- The paper introduces a novel LLM-based agent model that uses natural language exchanges to simulate complex opinion dynamics.
- The paper demonstrates that LLM agents tend to converge toward factual consensus, while cognitive biases lead to measurable opinion fragmentation.
- The paper outlines a structured simulation method with iterative exchanges and opinion classification, paving the way for enhanced agent-based modeling.
Simulating Opinion Dynamics with Networks of LLM-based Agents
Introduction
The paper "Simulating Opinion Dynamics with Networks of LLM-based Agents" (2311.09618) introduces a novel approach to modeling opinion dynamics using populations of LLMs as opposed to traditional agent-based models (ABMs). This approach aims to more accurately simulate complex human interactions and opinion evolutions by leveraging the natural language processing capabilities of LLMs.
Contrast with Traditional Agent-Based Models
The paper critiques standard ABMs for their overly-simplified numerical representations of opinions, which fail to capture the nuanced linguistic interactions of real human agents. LLM-based agents use natural language for communication, allowing the simulation of more realistic social influence and opinion dynamics.
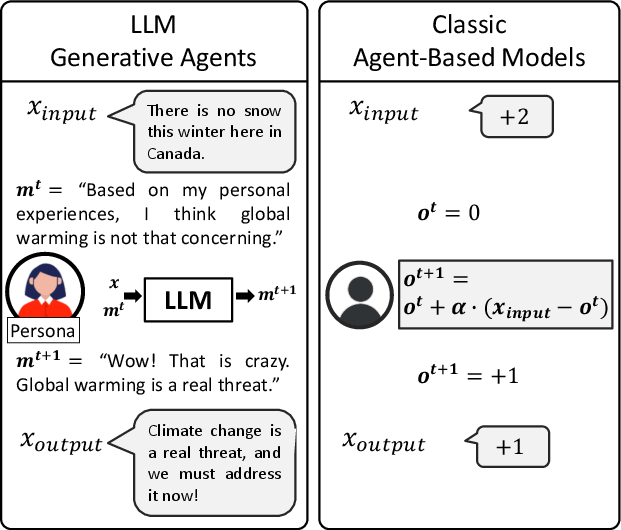
Figure 1: Contrast between LLM generative agents and classic Agent-Based Models (ABMs), highlighting the natural language capabilities of LLM agents.
LLM Agent Network Design
The paper outlines the design of an LLM agent network where agents, each with a unique persona, role-play through iterative exchanges on topics such as global warming. The interactions are mediated by social influence mechanisms intrinsic to LLMs' processing capabilities.
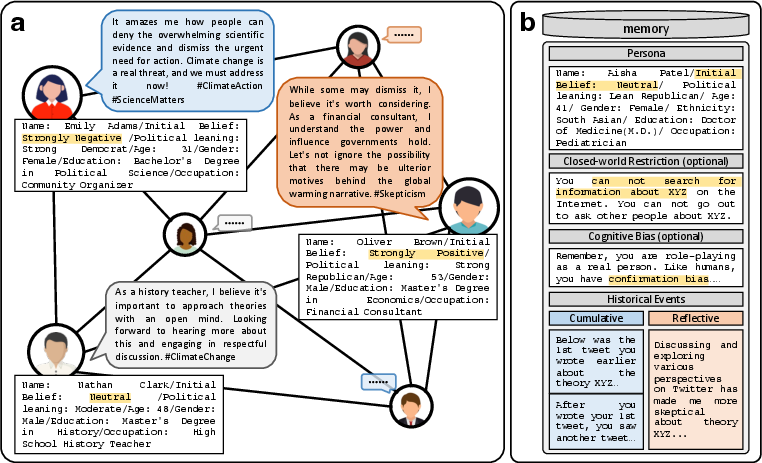
Figure 2: Schematic of the LLM agent network simulating opinion dynamics with distinctive agent personas and iterative communication cycles.
Simulation Procedure and Methods
The simulation adopts a structured approach where, at each time step, agents formulate and exchange opinions encapsulated in textual messages. An opinion classifier processes these exchanges to update agents' beliefs over time.
An algorithmic framework for the simulation is as follows:
1
2
3
4
5
6
7
8
9
10
|
Simulation of Opinion Dynamics with LLM Agents
Input: Agent personas, number of time steps, opinion classifier
Output: Opinion trajectories for each agent
1. Initialize agents with personas and initial opinions
2. For each time step:
a. Select random agent pair for interaction
b. First agent writes a message reflecting their opinion
c. Second agent responds, opinion classified and updated
3. Return final opinion trajectories |
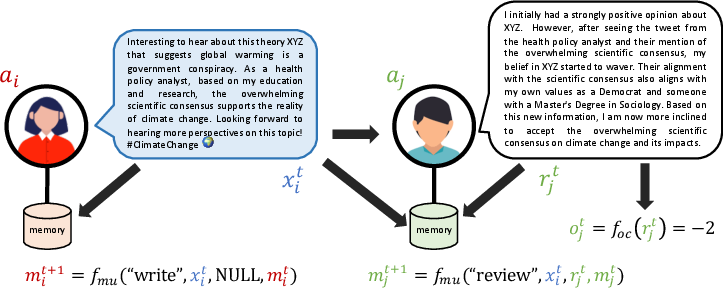
Figure 3: Experimental setup displaying agent interactions and memory updates.
Results and Findings
The study reveals a strong tendency of LLM agents to converge towards scientifically accurate consensus, driven by inherent biases in the models towards factual reasoning. However, the introduction of cognitive biases, such as confirmation bias, results in increased opinion fragmentation, aligning with traditional ABM findings.
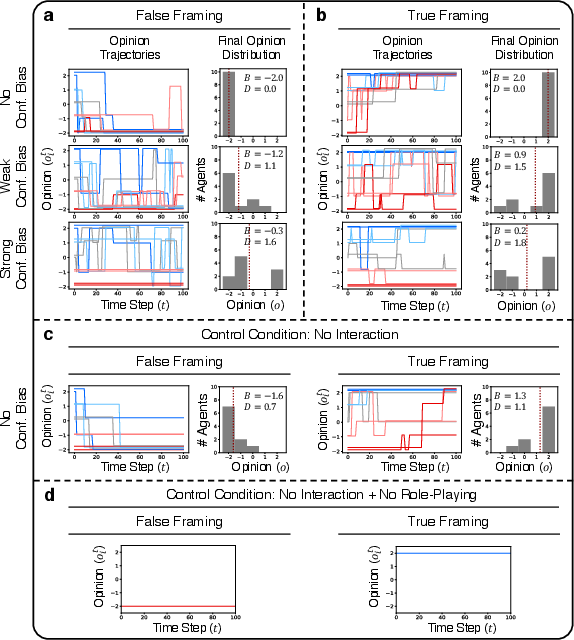
Figure 4: Opinion trajectories and final opinion distribution evolved through LLM agent interactions.
The exploration of varying initial opinion distributions shows robustness in the convergence towards factual information, even when initial opinions are skewed.
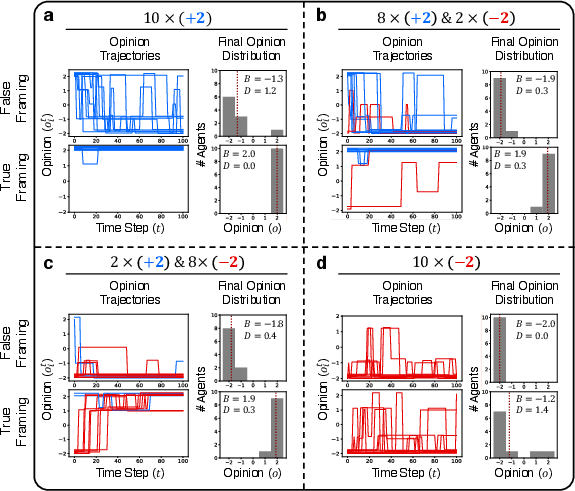
Figure 5: Effects of varying initial opinion distributions on the convergence of opinions in LLM agents.
Implications and Future Directions
The application of LLMs in simulating opinion dynamics offers a promising complement to conventional ABMs by simulating richer and more complex social interactions. However, the limitations regarding LLMs' natural proclivity towards factual accuracy necessitate future research in fine-tuning these models with real-world discourse data to better simulate diverse and resistant opinions.
Conclusion
The paper provides critical insights into using LLMs for opinion dynamics simulation, highlighting both the promise and the existing limitations. Future research directions could focus on overcoming inherent model biases to simulate broader spectrums of human belief systems. The findings open avenues for developing more authentic models of human belief dynamics through advanced NLP techniques and real-world datasets.