- The paper introduces CLAP, which enhances few-shot adaptation by blending zero-shot prototypes with adapted class representations using an Augmented Lagrangian Multiplier.
- It demonstrates robust performance in low-data regimes and superior domain generalization compared to state-of-the-art adapter methods.
- Findings highlight the challenges of hyperparameter tuning and propose a constraint-based strategy that reduces overfitting in few-shot scenarios.
Summary of "A Closer Look at the Few-Shot Adaptation of Large Vision-LLMs" (2312.12730)
Introduction to Few-Shot Adaptation in VLMs
The paper "A Closer Look at the Few-Shot Adaptation of Large Vision-LLMs" critically examines Efficient Transfer Learning (ETL) techniques designed to adapt large pre-trained Vision-LLMs (VLMs), such as CLIP, to downstream tasks using minimal labeled samples. Though existing methods demonstrate impressive results, they often rely on carefully tuning hyperparameters and exploiting large labeled datasets for model selection, making them impractical for real-world few-shot scenarios.
The authors identify two key empirical observations: first, state-of-the-art ETL methods consistently require task-specific hyperparameter optimization to surpass a simple Linear Probing baseline. Second, these methods often underperform compared to zero-shot predictions under distributional shifts. Addressing these challenges, a novel CLass-Adaptive linear Probe (CLAP) is proposed, which employs an Augmented Lagrangian Multiplier approach to balance initial zero-shot prototypes and adapted class representations.
Analysis of Transfer Learning Pitfalls
The paper highlights inherent issues in current ETL approaches. VLMs' reliance on substantial computational resources and extensive data for training limits frequent re-training. Consequently, adapting VLMs with limited labeled data remains challenging. To alleviate this, ETL methods incorporate adapters and prompts that modify input spaces or network layers with optimized weights. Despite these advances, overfitting and lack of generalization are prevalent due to reliance on small support sets.
Existing adapter methods, like CLIP-Adapter and TIP-Adapter, employ detailed hyperparameter tuning and use sizeable validation datasets, undermining their feasibility in genuine few-shot scenarios. These methods often fail when hyperparameters optimized for one task are applied to another, resulting in significant performance degradation.






Figure 1: Pitfalls of few-shot adapters due to the absence of a model selection strategy - Additional methods.
Revisiting Linear Probing
The paper proposes enhancements to Linear Probing by initializing class weights with zero-shot prototypes, scaling cosine similarity using pre-trained temperatures, and normalizing prototypes. Additionally, integration of data augmentation is considered essential for improved generalization.
Constrained Linear Probing
To mitigate prototype distortion during adaptation in the few-shot setting, a constrained optimization problem is formulated. This approach penalizes deviations from initial prototypes, leveraging a specially designed Augmented Lagrangian Multiplier method. The proposed penalty allows for adaptive class-wise constraint balancing, significantly aligning updated prototypes with initial robust zero-shot constructs.
CLAP: Class Adaptive Linear Probing
The CLAP approach introduces the Augmented Lagrangian Multiplier method to dynamically adjust class-specific penalty terms during adaptation. By learning penalty weights through support sets, CLAP aligns the adaptation process closer to real-world requirements, foregoing validation set dependence. This optimization strategy maintains prototype integrity, mitigating overfitting to unrepresentative support samples.
Experimental Results
Efficient Transfer Learning
The benchmark results reveal that a well-initialized Linear Probe competes robustly against complex adapter methods, especially in lower data regimes. CLAP outperforms existing approaches consistently, demonstrating reliable adaptation across diverse tasks and experimental setups.
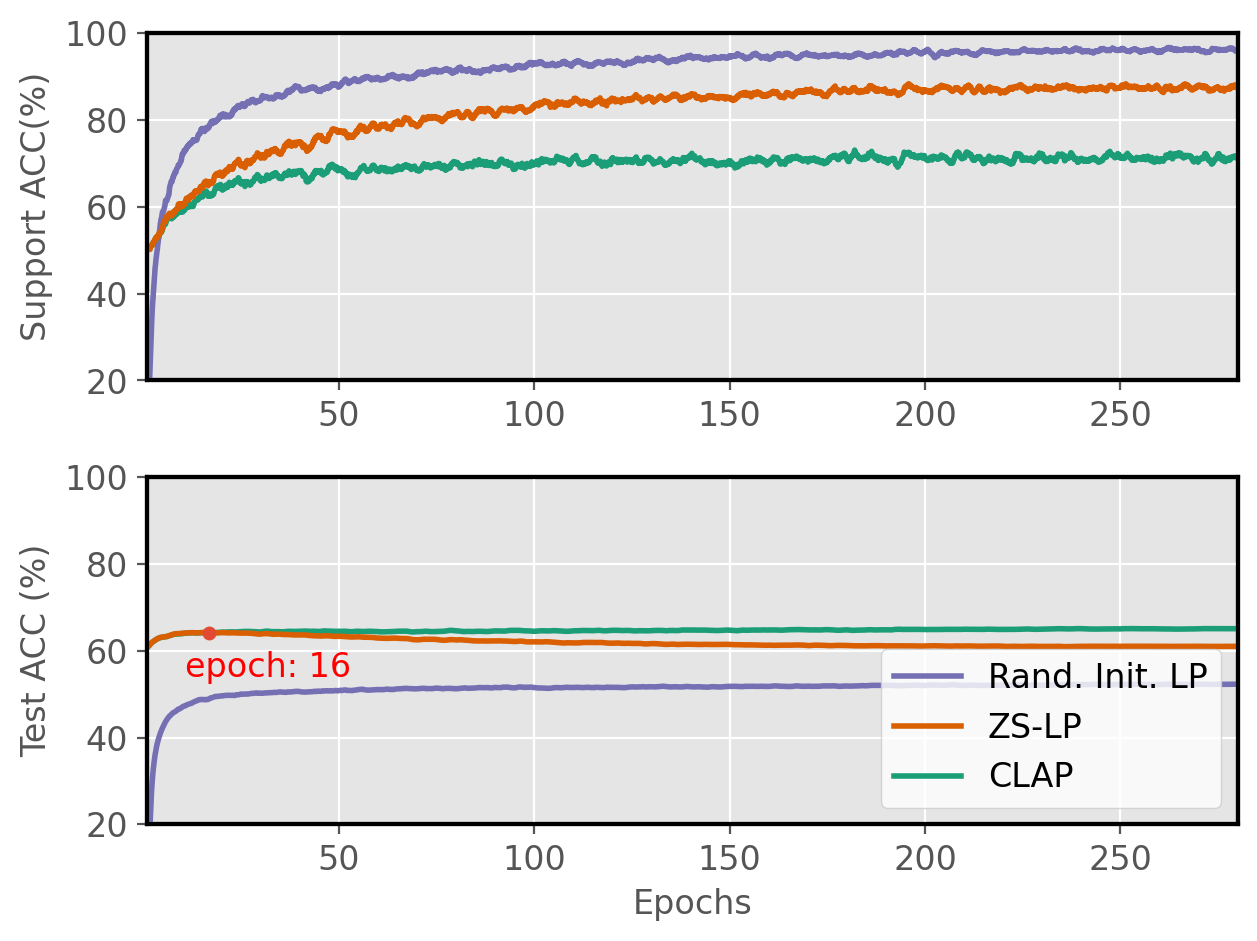
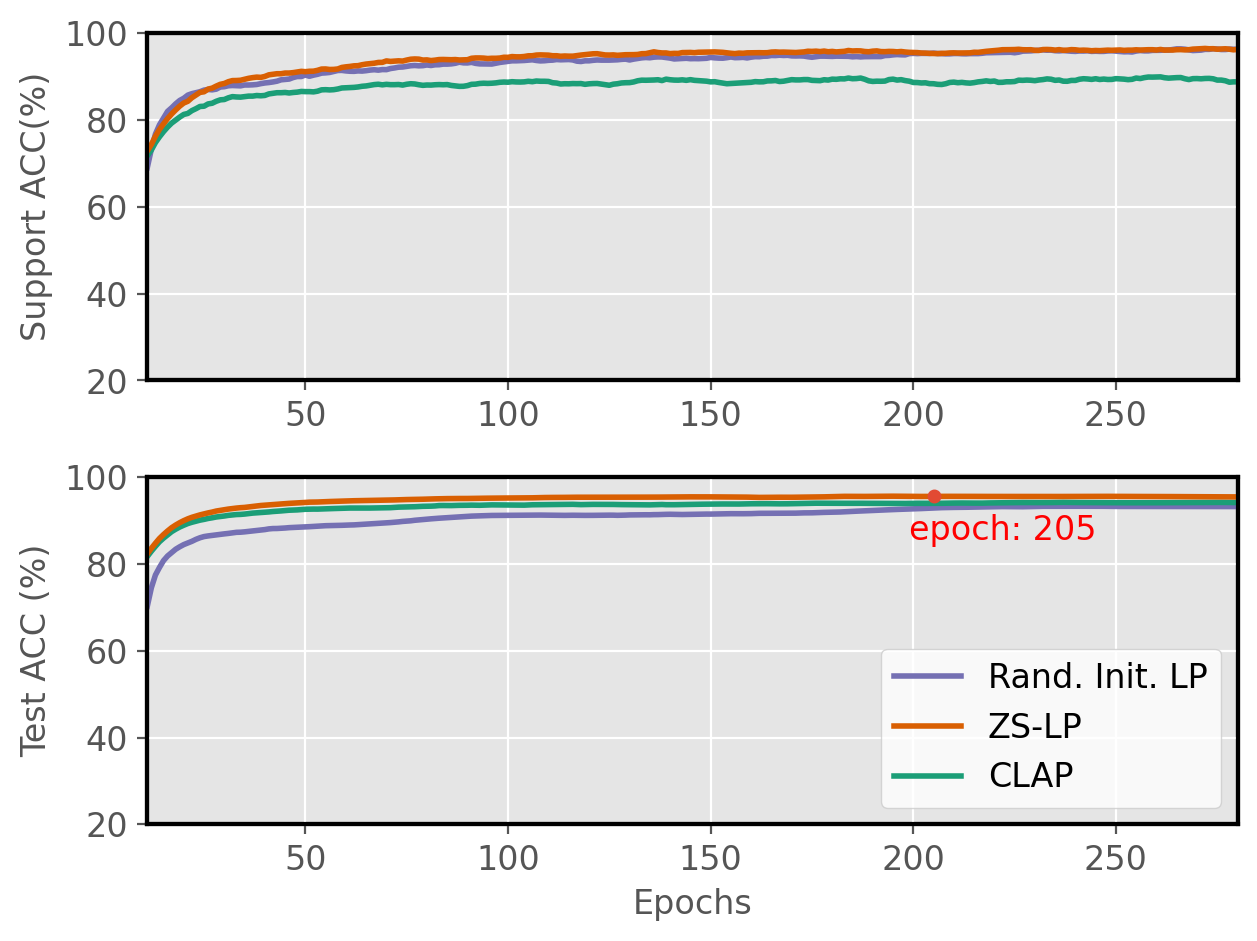
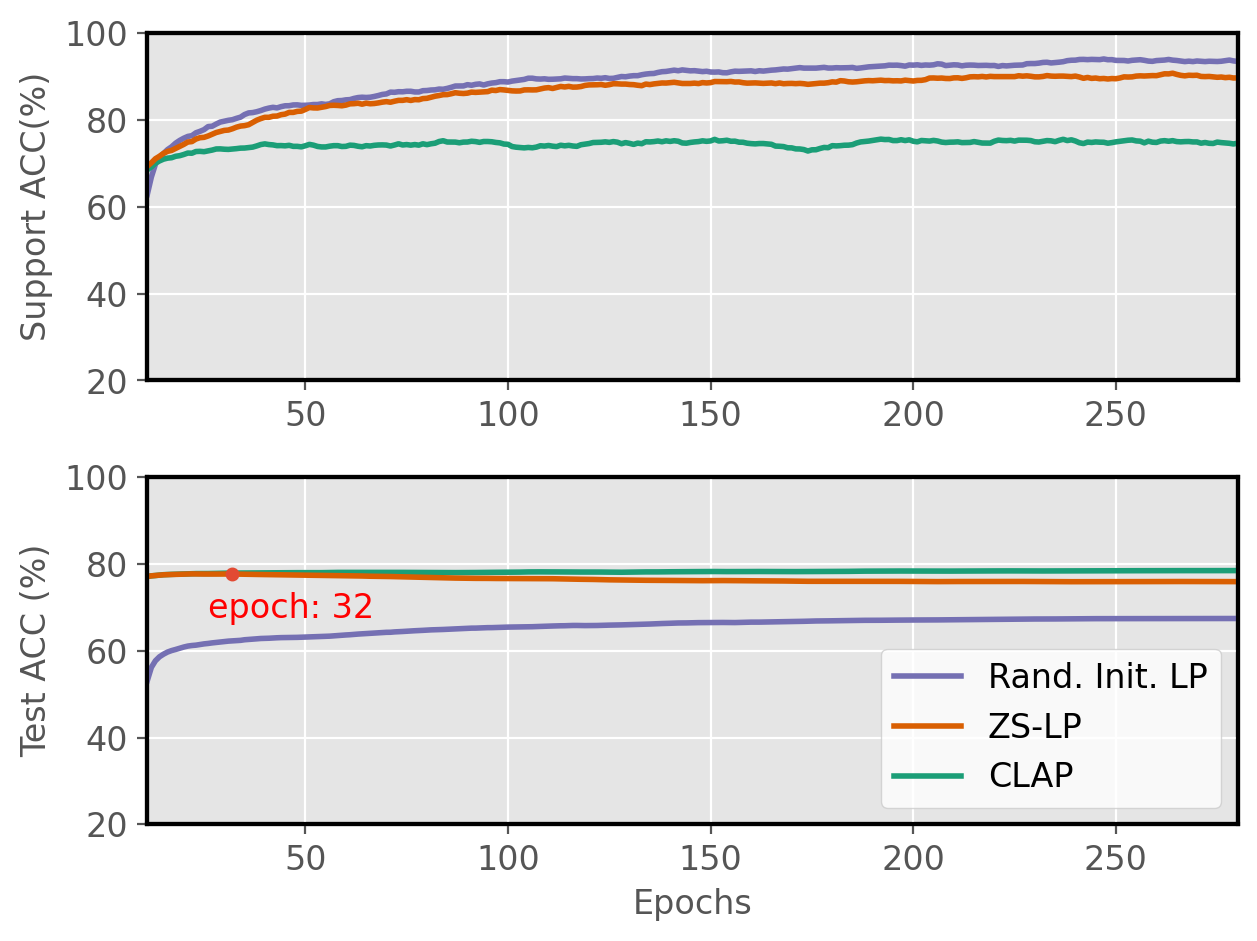
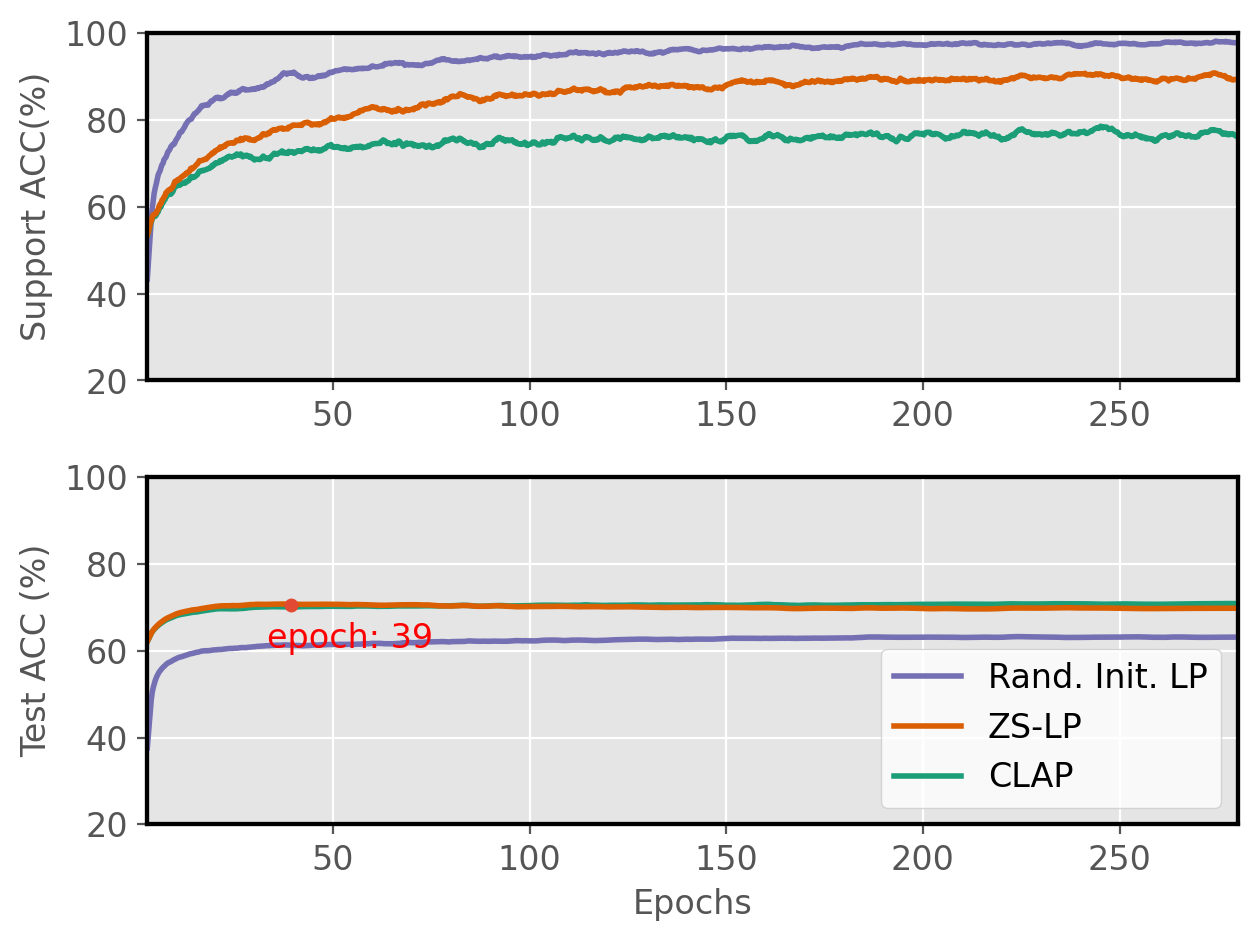
Figure 2: Linear Probing learning curves.
Domain Generalization
CLAP exhibits superior performance in domain generalization, maintaining consistency across various out-of-distribution shifts. While adapter methods falter against zero-shot benchmarks, CLAP’s constraint strategy sustains robust generalization in unseen domains.
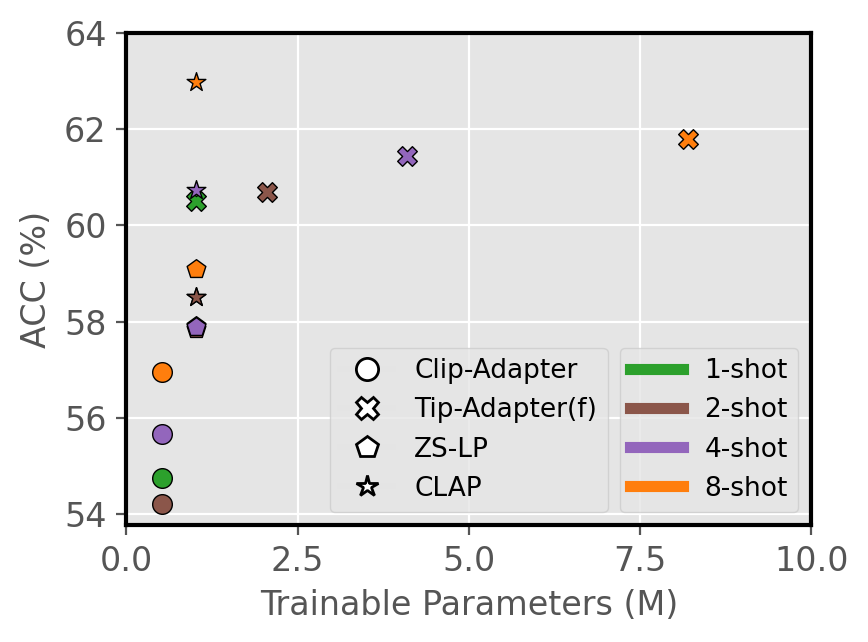
Figure 3: Trade-off between number of shots, trainable parameters, and adaptation performance.
Conclusion
In summary, the paper proposes a novel class-adaptive approach for few-shot VLM adaptation, showcasing consistent performance improvements without reliance on extensive validation sets. CLAP’s adaptive mechanism empowers efficient transfer learning, reducing overfitting risks and facilitating realistic application scenarios. The approach significantly contributes to aligning adaptation methodologies with real-world conditions while maintaining competitive edge in few-shot and domain generalization tasks.
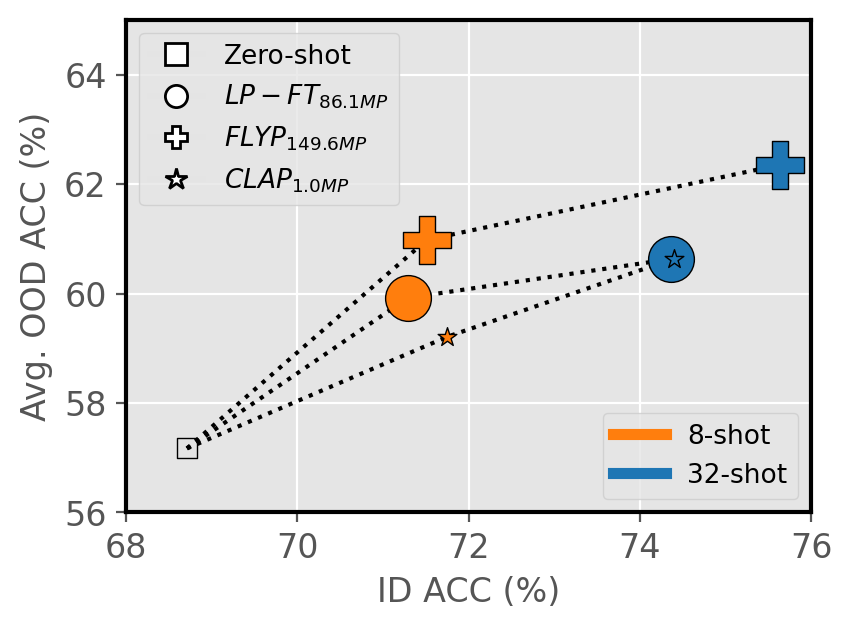
Figure 4: Finetuning (FT) vs. efficient transfer learning (ETL), performance and trainable parameters.
The implications of this research not only improve practical VLM adaptation strategies but also pave the way for future investigations into privacy-oriented and resource-efficient model deployment.