VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
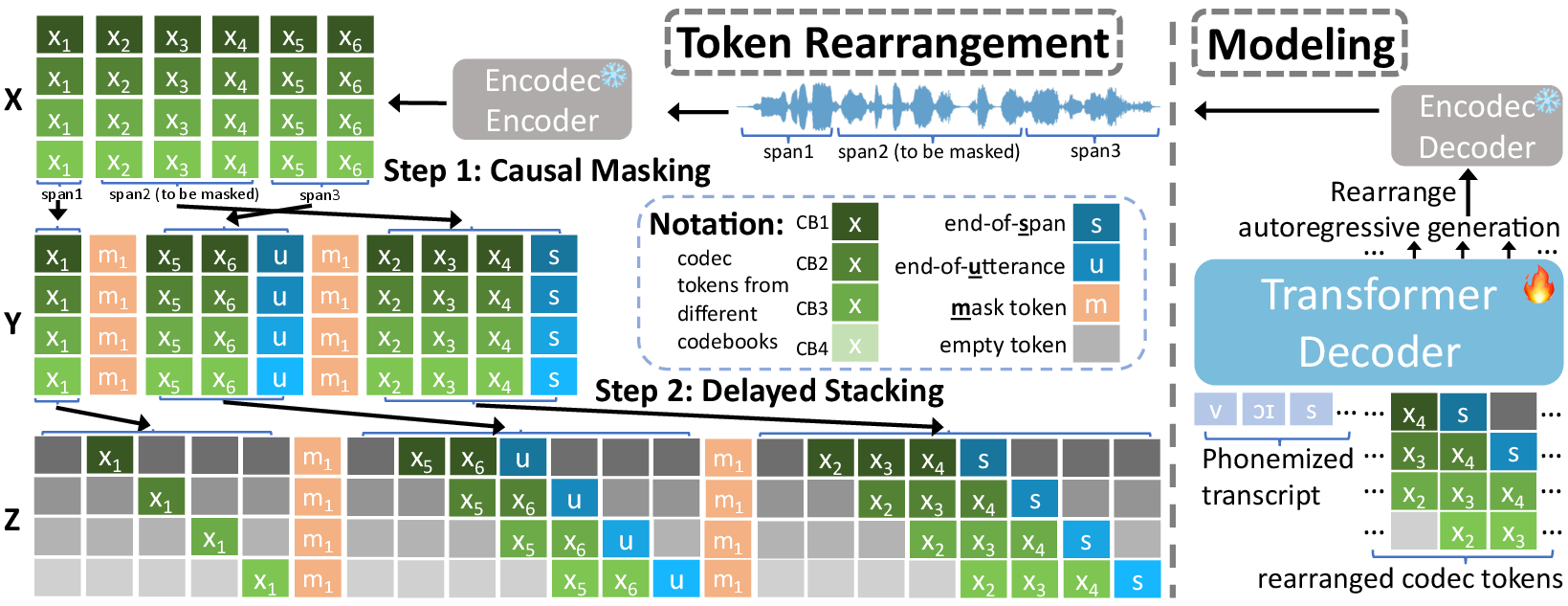
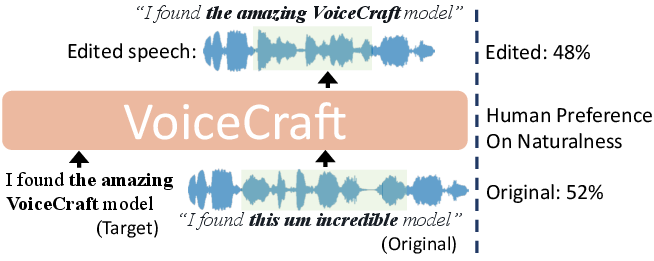
Abstract: We introduce VoiceCraft, a token infilling neural codec LLM, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
- Cm3: A causal masked multimodal model of the internet. ArXiv, abs/2201.07520.
- Musiclm: Generating music from text. ArXiv, abs/2301.11325.
- A3t: Alignment-aware acoustic and text pretraining for speech synthesis and editing. In International Conference on Machine Learning.
- Mathieu Bernard and Hadrien Titeux. 2021. Phonemizer: Text to phones transcription for multiple languages in python. Journal of Open Source Software, 6(68):3958.
- Audiolm: A language modeling approach to audio generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2523–2533.
- Speechpainter: Text-conditioned speech inpainting. In Interspeech.
- Soundstorm: Efficient parallel audio generation. ArXiv, abs/2305.09636.
- Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In International Conference on Machine Learning.
- Wavmark: Watermarking for audio generation. ArXiv, abs/2308.12770.
- Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio. In Proc. Interspeech 2021.
- Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16:1505–1518.
- 100,000 podcasts: A spoken English document corpus. In Proceedings of the 28th International Conference on Computational Linguistics, pages 5903–5917, Barcelona, Spain (Online). International Committee on Computational Linguistics.
- Simple and controllable music generation. ArXiv, abs/2306.05284.
- COQUI. 2023. Xtts v2. https://huggingface.co/coqui/XTTS-v2.
- High fidelity neural audio compression. ArXiv, abs/2210.13438.
- Singsong: Generating musical accompaniments from singing. ArXiv, abs/2301.12662.
- Unicats: A unified context-aware text-to-speech framework with contextual vq-diffusion and vocoding. In AAAI.
- Vall-t: Decoder-only generative transducer for robust and decoding-controllable text-to-speech.
- Vampnet: Music generation via masked acoustic token modeling. ArXiv, abs/2307.04686.
- Prompttts: Controllable text-to-speech with text descriptions. ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5.
- The curious case of neural text degeneration. In International Conference on Learning Representations.
- Text-free image-to-speech synthesis using learned segmental units. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021.
- Keith Ito and Linda Johnson. 2017. The lj speech dataset. https://keithito.com/LJ-Speech-Dataset/.
- Textrolspeech: A text style control speech corpus with codec language text-to-speech models. ArXiv, abs/2308.14430.
- Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias. ArXiv, abs/2306.03509.
- Fluentspeech: Stutter-oriented automatic speech editing with context-aware diffusion models. In Annual Meeting of the Association for Computational Linguistics.
- Voco: text-based insertion and replacement in audio narration. In International Conference on Computer Graphics and Interactive Techniques.
- Text-free prosody-aware generative spoken language modeling. ArXiv, abs/2109.03264.
- Speak, read and prompt: High-fidelity text-to-speech with minimal supervision. Transactions of the Association for Computational Linguistics, 11:1703–1718.
- Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. ArXiv, abs/2106.06103.
- Diederik P. Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. CoRR, abs/1412.6980.
- Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. ArXiv, abs/2010.05646.
- Audiogen: Textually guided audio generation. ArXiv, abs/2209.15352.
- Robert F. Kubichek. 1993. Mel-cepstral distance measure for objective speech quality assessment. Proceedings of IEEE Pacific Rim Conference on Communications Computers and Signal Processing, 1:125–128 vol.1.
- On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9:1336–1354.
- Voicebox: Text-guided multilingual universal speech generation at scale. ArXiv, abs/2306.15687.
- Feiteng Li. 2023. An unofficial pytorch implementation of vall-e. https://github.com/lifeiteng/vall-e.
- Promptstyle: Controllable style transfer for text-to-speech with natural language descriptions. ArXiv, abs/2305.19522.
- Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. In International Conference on Learning Representations.
- Daniel Lyth and Simon King. 2024. Natural language guidance of high-fidelity text-to-speech with synthetic annotations. ArXiv, abs/2402.01912.
- Matthias Mauch and Simon Dixon. 2014. Pyin: A fundamental frequency estimator using probabilistic threshold distributions. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 659–663.
- librosa: Audio and music signal analysis in python. In SciPy.
- Context-aware prosody correction for text-based speech editing. ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7038–7042.
- Generative spoken dialogue language modeling. Transactions of the Association for Computational Linguistics, 11:250–266.
- Robust speech recognition via large-scale weak supervision. ArXiv, abs/2212.04356.
- Language models are unsupervised multitask learners.
- Proactive detection of voice cloning with localized watermarking. ArXiv, abs/2401.17264.
- Ella-v: Stable neural codec language modeling with alignment-guided sequence reordering.
- Editspeech: A text based speech editing system using partial inference and bidirectional fusion. 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 626–633.
- Neural discrete representation learning. ArXiv, abs/1711.00937.
- Attention is all you need. In Neural Information Processing Systems.
- Neural codec language models are zero-shot text to speech synthesizers. ArXiv, abs/2301.02111.
- Context-aware mask prediction network for end-to-end text-based speech editing. ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6082–6086.
- Viola: Unified codec language models for speech recognition, synthesis, and translation. ArXiv, abs/2305.16107.
- Speechx: Neural codec language model as a versatile speech transformer. ArXiv, abs/2308.06873.
- Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92).
- Asvspoof 2021: accelerating progress in spoofed and deepfake speech detection. ArXiv, abs/2109.00537.
- Instructtts: Modelling expressive tts in discrete latent space with natural language style prompt. ArXiv, abs/2301.13662.
- Zipformer: A faster and better encoder for automatic speech recognition. In ICLR.
- Retrievertts: Modeling decomposed factors for text-based speech insertion. In Interspeech.
- Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507.
- Libritts: A corpus derived from librispeech for text-to-speech. In Interspeech.
- One-class learning towards synthetic voice spoofing detection. IEEE Signal Processing Letters, 28:937–941.
- Speak foreign languages with your own voice: Cross-lingual neural codec language modeling. ArXiv, abs/2303.03926.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.