- The paper demonstrates that Prithvi outperforms CGAN in cloud gap imputation by achieving superior SSIM and MAE metrics on multispectral data.
- The study employs a Vision Transformer with 100M parameters, pre-trained on 1TB of HLS data using masked autoencoder self-supervision for robust spatial and temporal analysis.
- The findings highlight practical applications in precision agriculture and environmental monitoring by ensuring reliable temporal coverage despite cloud-induced data gaps.
Cloud Gap Imputation in Multispectral Satellite Imagery Using Prithvi Foundation Model
Introduction
Cloud coverage in satellite imagery poses a significant challenge for various geospatial analyses, especially in tasks requiring time-series data such as crop monitoring and land-use change detection. This study examines the efficacy of the Prithvi Foundation Model, a Vision Transformer (ViT) architecture, in addressing cloud gap imputation, comparing its performance with a Conditional Generative Adversarial Network (CGAN). The foundation model benefits from self-supervision techniques that leverage vast datasets without high-quality ground truth labels, making it suitable for tackling missing data imputation problems prevalent in multispectral satellite imagery.
Model Architectures
Prithvi leverages a ViT architecture, embodying 100M parameters, and pre-trained on 1TB of Harmonized Landsat and Sentinel-2 (HLS) imagery using masked autoencoder learning frameworks. The foundational aspect allows it to encode representations of spatial, temporal, and spectral relationships effectively.
Contrastingly, the CGAN model employs encoder-decoder convolutional neural networks, inspired by Pix2Pix architecture. It was trained using real-world cloud masks as input conditions against unmasked ground truth (Figure 1), adapted from non-geospatial data applications to fit the geospatial domain more accurately.
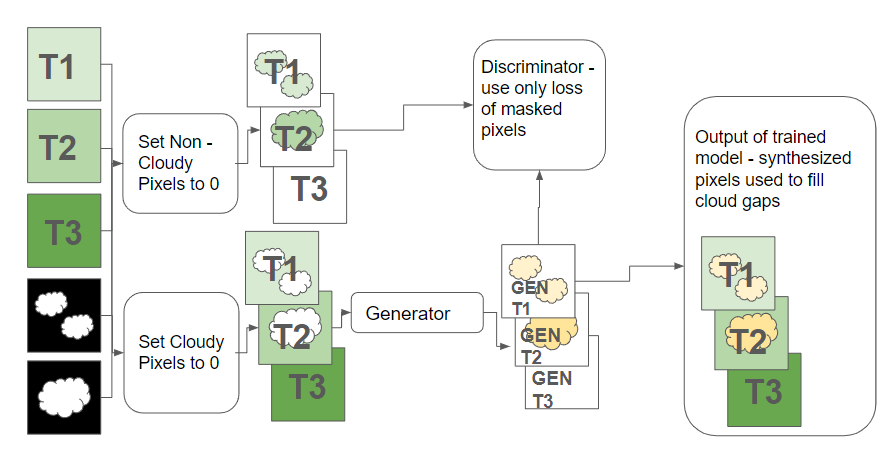
Figure 1: Training the CGAN to impute cloudy pixels was accomplished by masking out clouds from input data, using this as the condition on which to generate, then comparing the generated data against the unmasked ground truth.
Methodology
The comparative analysis involved training both models on cloud-masked time-series datasets from the HLS dataset, spanning diverse land cover classes across the Contiguous United States (CONUS). The training sets included random partitions of cloud-free imagery chips with differently sized subsets used to determine model efficacy quantitatively.
Two experiments were designed: E1, where only the middle scene in each chip was masked; and E2, which involved masking combinations across all temporal scenes. Prithvi was fine-tuned using real-life cloud masks as inputs replacing arbitrary masking used in pre-training, while CGAN's generator underwent adjustments based on discriminator outputs intertwined with pixel-wise comparison outcomes.
Results and Discussion
When analyzing performance, Prithvi consistently outperformed CGAN across diverse metrics like SSIM and MAE, showcasing robustness even in zero-shot settings (Figure 2). The CGAN, while demonstrating improvements with increased data, could not match Prithvi's performance without fine-tuning, underscoring the maturity and adaptability of foundation models for geospatial applications.
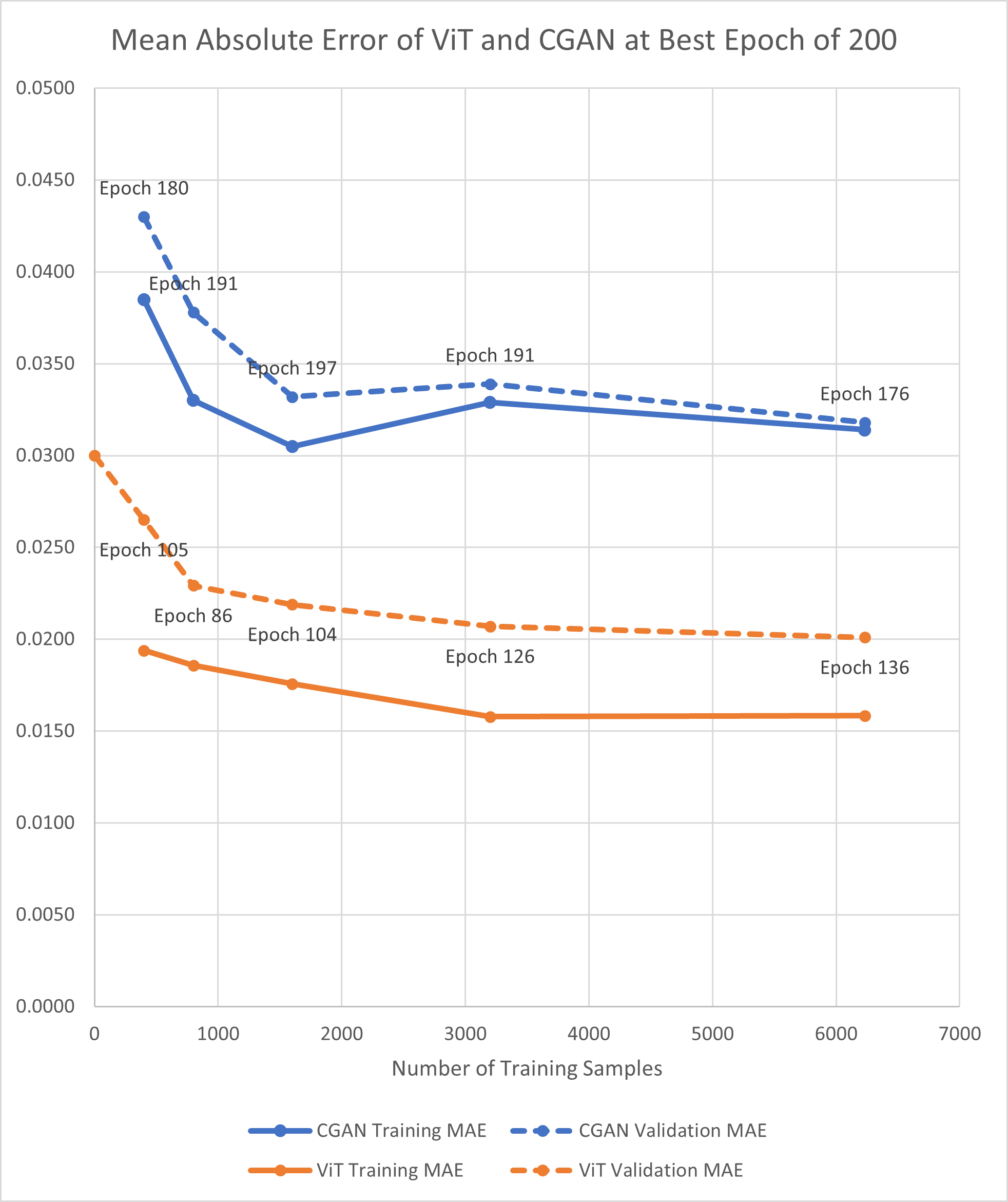
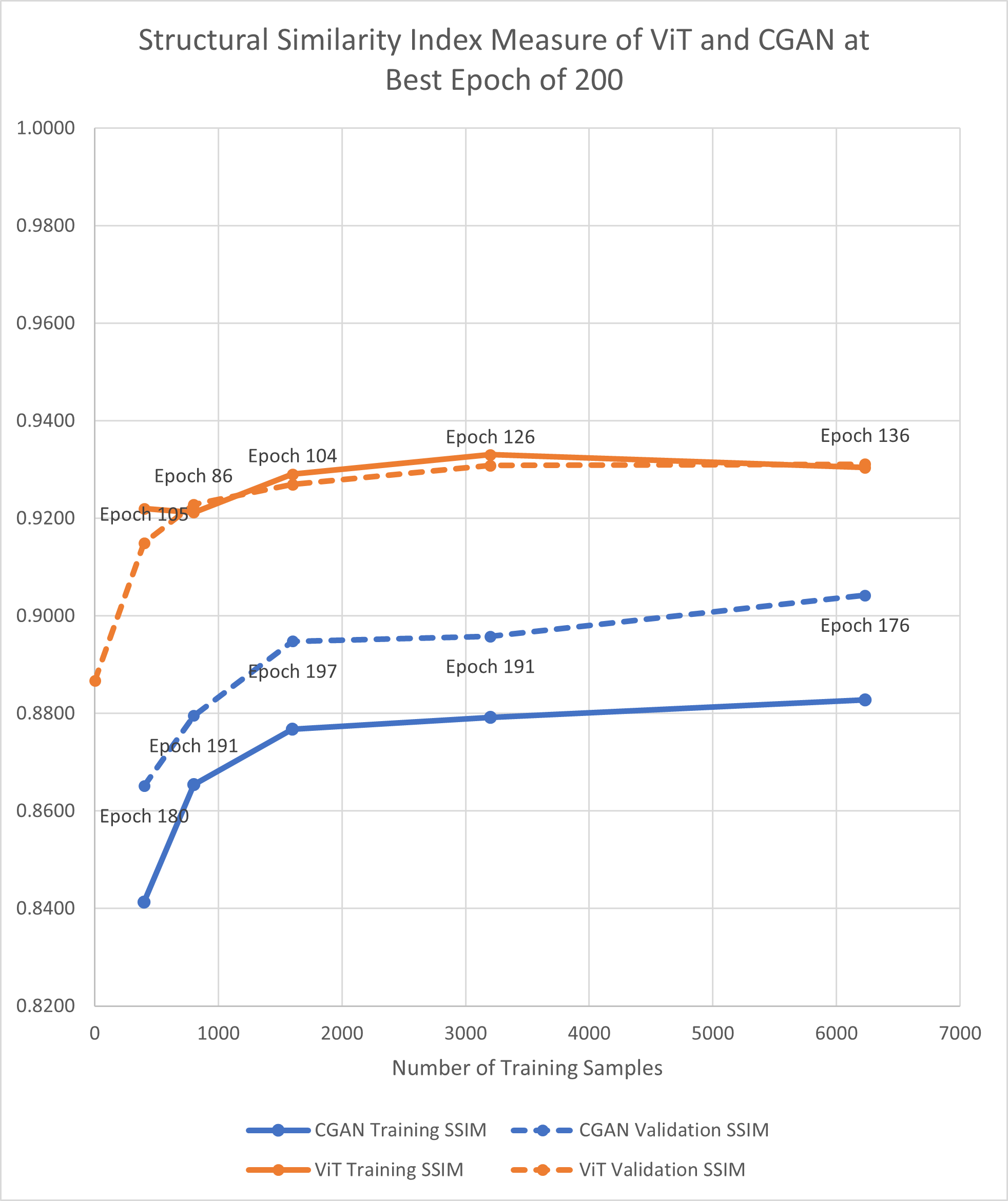
Figure 2: MAE and SSIM for best epoch of 200 for E1 experiments (applying mask to the middle scene). Best epoch is the best performance out of 5 runs for all experiments across all epochs.
Figures reveal that Prithvi, despite discarding input patches with masked pixels, maintained high accuracy, reflecting the advantage of having been exposed to extensive pre-training datasets. Moreover, the visual quality of reconstructed scenes indicated that while CGAN excelled in preserving finer details, Prithvi generated values constrained within realistic bounds, thereby offering better integration into downstream applications despite some loss of detail.
Conclusion
The Prithvi model's reliance on self-supervised learning paradigms rooted in handling missing data directly enhances its positioning for practical applications requiring comprehensive temporal coverage without extensive fine-tuning overhead. Moreover, cloud gap imputation holds promise for augmenting satellite imagery datasets, fostering advanced applications in geospatial dynamics like precision agriculture and environmental monitoring.
Future research should explore the integration of non-visual datasets such as digital elevation models and surface classification maps to refine prediction accuracy further. As the adoption of foundation models gains traction, their utility in filling cloud gaps signifies a shift towards more resilient geospatial modeling platforms capable of feeding into complex, multi-temporal analyses.
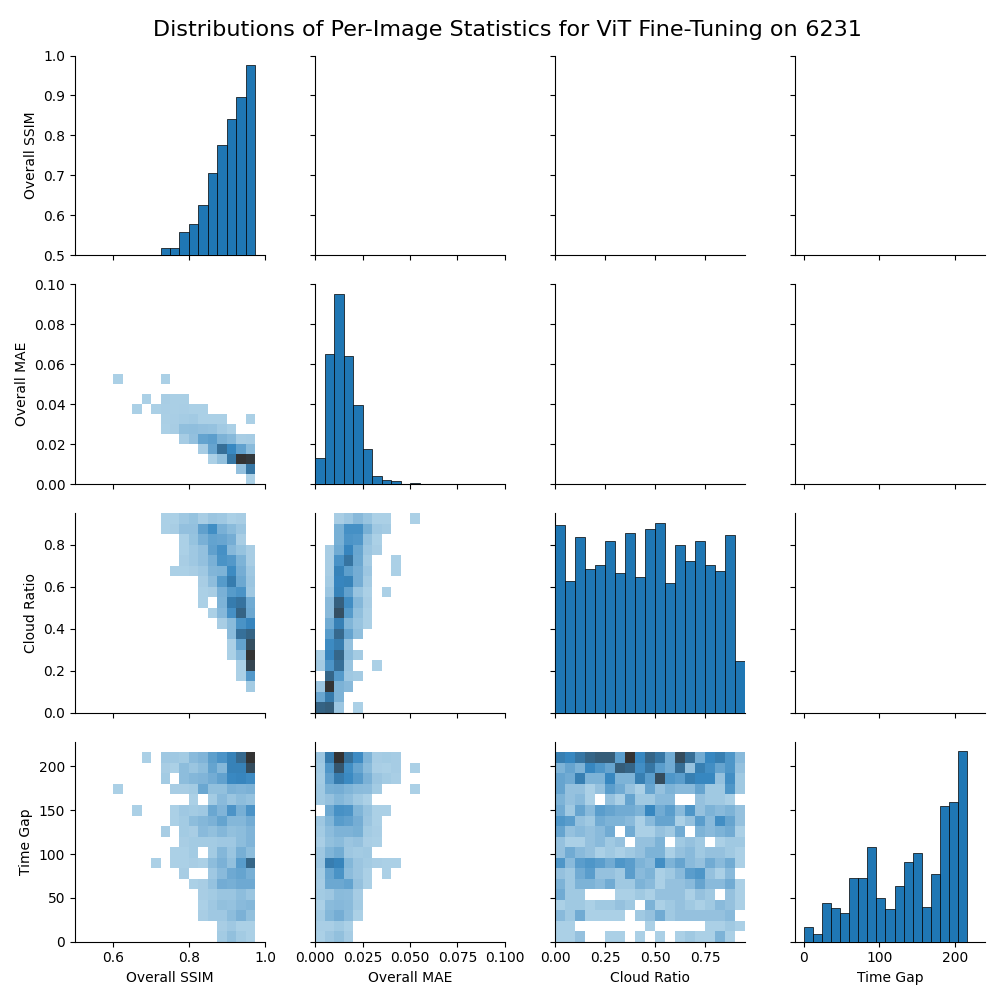
Figure 3: Relationships between cloud cover, time gap, SSIM, and MAE of validation chips for best results of E1 experiments using the full dataset to fine-tune Prithvi. Statistics are calculated for each validation chip.

