- The paper introduces the PagedAttention algorithm that employs block-based, noncontiguous KV cache allocation to minimize fragmentation in LLM serving.
- It demonstrates a 2-4× improvement in serving throughput over existing systems using GPU parallelism and dynamic memory sharing.
- The vLLM system achieves scalable and cost-effective large language model deployment by reducing memory waste and adapting allocation to actual request needs.
Efficient Memory Management for LLM Serving with PagedAttention
Introduction
The paper "Efficient Memory Management for LLM Serving with PagedAttention" (2309.06180) addresses the challenges in serving LLMs by proposing the PagedAttention algorithm. Inspired by traditional virtual memory and paging techniques of operating systems, the paper introduces vLLM, a serving system that achieves efficient management of the Key-Value (KV) cache memory, crucial for high-throughput LLM serving. Current systems are constrained by inefficient memory management, leading to significant fragmentation and limiting batch sizes. vLLM aims to offer near-zero waste in KV cache memory and facilitate flexible sharing across requests.
Memory Management Challenges
LLMs require significant computational resources due to the dynamic growth and shrinkage of their KV cache memory. Serving LLMs involves processing multiple requests to increase throughput, which requires efficient memory management. Inefficiencies primarily arise from reserving contiguous chunks of memory, leading to fragmentation and underutilization. Existing solutions suffer from substantial internal and external fragmentation as they allocate memory based on maximum possible lengths, without prior knowledge of actual output lengths.
(Llahigure 1)
Figure 1: Memory layout when serving an LLM with 13B parameters, demonstrating memory persistence for parameters and dynamic allocation for KV cache.
PagedAttention Algorithm
PagedAttention reimagines the management of KV cache memory by adopting block-based noncontiguous storage. It segments each request’s KV cache into blocks, enabling the use of noncontiguous memory, analogous to paging in operating systems. This design allows for on-demand memory allocation, minimizes fragmentation, and supports efficient sharing. The algorithm defines a block-level attention computation that processes blocks independently and utilizes GPU parallelism for accessing cached information efficiently.
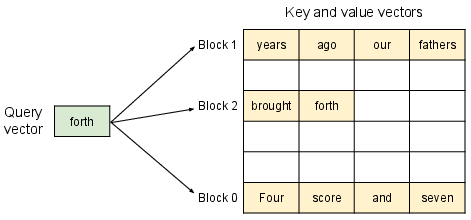
Figure 2: PagedAttention algorithm illustration, with key and value vectors stored as non-contiguous memory blocks.
Overview of vLLM System
The vLLM system is constructed around the PagedAttention algorithm, using block-level memory management to handle distribution across multiple GPU workers. The system incorporates a centralized scheduler and a KV cache manager, which operate jointly to manage memory and enhance throughput. This architecture facilitates flexible request serving by dynamically allocating memory based on the actual needs of requests rather than potential maximum requirements.
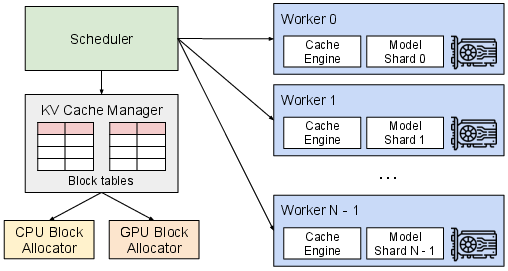
Figure 3: vLLM system architecture, demonstrating centralized scheduling and distributed GPU block management.
Evaluations and Results
Experimental evaluations demonstrate vLLM's substantial performance improvements over state-of-the-art systems like FasterTransformer and Orca, showing a 2-4× improvement in serving throughput without compromising accuracy. Tests across multiple datasets, including ShareGPT and Alpaca, highlight the benefits of reduced memory waste and increased batch sizes due to effective use of memory sharing techniques and efficient scheduling.
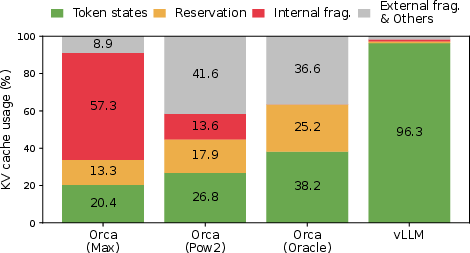
Figure 4: Average percentage of memory wastes under experimental settings, highlighting efficiency improvements in KV cache usage.
Implications and Future Developments
The implications of the PagedAttention algorithm are profound for LLM serving, offering a scalable solution that leverages memory management techniques from operating systems. Practically, vLLM enables more cost-efficient use of resources and opens opportunities for broader deployment of advanced LLM applications. Future developments may include adaptations of PagedAttention for other memory-bound AI workloads and enhancements to support emerging hardware architectures.
Conclusion
The paper presents a significant advancement in LLM serving by focusing on memory management efficiencies via PagedAttention. By implementing a block-based attention mechanism and supporting flexible request batching, vLLM offers a robust system capable of high-throughput LLM deployment, paving the way for further research and optimization in AI infrastructure. The methods introduced are likely to impact future design paradigms for deploying large-scale models in constrained environments.