- The paper introduces SEAT, a novel embedding-based scheduling method that accurately predicts per-token output length for efficient LLM inference.
- It achieves a 2.66x reduction in mean absolute error through iterative Bayesian smoothing and optimal layer profiling of transformer embeddings.
- Adaptive SRPT scheduling with controlled preemption reduces mean response time by up to 2x and improves time-to-first-token by as much as 24x in burst scenarios.
Motivation and Background
LLM inference serving systems increasingly underpin interactive AI applications, placing stringent demands on request completion time and necessitating highly efficient resource scheduling. Classical FCFS policies, widely adopted in LLM serving (e.g., vLLM, Orca), induce head-of-line blocking, particularly under heterogeneous prompt and response length distributions. Size-aware scheduling algorithms, notably SRPT and its variants, minimize mean response time by prioritizing requests with the smallest remaining execution time, but their deployment in LLM inference faces two key challenges: (i) lack of accurate, efficient output length prediction and (ii) substantial KV-cache memory overheads incurred by preemptive token-level scheduling.
Traditional prompt-based predictors (e.g., BERT), as well as approaches leveraging separate lightweight LLMs, either suffer from limited accuracy or introduce prohibitive prediction overheads, constraining their practicality for real-time service optimization. The work introduces SEAT (Scheduling with Embeddings for Adaptive Tokens), an architecture capitalizing on the autoregressive, iterative nature of LLM inference to enable highly accurate, low-overhead per-token length prediction and adaptive scheduling.
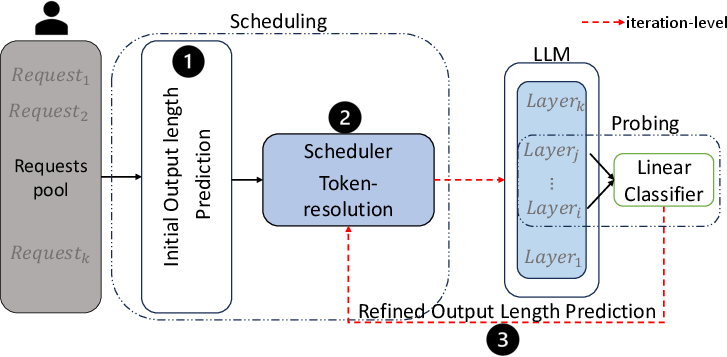
Figure 1: SEAT architecture combines prompt-based ordering, SPRPT with limited preemption, and on-the-fly refinement via probing the LLM’s own internal layer embeddings.
Embedding-Based Output Length Prediction
SEAT leverages a probing framework on the internal transformer layer embeddings of the serving LLM itself, obviating the need for any auxiliary prediction model. At each decoding iteration, the embedding (primarily layer 11 as identified via profiling) is fed to a lightweight linear classifier which infers the expected remaining output length in a binned format. The prediction is recursively refined via Bayesian smoothing, with transition matrices encoding the bin migration likelihood as the output sequence evolves—a methodology aligned with token-level autoregressive generation mechanics.
Layer-wise accuracy profiling on LLama3-8b-instruct models demonstrates a clear performance peak at layers 10–15 for length prediction.
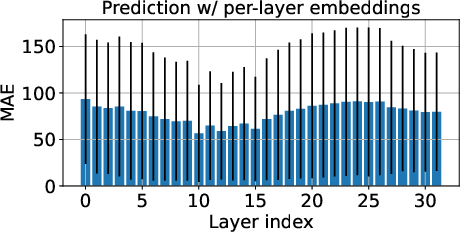
Figure 2: MAE for output length prediction as a function of transformer layer index, demonstrating optimality in mid-to-high layers.
Subsequent results show that real-time refinement of length prediction using these embeddings significantly decreases error. Comparative evaluation evidences a 2.66x reduction in mean absolute error (MAE) relative to BERT-prompts, and further iterative smoothing yields additional improvement.
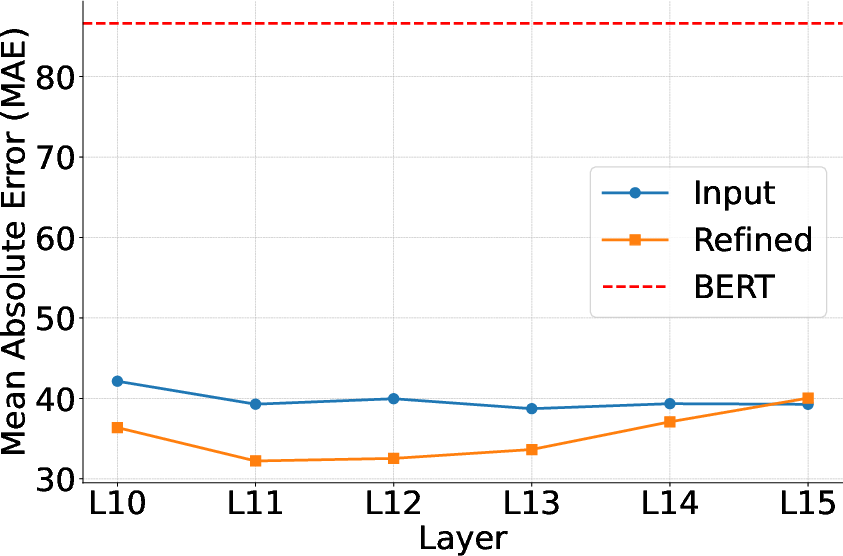
Figure 3: MAE comparison between BERT input embeddings, token embeddings without refinement, and iteration-level refinement at various internal layers.
This refined prediction is not only highly accurate but also introduces negligible inferential overhead—below 0.03% of total compute—and can be executed either on-GPU or offloaded to CPU during decoding for concurrent execution.
Adaptive SRPT Scheduling with Limited Preemption
SEAT employs an SRPT-style scheduling policy with strictly controlled preemption to accommodate memory constraints imposed by LLM KV-cache accumulation. Preemption is only permitted during the initial fraction (parameterized by C) of a request’s predicted execution, which limits the proliferation of unfinished requests and KV-cache utilization. This policy harmonizes scheduling latency optimization with hardware memory caps, yielding analytically tractable queue behavior.
A closed-form expression for mean response time in an M/G/1 model under limited preemption SRPT is derived, capturing dependence on prediction error distributions and system arrival rates. Simulation and empirical measurements suggest that judicious preemption restricting (e.g., C=0.8) optimally balances latency and memory consumption, with performance heavily tied to prediction accuracy.
Prediction Accuracy Analysis
Heatmap analysis comparing refined embedding-based prediction to prompt-only (BERT) predictions clearly demonstrates diagonal dominance for embeddings, indicating robust alignment between predicted and actual output length bins throughout token generation stages, while BERT predictions are diffused and exhibit greater deviation.
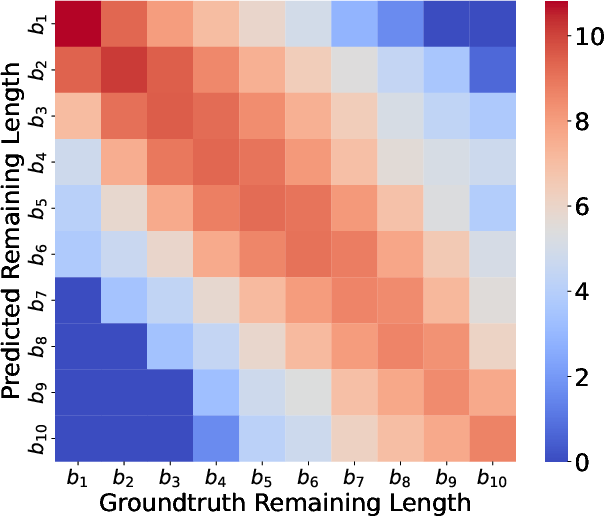
Figure 4: Log-scale heatmap showing bin-wise concordance between ground-truth and embedding-based predicted remaining output lengths during iterative decoding.
Empirical Evaluation
Integrating SEAT into vLLM yields substantial reductions in user-perceived latency metrics on real-world workloads (Alpaca dataset). With iteration-level refinement and limited preemption scheduling:
- Mean latency is decreased by 1.66x–2.01x over vanilla vLLM FCFS scheduling.
- Time to first token (TTFT) improves by 1.76x–24.07x relative to standard serving systems.
Performance gains are maximized under high-load and burst scenarios, and are resilient across a wide range of C parameterizations, confirming the advantage of limited preemption aligned with memory constraints.
Practical and Theoretical Implications
The combination of embedding-based length prediction and adaptive preemption scheduling is shown to directly address the resource bottlenecks inherent in current LLM serving architectures. SEAT enables fine-grained, real-time batch adjustments, minimizes head-of-line blocking, and preserves GPU memory integrity in high-throughput deployments. The framework is amenable to further generalization, including multi-layer ensemble probing, dataset- and model-specific adaptation, and dynamic online retraining for distributional drift mitigation.
From a queueing theory perspective, the extension of SRPT to realistic, resource-limited LLM serving environments and the integration of refined, within-sequence prediction opens pathways for future analytical developments, including multi-server and distributed inference settings.
Conclusion
SEAT introduces a robust embedding-based scheduling methodology for LLM inference, leveraging the structure and iterative computation of Transformer architectures to deliver highly accurate, low-overhead output length prediction and efficient preemptive scheduling. The approach substantially lowers mean response time and TTFT under practical operating conditions, outperforming extant state-of-the-art systems in both standard and burst load scenarios. Further investigation into layer selection, ensemble methods, interval-based prediction, and adaptive retraining could enhance both generalizability and performance, establishing embedding probing as a versatile tool for dynamic property inference in LLM serving pipelines (2410.01035).

