- The paper presents a novel evolvable game language using cellular automata rewrite rules to generate dynamic reinforcement learning environments.
- It leverages GPU-parallelized JAX implementations and tree search-driven evolutionary strategies to accelerate agent training.
- Experimental results show agents trained in Autoverse outperform those in static settings, demonstrating improved adaptability and search complexity.
Autoverse: An Evolvable Game Language for Learning Robust Embodied Agents
Autoverse introduces a novel framework for simulating single-player 2D grid-based games designed to enhance open-ended learning (OEL) in reinforcement learning (RL) environments. By leveraging cellular-automaton-like rewrite rules for defining game dynamics, Autoverse provides a robust and scalable platform for training RL agents faster and more efficiently.
Introduction and Methodology
The core hypothesis behind Autoverse is that complex and highly variable environments are crucial for achieving advanced levels of open-ended learning in RL agents. Traditional RL environments often suffer from lack of variability, which limits the learning potential of agents. Autoverse addresses this limitation by allowing for an evolvable set of environment dynamics and layouts. Game mechanics are encoded through sets of rewrite rules applied to patterns of tiles on a grid, enabling the seamless incorporation of dynamics from various games like mazes, sokoban puzzles, and dungeons.
Autoverse is implemented using JAX for efficient parallel processing on GPUs. By utilizing convolutions as the primary mechanism for applying rewrite rules, the language allows for rapid environment simulation, which is critical for accelerating the training of RL agents.

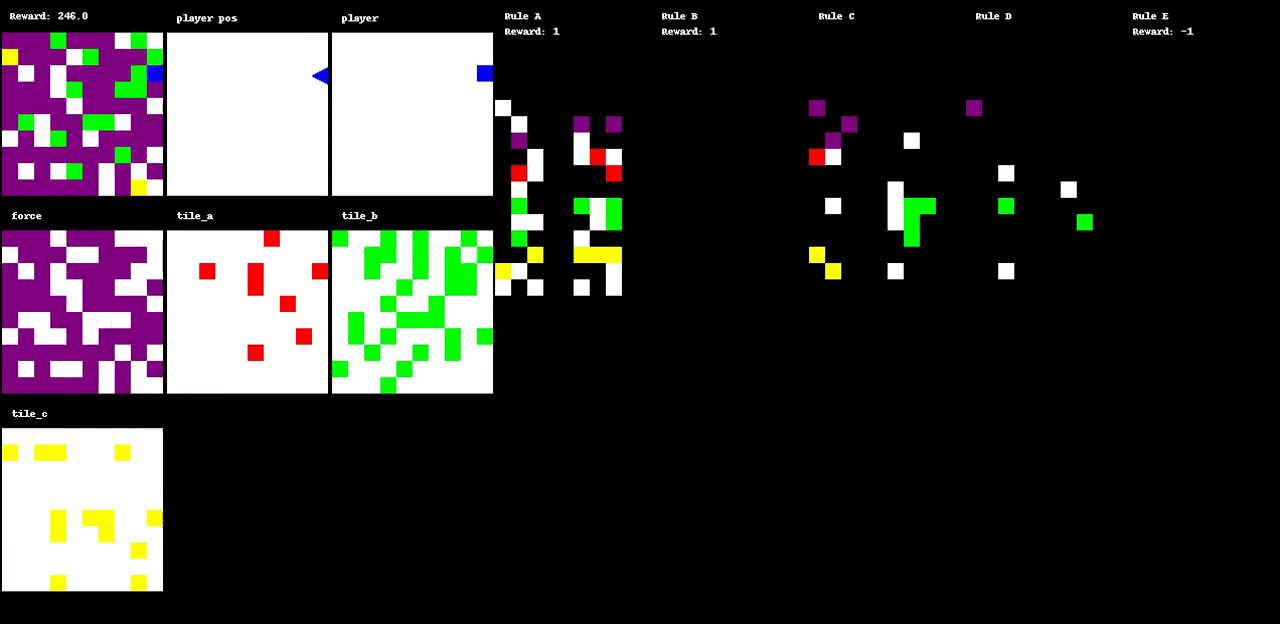

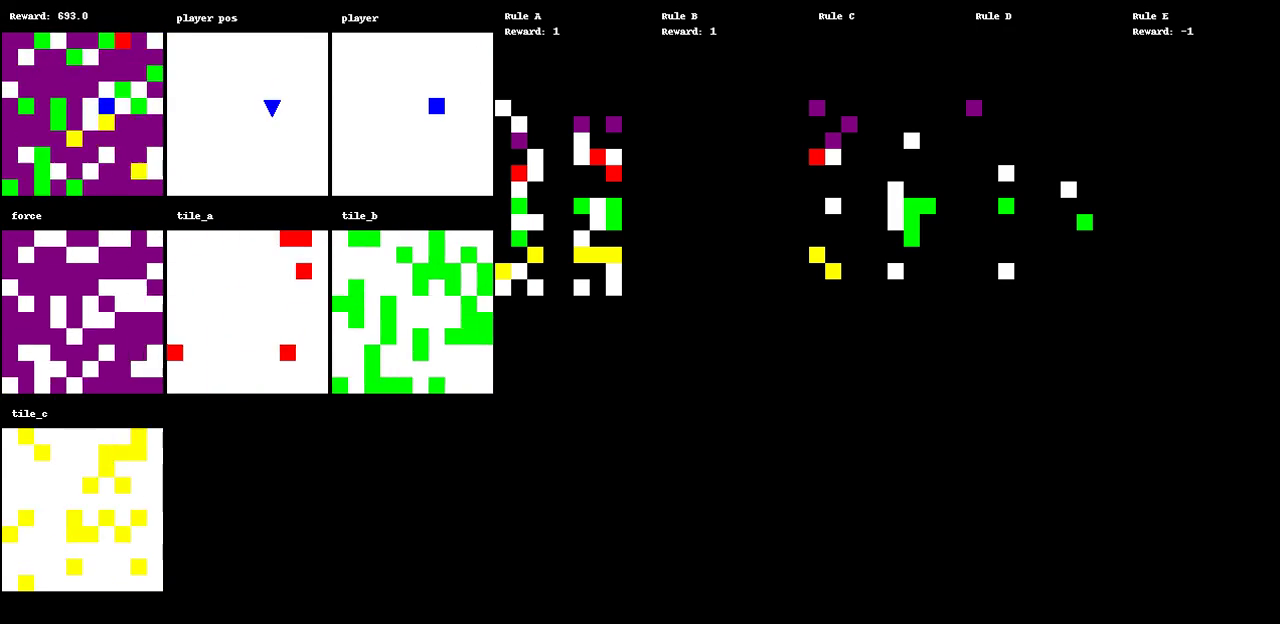
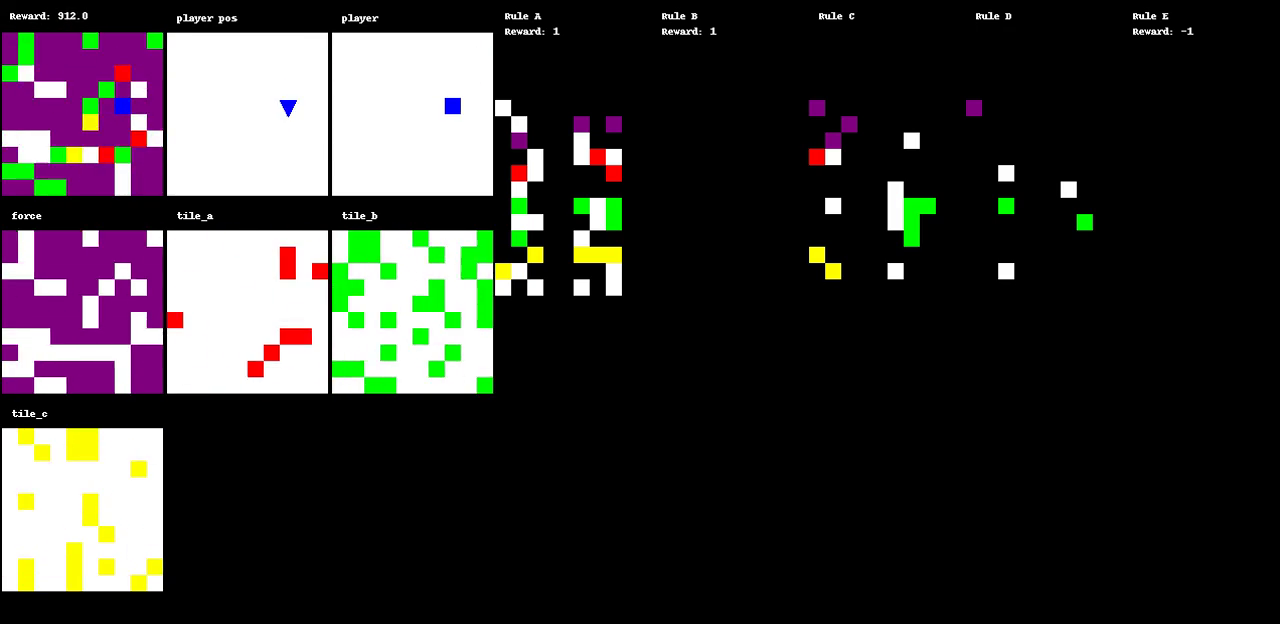
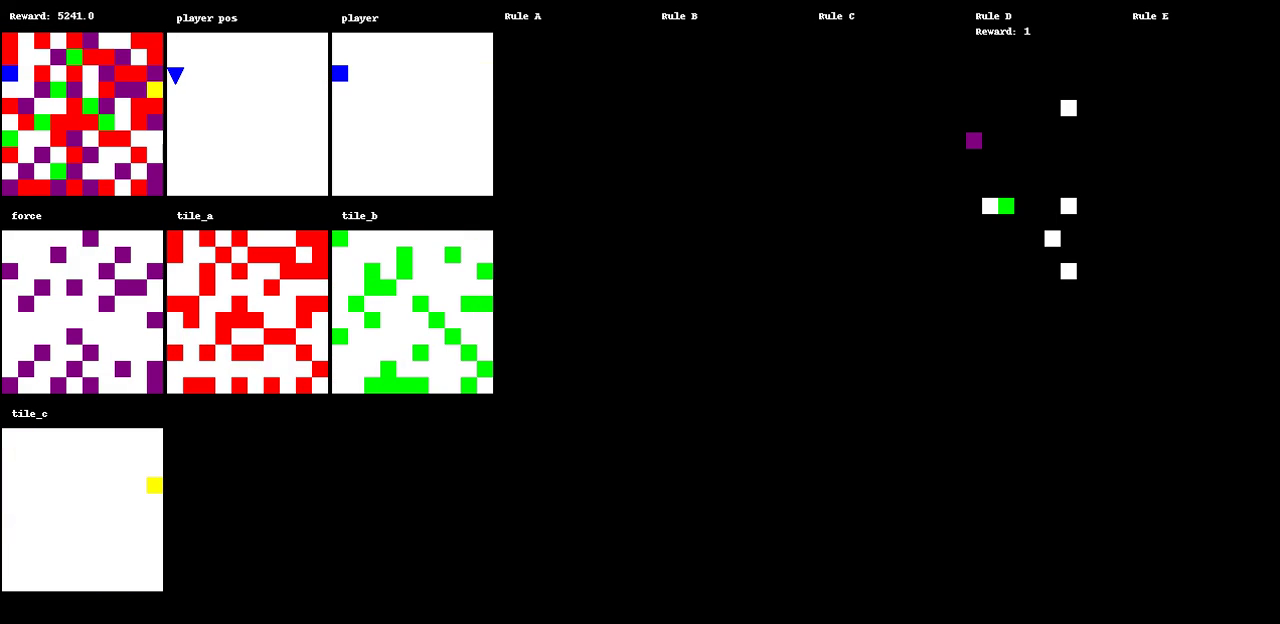
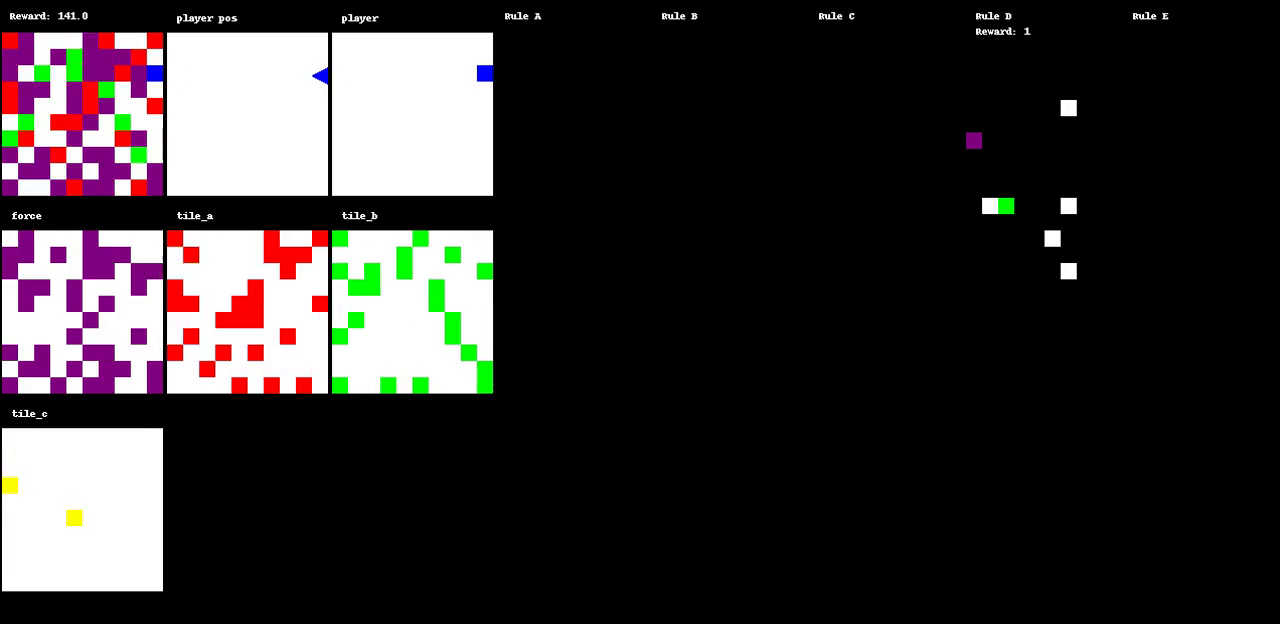


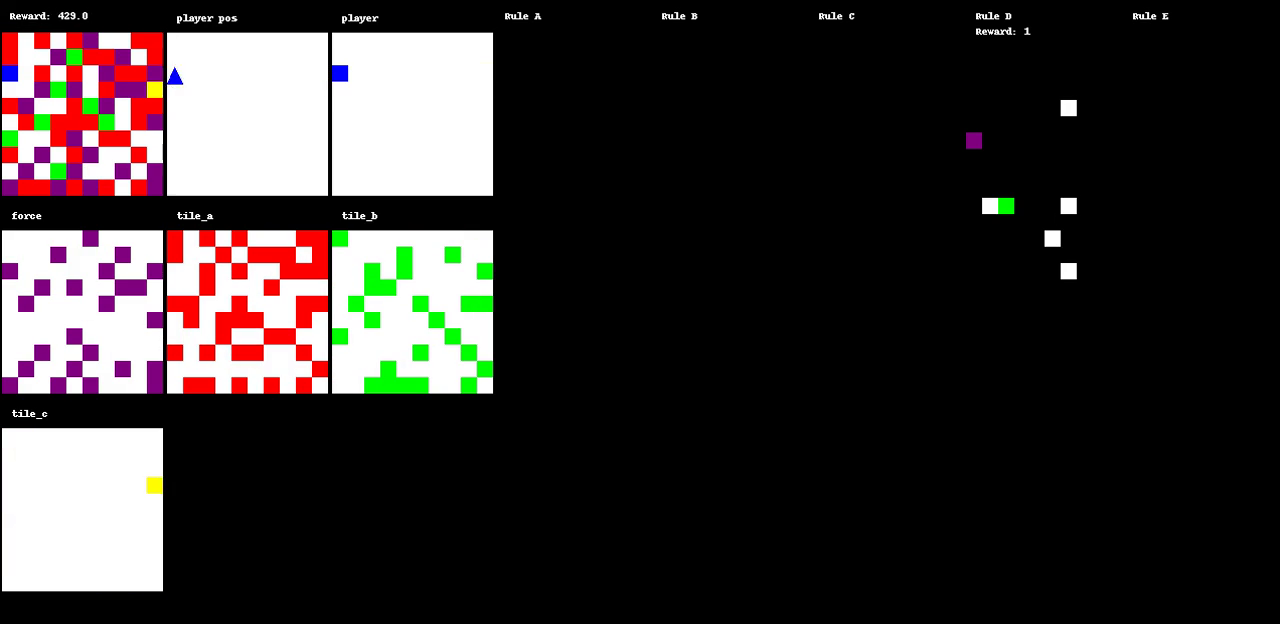
Figure 1: The evolution of a game through various states, illustrating dynamic interactions within the environment.
Environment Evolution and Agent Training
A primary innovation of Autoverse is the evolution of game environments to maximize search complexity. Initial experimental setups involve basic maze-like environments, which are evolved by applying a simple evolutionary strategy to modify the tiles and rulesets. This process ensures that the environments increasingly demand complex decision-making from the RL agents. Each environment's fitness is gauged by the complexity of solutions found through greedy tree search algorithms. The approach of using tree search to evaluate the environments helps in cultivating a curriculum that escalates in difficulty, effectively preparing agents for increasingly challenging tasks.
Alongside environment evolution, agents undergo a "warm-start" procedure, where they are initially trained using behavior cloning from an archive of expert trajectories generated from tree search solutions. This imitation learning phase provides a strong starting point for subsequent RL training cycles.
Experimental Results
Results demonstrate that agents trained in Autoverse environments outperform those trained in static environments, particularly when given larger observational capacities. Observational windows that allow agents to perceive a greater portion of the board state tend to yield higher performance levels. Furthermore, equipping agents with the ability to observe environment rulesets enhances their effectiveness, underlining the diverse and challenging nature of Autoverse-generated environments.
Preliminary findings highlight a variety of dynamics within evolved environments, often resulting in highly dynamic and chaotic states. Such environments force agents to engage in prolonged searches to optimize behavior, which enhances their adaptability and learning capacity.
Autoverse contributes to existing literature by addressing the generalization challenges in RL benchmarks with a novel combination of procedural content generation and open-ended learning goals. It expands upon the foundations laid by environments like CoinRun and Neural MMO, which also employ procedural generation to enhance diversity and agent adaptability. Unlike previous benchmarks, Autoverse provides an evolving task space responsive to agent progress, thus encouraging the development of more general and capable RL strategies.
Conclusion
Autoverse establishes a comprehensive testbed for studying and advancing open-ended learning algorithms. The combination of cellular automata-based mechanics with efficient GPU-parallelized simulations presents an innovative platform for evolving complex game environments. Future directions include the incorporation of foundation models and human-in-the-loop systems to further align the generated environments with human-like notions of complexity and interestingness. This research promises to push the boundaries of RL capabilities, fostering agents with higher adaptability and generalization skills across diverse tasks.