- The paper reviews multiple abstractive summarization methods, highlighting the transition from traditional seq2seq models to large pre-trained language models and reinforcement learning.
- The paper details key challenges such as inadequate meaning representation, factual consistency, and handling long documents in summary generation.
- The paper outlines future directions including multimodal integration and cross-domain adaptability to enhance summarization accuracy.
Abstractive Text Summarization: State of the Art, Challenges, and Improvements
Introduction to Abstractive Summarization
Abstractive text summarization aims to generate concise summaries that capture the essential ideas of a source document, creating new sentences that may not appear in the original text. This approach has garnered attention for its potential to mimic human-like summarization, surpassing traditional extractive methods that merely select existing phrases from the source. As textual data proliferates, abstractive summarization is vital for distilling critical information efficiently, offering insights across various domains such as news media, research, and customer reviews.
Techniques and Models in Abstractive Summarization
Abstractive text summarization is characterized by several advanced methodologies, demonstrating diverse approaches to generating coherent, meaningful summaries.
Traditional Sequence-to-Sequence Models (Seq2Seq)
Traditional Seq2Seq models, such as those employing encoder-decoder architectures, have formed the basis for many summarization systems. These models utilize mechanisms like attention to focus on vital content during summary generation, and newer adaptations incorporate techniques like copy mechanisms to handle out-of-vocabulary words (Figure 1).
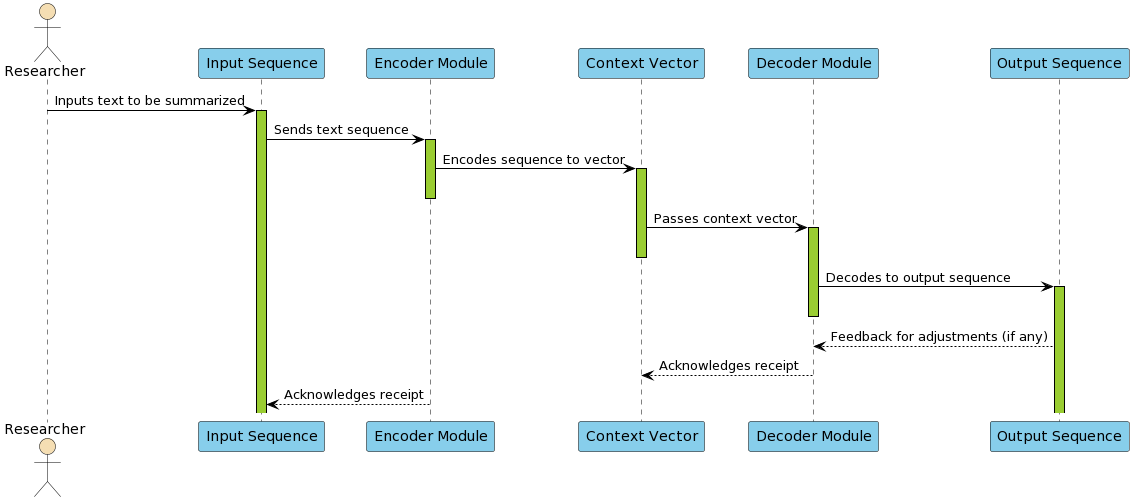
Figure 1: Traditional Seq2Seq model flow for abstractive text summarization.
Pre-trained LLMs
Pre-trained LLMs, including the BERT, GPT, and T5 architectures, leverage extensive training on broad datasets to provide rich contextual embeddings, crucial for abstractive summarizing tasks. These models deliver state-of-the-art accuracies, processing nuanced textual relationships and achieving high coherence (Figure 2).
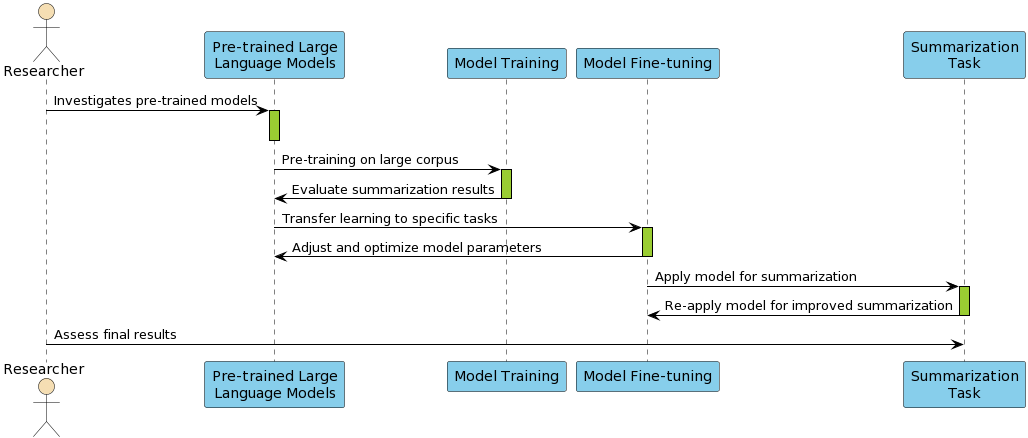
Figure 2: Pre-trained LLM flow for abstractive summarization.
Reinforcement Learning Approaches
Reinforcement Learning (RL) introduces a reward system to optimize summarization quality, assessing human-like preferences. This approach shows promise in guiding models to prioritize content that better aligns with human expectations (Figure 3).
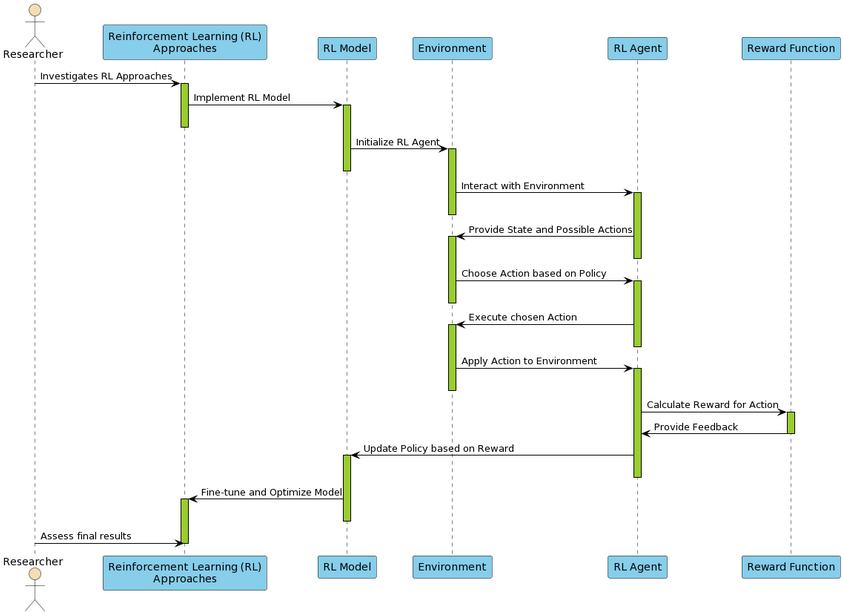
Figure 3: Reinforcement Learning approaches flow for abstractive summarization.
Hierarchical and Multi-modal Approaches
Hierarchical models, capitalizing on the document structure, enhance summary coherence by processing texts at multiple levels of abstraction (Figure 4). Multi-modal approaches integrate various data types like text, image, and video, creating summaries that reflect the comprehensive input modalities (Figure 5).
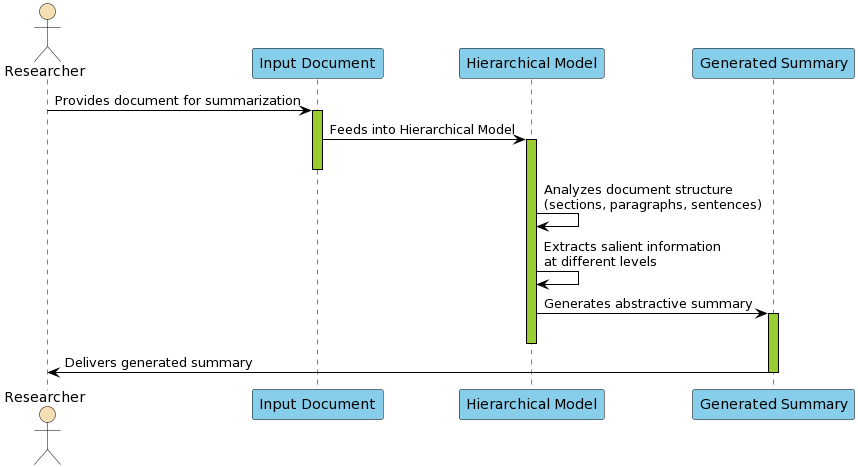
Figure 4: Hierarchical approaches flow for abstractive summarization.
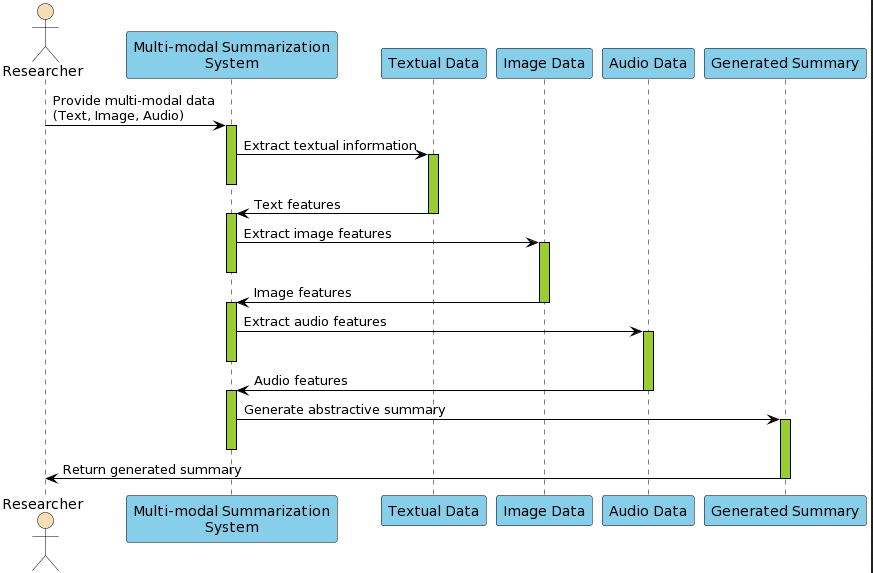
Figure 5: Multi-Modal flow for abstractive text summarization.
Challenges and Future Directions
Abstractive summarization faces several challenges that necessitate continued innovation and research.
Inadequate Representation of Meaning
Despite advanced models, capturing the full semantic depth and meaning while maintaining conciseness is still challenging. Leveraging robust knowledge representations and innovative model architectures can enhance meaning representation.
Factual Consistency and Evaluation Metrics
Ensuring factual accuracy within summarization remains paramount, especially in domains where misinformation can have severe implications. Reinforcement learning strategies, along with custom evaluation metrics like BERTScore and MoverScore, aim to address these concerns.
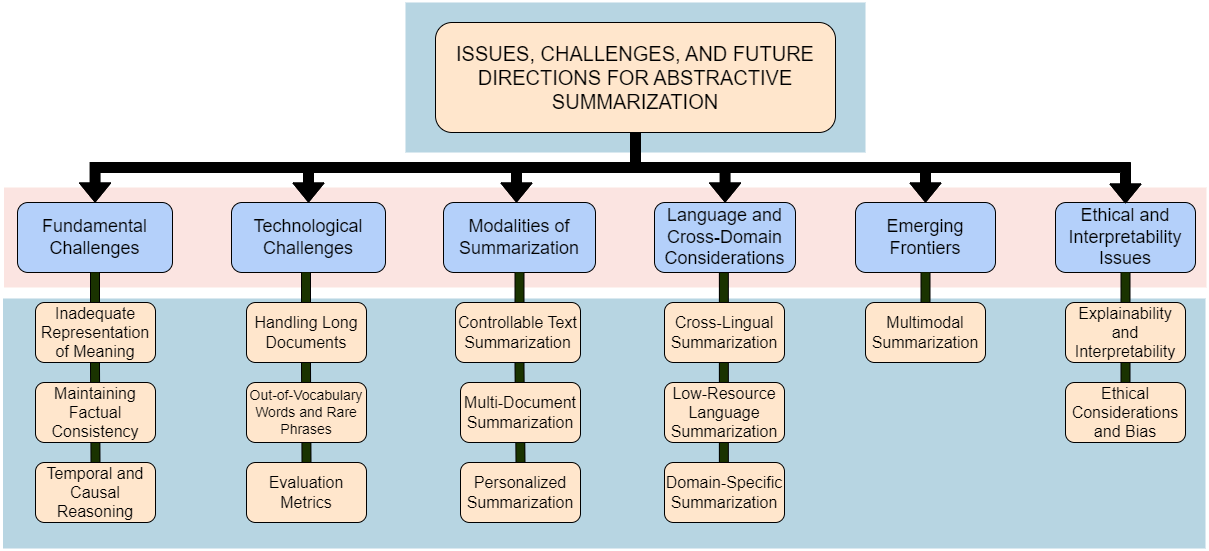
Figure 6: Taxonomy of Issues, Challenges, and Future Directions for Abstractive Summarization.
Handling Long Documents and Cross-Domain Summarization
Long-document summarization requires specialized models to capture extended contextual dependencies and relevance, while cross-domain summarization necessitates adaptability to diverse content requirements. Future research is directed toward enhancing domain-specific models and improving cross-lingual capabilities.
Multimodal Summarization
The evolving landscape of multimedia content demands summarization models capable of processing and synthesizing information across text, visuals, and audio modalities. Developing advanced algorithms to integrate these inputs is an ongoing frontier.
Conclusion
The field of abstractive text summarization continues to evolve rapidly, driven by innovations in model architecture, strategies for factual consistency, and enhancements in evaluation metrics. Addressing challenges such as inadequate meaning representation, domain adaptation, and multilingual summarization are crucial steps to refine summarization capabilities further. As research progresses, the focus remains on developing systems that efficiently and accurately represent content, meeting user expectations across varying domains and languages. This structured overview seeks to guide researchers in advancing abstractive summarization research, promoting solutions that balance novelty and coherence.