BIRD: A Trustworthy Bayesian Inference Framework for Large Language Models
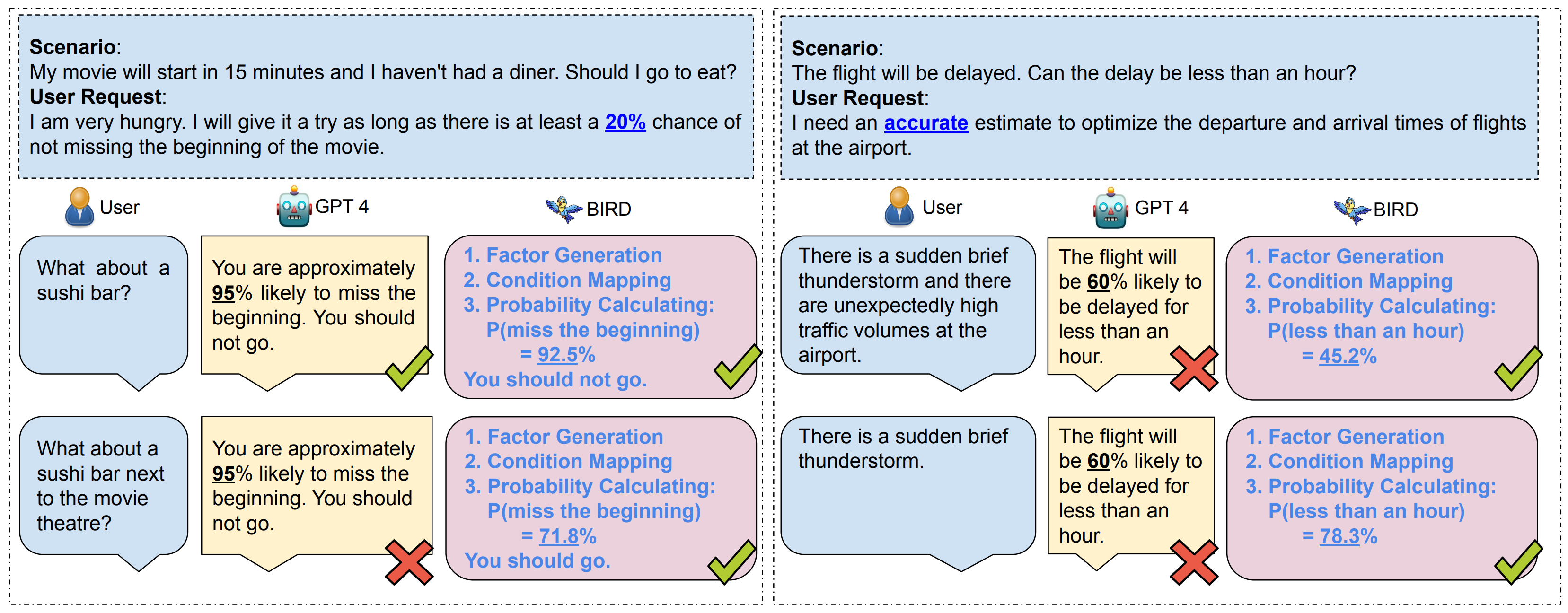
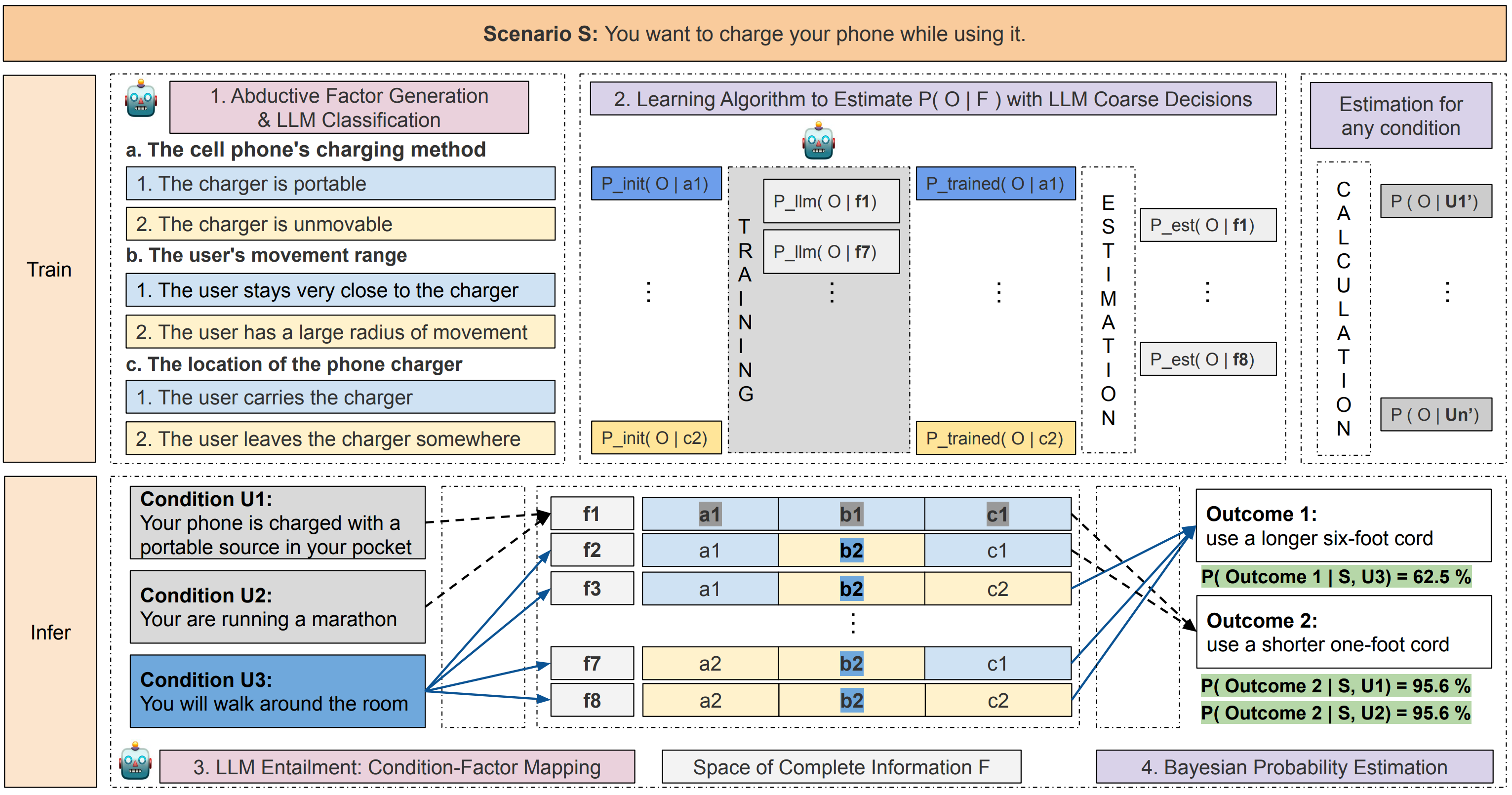
Abstract: Predictive models often need to work with incomplete information in real-world tasks. Consequently, they must provide reliable probability or confidence estimation, especially in large-scale decision-making and planning tasks. Current LLMs are insufficient for accurate estimations, but they can generate relevant factors that may affect the probabilities, produce coarse-grained probabilities when the information is more complete, and help determine which factors are relevant to specific downstream contexts. In this paper, we make use of these capabilities of LLMs to provide a significantly more accurate probabilistic estimation. We propose BIRD, a novel probabilistic inference framework that aligns a Bayesian network with LLM abductions and then estimates more accurate probabilities in a deduction step. We show BIRD provides reliable probability estimations that are 30% better than those provided directly by LLM baselines. These estimates further contribute to better and more trustworthy decision making.
- Robert F Bordley. A multiplicative formula for aggregating probability assessments. Management science, 28(10):1137–1148, 1982.
- Plasma: Making small language models better procedural knowledge models for (counterfactual) planning, 2023.
- Generic temporal reasoning with differential analysis and explanation. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 12013–12029, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.671. URL https://aclanthology.org/2023.acl-long.671.
- Bayesian Data Analysis. Chapman and Hall/CRC, Boca Ratan, Florida, 1995.
- Towards uncertainty-aware language agent, 2024.
- Training chain-of-thought via latent-variable inference. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=a147pIS2Co.
- Amortizing intractable inference in large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Ouj6p4ca60.
- Language models (mostly) know what they know, 2022.
- Probabilistic Graphical Models: Principles and Techniques - Adaptive Computation and Machine Learning. The MIT Press, 2009. ISBN 0262013193.
- Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=VD-AYtP0dve.
- Deceiving semantic shortcuts on reasoning chains: How far can models go without hallucination?, 2023.
- Swiftsage: A generative agent with fast and slow thinking for complex interactive tasks. ArXiv, abs/2305.17390, 2023.
- Teaching models to express their uncertainty in words. Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/forum?id=8s8K2UZGTZ.
- Dellma: A framework for decision making under uncertainty with large language models, 2024.
- N. F. McGlynn. Thinking fast and slow. Australian veterinary journal, 92 12:N21, 2014.
- Reducing conversational agents’ overconfidence through linguistic calibration. Transactions of the Association for Computational Linguistics, 10:857–872, 2022. doi: 10.1162/tacl˙a˙00494. URL https://aclanthology.org/2022.tacl-1.50.
- A multi-axis annotation scheme for event temporal relations. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1318–1328, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1122. URL https://aclanthology.org/P18-1122.
- Show your work: Scratchpads for intermediate computation with language models, 2021. https://arxiv.org/abs/2112.00114.
- OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023. URL https://arxiv.org/pdf/2303.08774.pdf.
- Robots that ask for help: Uncertainty alignment for large language model planners. In 7th Annual Conference on Robot Learning, 2023. URL https://openreview.net/forum?id=4ZK8ODNyFXx.
- COM2SENSE: A commonsense reasoning benchmark with complementary sentences. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 883–898, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-acl.78. URL https://aclanthology.org/2021.findings-acl.78.
- Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 5433–5442, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.330. URL https://aclanthology.org/2023.emnlp-main.330.
- Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=1PL1NIMMrw.
- Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.), Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=_VjQlMeSB_J.
- Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=gjeQKFxFpZ.
- React: Synergizing reasoning and acting in language models. ArXiv, abs/2210.03629, 2022.
- Temporal reasoning on implicit events from distant supervision. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1361–1371, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.107. URL https://aclanthology.org/2021.naacl-main.107.
- Learning to decompose: Hypothetical question decomposition based on comparable texts. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 2223–2235, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.142. URL https://aclanthology.org/2022.emnlp-main.142.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

