- The paper introduces a novel vision-language model that integrates pix2struct patching and an autoregressive decoder to advance UI and infographic analysis.
- It employs a diverse pretraining approach with over 400 million samples, enhancing task performance in screen annotation, QA, navigation, and summarization.
- Empirical results demonstrate state-of-the-art outcomes on benchmarks like MoTIF-Automation and WebSRC, highlighting its scalability and adaptability.
ScreenAI: A Vision-LLM for UI and Infographics Understanding
ScreenAI is a specialized vision-LLM designed for comprehensive understanding of user interfaces (UIs) and infographics. This model advances upon the PaLI architecture by incorporating a flexible patching strategy, pix2struct, and leveraging a unique mixture of pretraining datasets. At its core, ScreenAI is tasked with interpreting complex visual information, identifying UI elements, and bridging multimodal understanding through a variety of generated datasets.
Architecture and Design
ScreenAI's architecture integrates an image encoder with a multimodal encoder that processes both embedded text and image features. The architecture is illustrated in (Figure 1), where images are first processed through an encoder, and subsequently coupled text features are fed into a multimodal encoder. The output is managed by an autoregressive decoder to generate coherent text outputs.
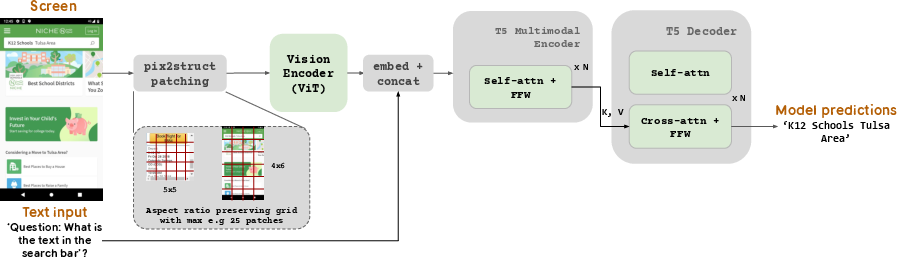
Figure 1: The overall architecture of our model, demonstrating the image encoder, multimodal processing, and autoregressive decoding along with pix2struct patching.
A pivotal component of ScreenAI is its use of pix2struct patching. Unlike fixed-grid patching, this method allows the grid size to adapt to the shape and aspect ratio of images, enhancing the model’s flexibility across diverse images.
Task Generation and Data Collection
The training of ScreenAI involves extensive task generation using screen annotations, LLMs, and self-supervision to create a robust dataset for pretraining. The task generation pipeline is depicted in (Figure 2), consisting of a process where screens are annotated, followed by task generation using LLMs, and optional data validation.

Figure 2: Task generation pipeline illustrating screen annotation, LLM utilization for task generation, and optional validation processes.
ScreenAI employs a self-supervised learning approach, combining outputs from models like DETR for screen annotation, PaLM 2-S for generating tasks, and efficient OCR engines for textual content extraction. These components enable the model to understand and generate UI-related data at scale, including question-answering, navigation, and summarization tasks.
Pretraining and Fine-tuning
The pretraining phase of ScreenAI is extensive, comprising over 400 million samples of tasks such as screen annotation, QA, navigation, and summarization, as highlighted by (Figure 3). This diversity ensures that ScreenAI can handle a variety of vision-language tasks effectively.

Figure 3: Sample tasks used in pretraining, including screen annotation, QA, navigation, and summarization, reflecting the model's broad capability.
ScreenAI’s fine-tuning process involves leveraging datasets both from public benchmarks and newly introduced datasets like Screen Annotation, ScreenQA Short, and Complex ScreenQA. These allow for comprehensive evaluation and benchmarking of model performance across diverse tasks like document VQA, screen summarization, and web-based structural reading comprehension.
Empirical Results
ScreenAI is benchmarked against state-of-the-art models on various screen and infographic tasks. It achieves state-of-the-art results on tasks such as MoTIF-Automation and WebSRC, and demonstrates competitive performance on others like DocVQA and ChartQA. Notably, ScreenAI's use of LLM-generated data significantly enhances its pretraining phase, contributing to superior outcomes in complex reasoning tasks related to UIs and infographics.
The model's scalability is shown as performance improves with increasing model size, indicating potential for further enhancements with ongoing developments.
Conclusion
ScreenAI represents a significant step forward in vision-language modeling for digital content understanding. Its integration of novel pretraining tasks, efficient data generation pipelines, and a flexible architecture enables it to surpass existing models in diverse benchmarks. ScreenAI not only excels in UI and infographic tasks but also opens new avenues for research in multimodal AI applications. Future work may focus on scaling model capabilities, optimizing data generation, and extending its application across broader domains of digital interaction.

