- The paper demonstrates that ViT models, notably EfficientViT-M2, balance accuracy and efficiency for onboard satellite image classification.
- The study reveals that pre-trained ViT architectures outperform CNNs while maintaining robust performance under Gaussian noise and motion blur.
- The findings indicate that EfficientViT-M2 is optimal for Earth observation tasks, offering strong performance with reduced computational demands.
Onboard Satellite Image Classification for Earth Observation: A Comparative Study of ViT Models
Introduction
The paper focuses on remote sensing image classification (RS-IC), a crucial element in Earth observation (EO) systems. With the rapid advancement of Transformer-based architectures, Vision Transformers (ViTs) have taken the forefront, surpassing the performance of traditional CNNs and exhibiting high accuracy, computational efficiency, and robustness against noise. This paper evaluates various ViT models, particularly focusing on their application in land use classification for onboard satellite processing.
Machine Learning Models Compared
The study evaluates a range of models, starting from conventional CNNs and ResNets to advanced ViT architectures. ViTs especially stand out due to their superior performance stemming from pre-trained models.
- Pretrained ViT Models: EfficientViT-M2, MobileViTV2, and SwinTransformer were included in the analysis, with MobileViTV2 achieving the highest accuracy but at a relatively higher computational cost.
- Models Trained from Scratch: CNNs, ResNet-14, Compact Transformer (CCT), and SmallViT were tested, with ResNet showing notable performance among those trained without pre-training.
The models were assessed not only on performance metrics like accuracy, precision, and recall but also on computational efficiency parameters including inference time and power consumption.
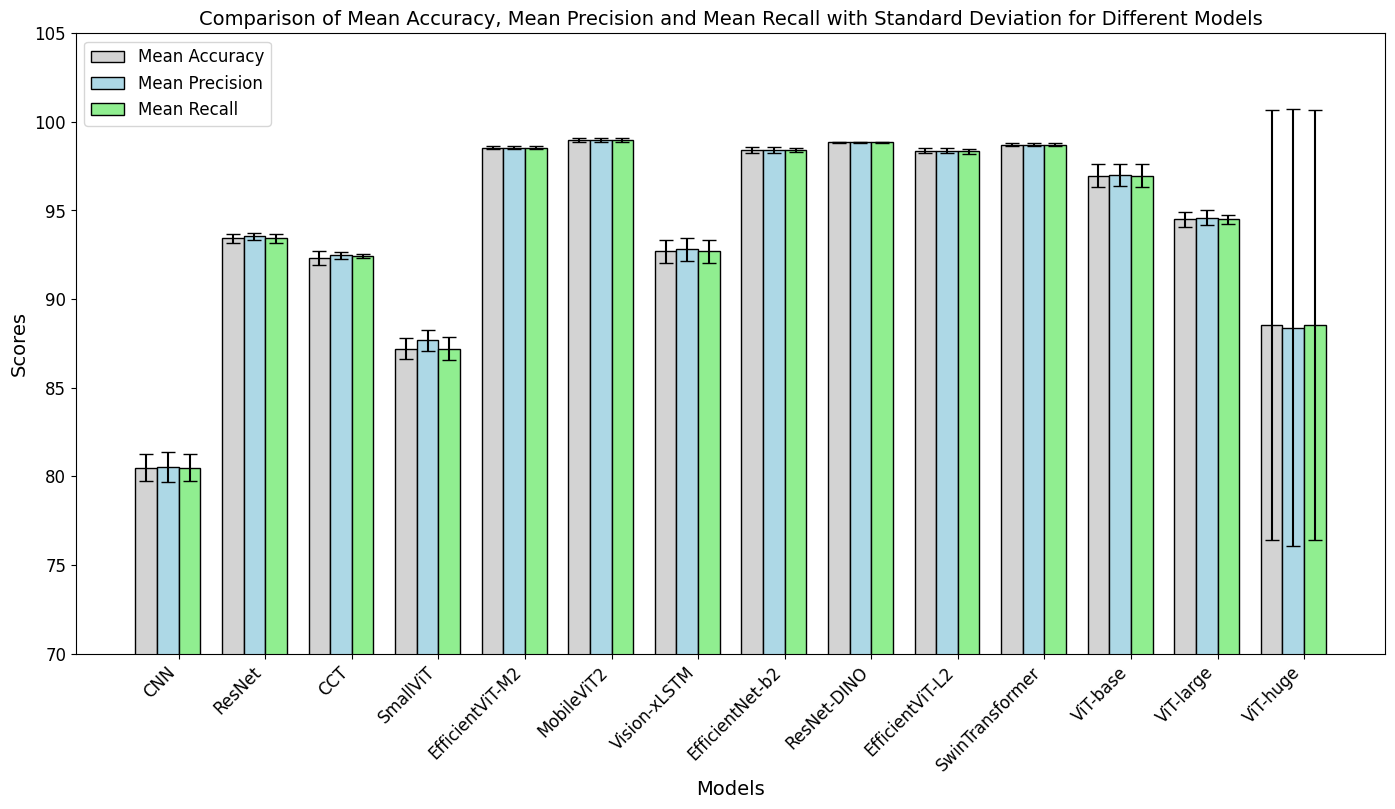
Figure 1: Statistical comparison for model performance.
Computational Efficiency
EfficientViT-M2 emerged as the optimal model due to its lean architecture, offering a significant reduction in computational load compared to other ViT models. It balances accuracy and resource usage, with notably lower power consumption during inference compared to its counterparts, making it highly suitable for onboard satellite systems.
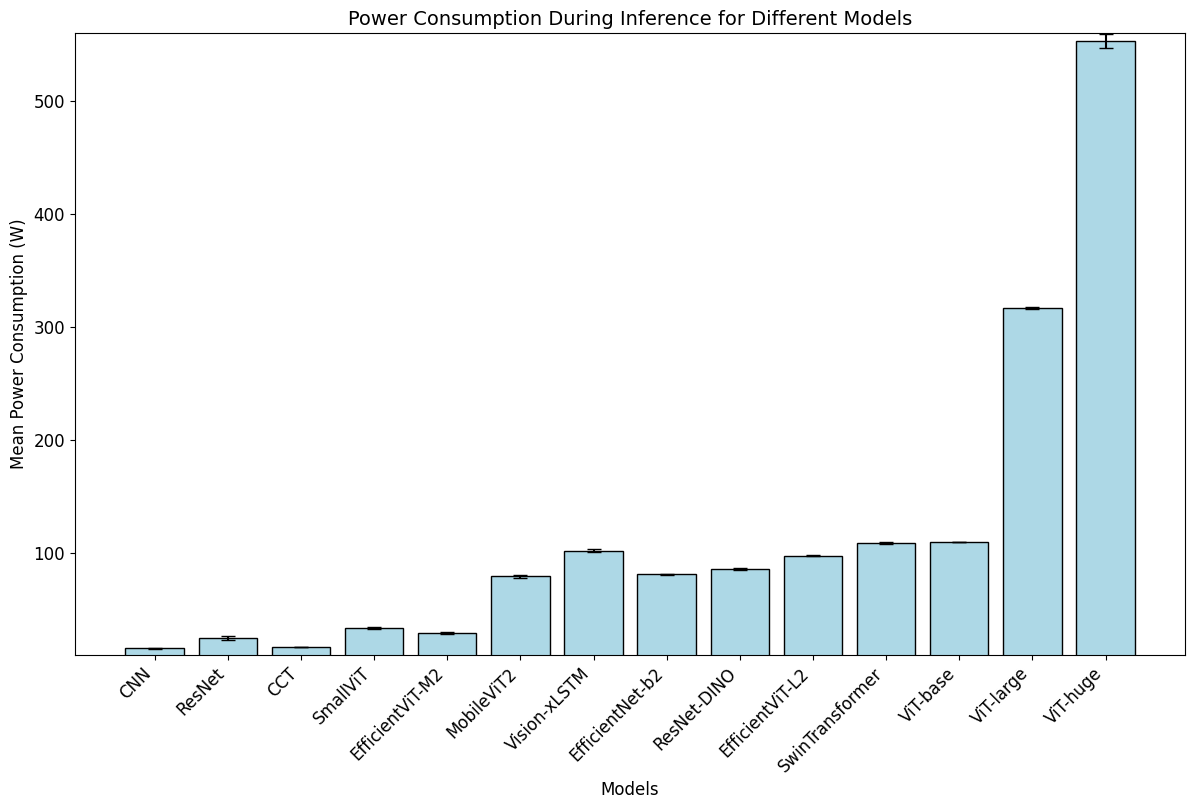
Figure 2: Statistical comparison for power consumption during inference.
Robustness Under Noisy Conditions
The robustness of the models was meticulously tested under various noise conditions. Gaussian noise and motion blur, common in satellite operations, were applied to test datasets:
- Gaussian Noise: EfficientViT-M2 showed superior resilience, maintaining higher robustness scores across all severity levels when compared to MobileViTV2.
- Motion Blur: EfficientViT-M2 again led in handling noise, particularly at higher severity levels.
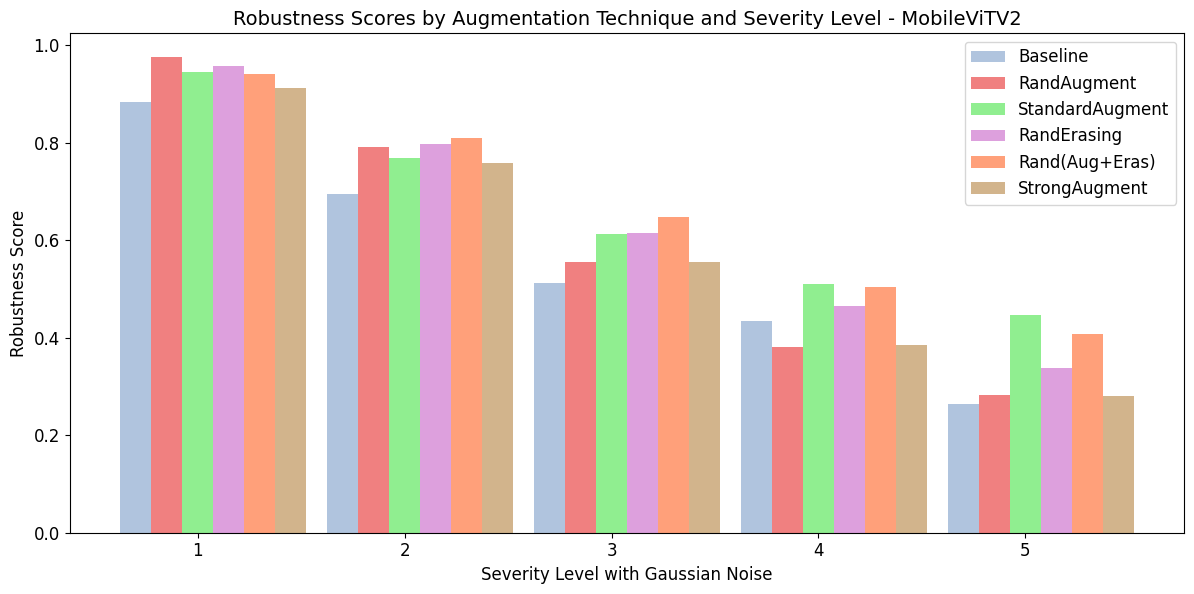
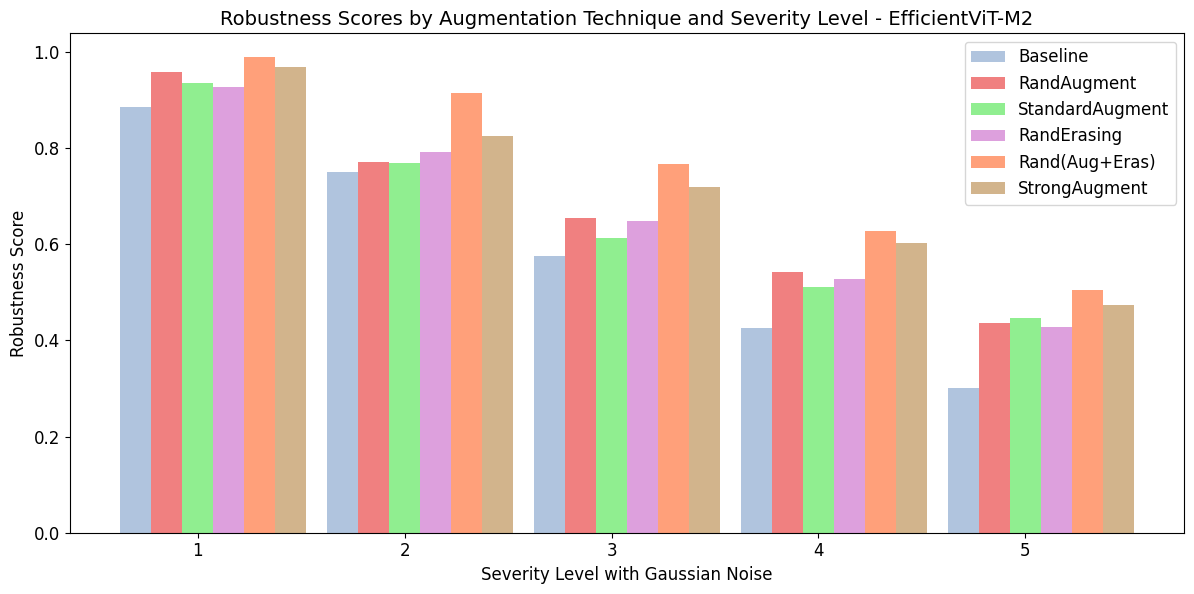
Figure 3: MobileViT (Top) and EfficientViT (Bottom) robustness with Gaussian noisy inference data.
Discussion and Conclusion
The study concludes that EfficientViT-M2 is the most suitable model for onboard satellite image classification tasks, given its balanced trade-off between performance, robustness, and computational demands. MobileViTV2, while performing slightly better in accuracy on clean data, is surpassed by EfficientViT-M2 in noisy environments and efficiency metrics.
The implications of this research extend to real-world applications in EO missions, where resource constraints require models that are both efficient and robust. The findings underscore the potential of Transformer-based models in enhancing remote sensing tasks, not merely in classification accuracy but in operational practicality within environmental constraints.
In future developments, integrating these ViT models in multitask frameworks could further push the boundaries of EO systems, providing greater utility and insight by simultaneously learning multiple applications.

