM-Pilot represents a significant advancement in the characterization and optimization of LLM inference services. Its unique combination of benchmarking and predictive modeling offers a comprehensive solution for deploying LLMs efficiently. As AI models continue to grow in size and complexity, tools like LLM-Pilot will become increasingly essential for optimizing performance and managing infrastructural costs in AI deployments.