- The paper presents a model-stealing attack that uses singular value decomposition to accurately recover hidden dimensions, exemplified by extracting 2048 latent dimensions from Pythia-1.4B.
- The methodology employs spike analysis on singular values to differentiate useful model information from numerical noise, ensuring precise dimension extraction.
- The research outlines practical defenses such as architectural modifications and noise introduction to mitigate vulnerabilities in API-exposed LLMs.
Introduction
The paper "Stealing Part of a Production LLM" (2403.06634) introduces a model-stealing attack capable of extracting significant architectural information from black-box LLMs like OpenAI's ChatGPT or Google's PaLM-2. Specifically, the attack successfully recovers embedding projection layers of transformer models through ordinary API access, achieving this with minimal financial cost. This work distinctly contributes to the study of adversarial attacks on AI systems by demonstrating that even proprietary models, kept behind APIs, can be targeted to retrieve valuable insights into their dimensional configurations.
Model-Stealing Attack Approach
Singular Value Decomposition (SVD)
The attack methodology hinges on singular value decomposition (SVD) to identify and extract the hidden dimensions of the LLMs. When executed, SVD reveals the base dimensionality of the model's final hidden layer by analyzing multiple output vectors. This process enables the precise determination of the embedding dimension, as demonstrated with the Pythia 1.4B model, where SVD accurately recovers its 2048 latent dimensions.
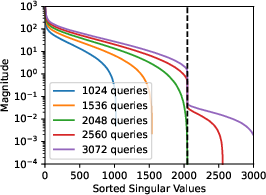
Figure 1: SVD can recover the hidden dimensionality of a model when the final output layer dimension is greater than the hidden dimension. Here we extract the hidden dimension (2048) of the Pythia 1.4B model. We can precisely identify the size by obtaining slightly over 2048 full logit vectors.
To refine this dimensionality extraction, the attack utilizes a spike analysis on the singular values obtained through SVD. A significant drop in singular values indicates the boundary between useful model information and numerical noise, allowing attackers to confidently ascertain the model's true dimension. This spike is visualized in its application to the Pythia-1.4B model.
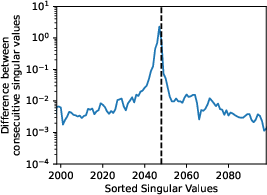
Figure 2: Our extraction attack recovers the hidden dimension size by looking for a sharp drop in singular values, visualized as a spike in the difference between consecutive singular values. On Pythia-1.4B, a 2048 dimensional model, the spike occurs at 2047 singular values.
Practical Implementation
Implementation of the attack relies on querying the model with various prompts and analyzing the corresponding output logit vectors. The assembling of these vectors into a matrix facilitates SVD, achieving direct insight into the model's dimensionality and projection matrix weight determination. The authors report precise extraction of embedding matrix dimensions with minimal error across various models, including potentially higher error scenarios in specific configurations, such as GPT-2 Small.
Model Configuration and Layer Extraction
The perturbation and manipulation of the API queries can lead to the recovery of low-level architectural details regarding normalization layers and final projection matrices. For model configurations employing LayerNorm or RMSNorm, these singular value analyses offer further insights, revealing whether LayerNorm biases are present within an API’s results:
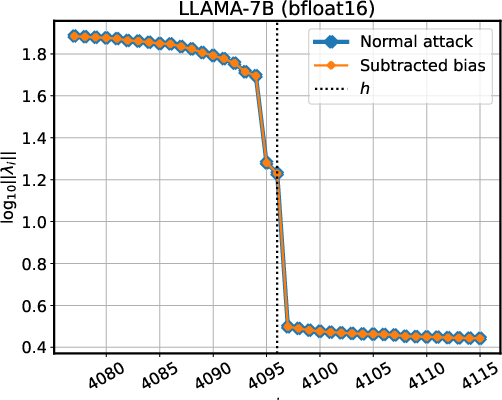
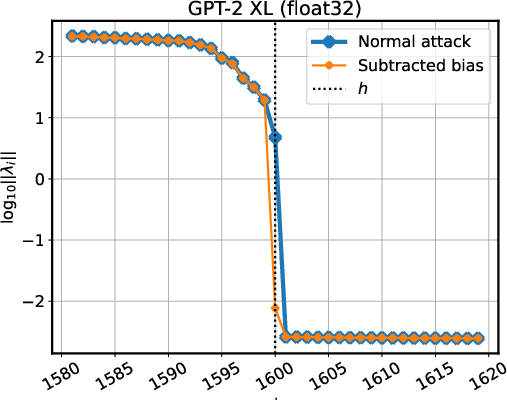
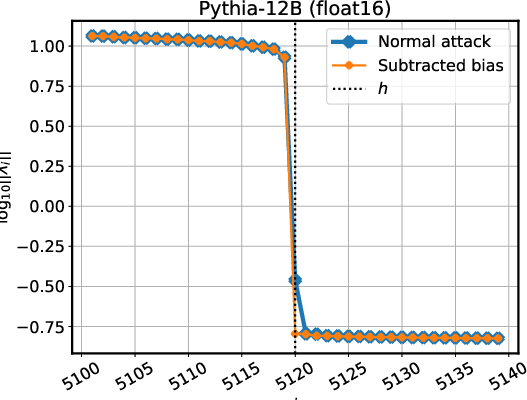
Figure 3: Detecting whether models use LayerNorm or RMSNorm by singular value magnitudes.
Further, stress tests depict vulnerabilities present within API-based access points, emphasizing the necessity for robust defensive measures:
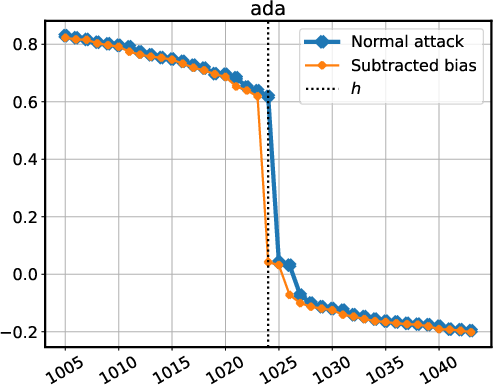
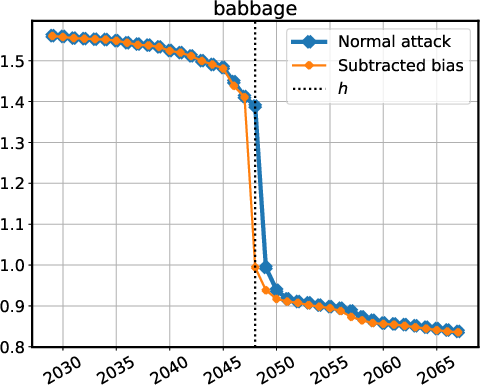
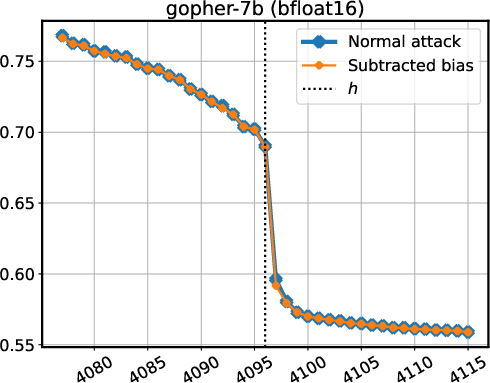
Figure 4: Stress-testing the LayerNorm extraction attack on models behind an API (a-b), and models using both RMSNorm and biases (c).
Defense Strategies
Architectural Modifications
The paper suggests potential future defensive architectures to mitigate exposure to such model-stealing attacks. These defensive measures proposed include breaking the projection layer into sub-layers incorporating nonlinearities, thus reducing susceptibility to the described attack methodology. Altering the architectural design post-hoc to accommodate defensive solutions forms part of a series of proposed mitigations.
Noise and Bias Restrictions
Implementing noise on output logits can obscure extraction accuracy significantly, posing challenges to confidentiality breaches. Moreover, restrictions on logit bias and logprob combinations serve as practical mitigations introduced by various model providers in response to demonstrated vulnerabilities.
Conclusion
The research delineated in this paper presents a viable attack vector on proprietary models, challenging prior assumptions regarding the security of production LLMs presented solely through API interfaces. By revealing architectural aspects previously considered clandestine through strategic querying and mathematical decomposition techniques, this research redefines the boundaries of model security. Consequently, the implications for model integrity, handling and confidentiality outline crucial considerations for AI model providers seeking to preserve intellectual property against such advanced attack methodologies. Researchers are encouraged to pursue subsequent work addressing the defenses against model extraction, reinforcing the collaborative efforts necessary to secure next-generation AI applications.