- The paper introduces SciCode, a benchmark structured to gauge language models' ability to synthesize code for scientific research without supplemental background.
- It employs a hierarchical problem breakdown with expert annotations to mirror the complexity of real research coding tasks.
- Results show that even leading models achieve only a 4.6% success rate in realistic settings, highlighting significant performance limitations.
"SciCode: A Research Coding Benchmark Curated by Scientists"
Introduction
The paper presents SciCode, a benchmark designed to evaluate the capabilities of LMs in generating code for solving real scientific research problems. SciCode encompasses challenges across various natural science fields, including mathematics, physics, chemistry, biology, and materials science. The primary goal is to ascertain the proficiency of LMs in code synthesis, reasoning, and utilizing scientific knowledge to provide realistic evaluations of their capabilities.

Figure 1: A SciCode main problem is decomposed into multiple smaller and easier subproblems. Docstrings specify the requirements and input-output formats. When necessary, scientific background knowledge is provided, written by our scientist annotators.
Benchmark Design
Problem Selection
SciCode's problems are carefully chosen to encompass a diverse range of subfields, demonstrating the extensive representation of natural sciences where scientific code is crucial. They originate from scientists' everyday research workflows, often used internally and rarely open-sourced. Thus, SciCode presents a unique challenge by providing problems less familiar to most current LMs' training data.
Problem Structure
SciCode problems are broken down into main problems and subproblems. Each main problem articulates the overarching task, requiring the integration of solutions to the corresponding subproblems. This structure reflects real research coding tasks that require isolating complexities into simpler components.

Figure 2: SciCode Example General Problem and Dependencies.
Annotation Process
The annotations, involving experienced researchers, ensure high-quality evaluations. Problems include gold-standard solutions and test cases, verified by domain experts to assure scientific accuracy and meaningful evaluation.
Evaluations and Metrics
SciCode evaluates models in various settings ranging from subproblem level to complete main problem resolution. Key evaluation metrics involve determining LMs' abilities with and without scientific background knowledge, managing prior subproblem solutions, and offering realistic evaluation conditions closest to genuine research coding tasks.
Results
Experimental results indicate that even state-of-the-art LMs can solve only a small fraction of SciCode's problems, particularly in the most realistic setting where scientific background is not provided. Claude3.5-Sonnet achieved a pass@1 rate of 4.6% on main problems when devoid of such background, highlighting SciCode's challenge as a benchmark.
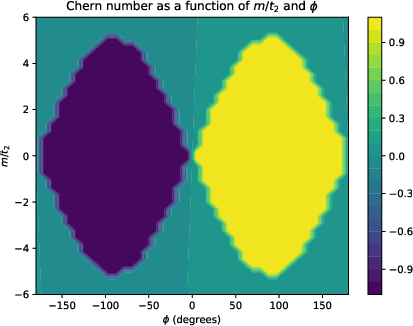
Figure 3: delta = 2π/30, a = 1.0, t1 = 4.0, t2 = 1.0, N = 40.
Implications and Future Work
SciCode illuminates the current limitations and potential growth areas for LMs in scientific coding. By demonstrating difficulties faced by even leading LMs, it suggests a need for further enhancements in LMs’ reasoning and domain-specific knowledge capabilities. The benchmark also drives research towards developing AI methods that can more effectively support scientific research, aiding areas yet to benefit fully from AI advancements.
In conclusion, SciCode provides a rigorous, realistic benchmark that promises to guide the development and evaluation of LMs in coding for scientific research, emphasizing their role as potential scientific assistants in the future.

