Spectral Properties of Elementwise-Transformed Spiked Matrices
Published 3 Nov 2023 in math.ST | (2311.02040v3)
Abstract: This work concerns elementwise-transformations of spiked matrices: $Y_n = n{-1/2} f( \sqrt{n} X_n + Z_n)$. Here, $f$ is a function applied elementwise, $X_n$ is a low-rank signal matrix, and $Z_n$ is white noise. We find that principal component analysis is powerful for recovering signal under highly nonlinear or discontinuous transformations. Specifically, in the high-dimensional setting where $Y_n$ is of size $n \times p$ with $n,p \rightarrow \infty$ and $p/n \rightarrow γ> 0$, we uncover a phase transition: for signal-to-noise ratios above a sharp threshold -- depending on $f$, the distribution of elements of $Z_n$, and the limiting aspect ratio $γ$ -- the principal components of $Y_n$ (partially) recover those of $X_n$. Below this threshold, the principal components of $Y_n$ are asymptotically orthogonal to the signal. In contrast, in the standard setting where $X_n + n{-1/2}Z_n$ is observed directly, the analogous phase transition depends only on $γ$. A similar phenomenon occurs with $X_n$ square and symmetric and $Z_n$ a generalized Wigner matrix.
The paper establishes that PCA reliably recovers low-rank signals in nonlinear elementwise-transformed spiked matrices when the signal-to-noise ratio exceeds a computed threshold.
It introduces an analytical framework using orthogonal polynomial expansions to quantify how nonlinear transformations impact the eigenvalue spectrum.
The study provides optimal preprocessing strategies and eigenvalue shrinkage rules, validated by simulations on diverse non-Gaussian and discrete datasets.
Spectral Analysis of Nonlinear Elementwise-Transformed Spiked Matrices
Problem Setup and Motivation
The study addresses the spectral behavior of "elementwise-transformed spiked matrices" of the form Yn=n−1/2f(nXn+Zn), where Xn is a deterministic low-rank signal matrix and Zn is additive white noise. This model generalizes the classical high-dimensional spiked matrix framework by including a nonlinear, possibly discontinuous, transformation f applied entrywise. Such structures naturally arise in data with non-Gaussian, discrete, truncated, or otherwise preprocessed entries, including genomic count matrices and activations in neural networks.
The text contrasts this model with the classical setting (no transformation) where the presence and alignment of outlier singular values and vectors follow universal behaviors (e.g., the BBP phase transition) determined only by the limiting aspect ratio γ and the signal-to-noise ratio, as captured by the Marchenko-Pastur (asymmetric) or semicircle (symmetric) laws.
Main Theoretical Results
The work proves that, even after strong nonlinearities or discontinuities, PCA remains a statistically powerful method for signal recovery—provided the signal strength and the nonlinear transform f meet certain quantitative thresholds. A central feature is a sharp spectral phase transition: above a critical signal-to-noise threshold (depending on f, the distribution μ of Zn, and γ), the principal components of Yn align with those of Xn; below this threshold, the principal components become orthogonal in the infinite-dimensional limit.
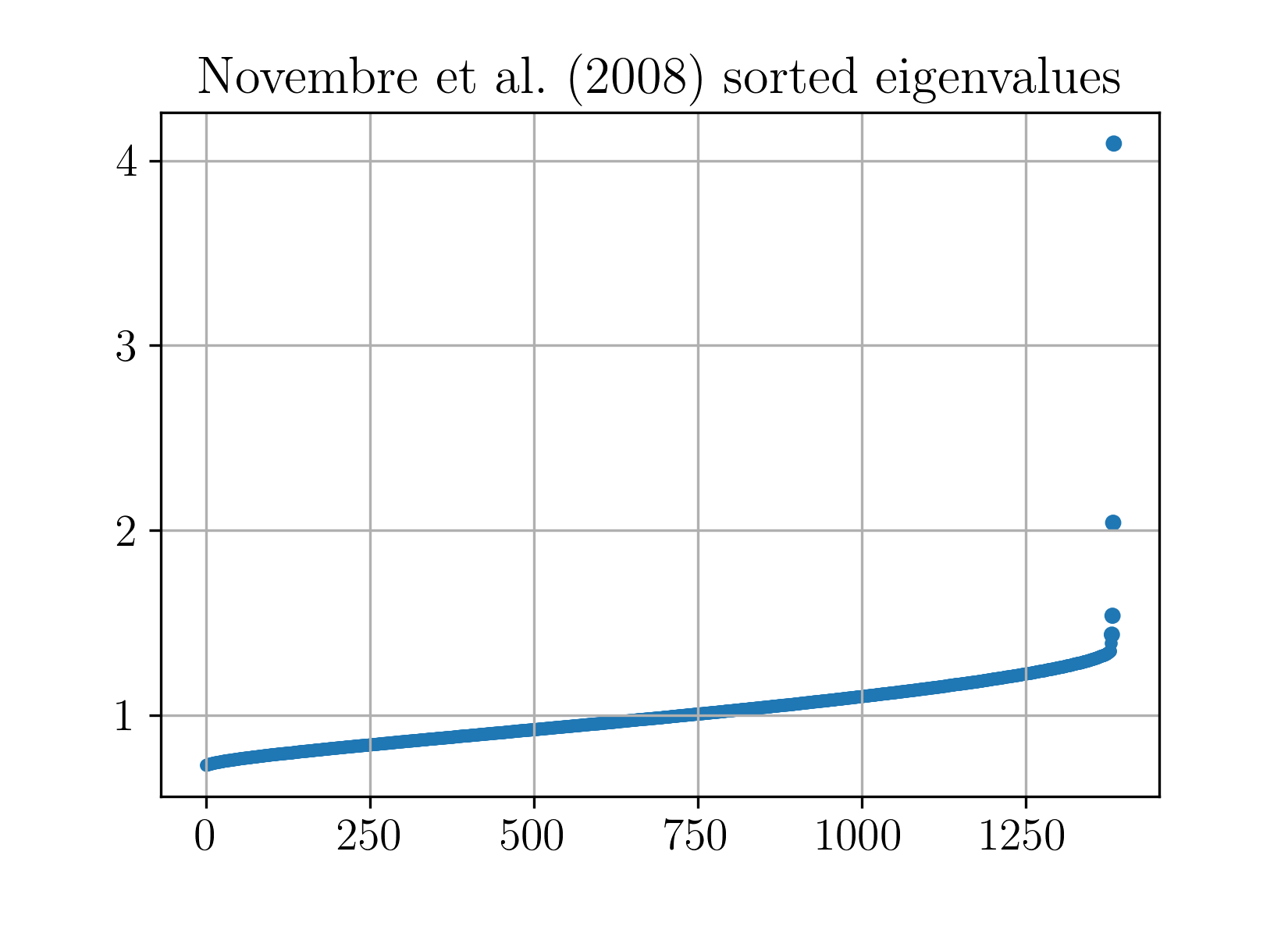
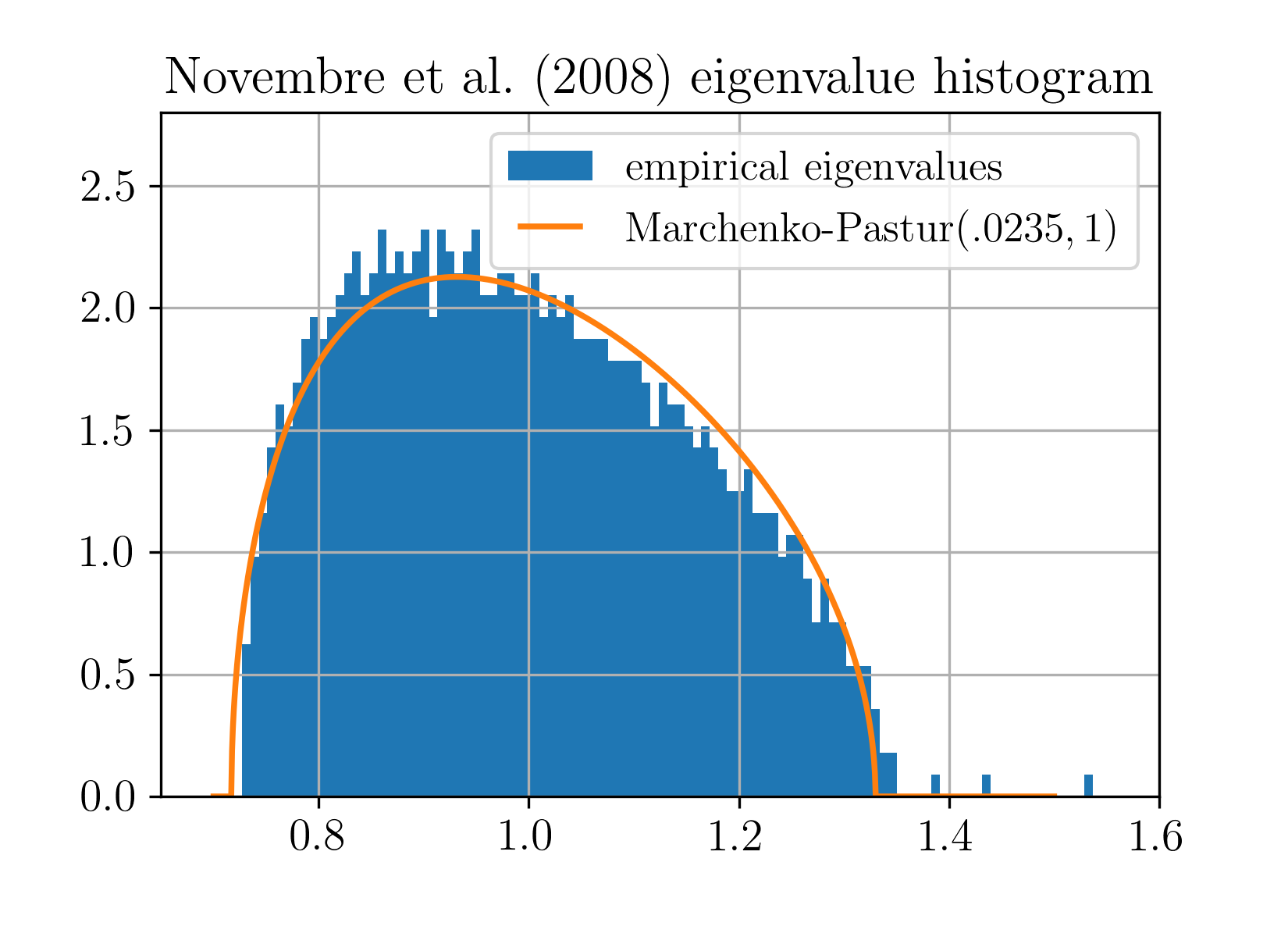
Figure 1: The eigenvalues of the sample covariance of discrete genetic data map closely to the Marchenko-Pastur law, even though the data is fundamentally non-Gaussian and discrete-valued.
This threshold is characterized by a constant τ(f,μ) determined by an orthogonal polynomial expansion of f with respect to μ, reflecting how both the nature of the nonlinear transformation and the underlying noise distribution impact spectral recoverability.
High-Dimensional Limit and Phase Transition
In the traditional spiked model, the PCA recovery threshold is a function of only γ, independent of further model specifics. For the nonlinear model, the threshold becomes γ1/4/τ(f,μ), revealing that PCA's alignment relies intricately on both f and the noise law.
When τ(f,μ)=0 (e.g., certain highly-oscillatory or mean-zero transformations), the threshold scaling requires higher signal strength, and the first nonzero higher-order coefficient in the expansion governs asymptotic spectral behavior.
All main results hold for both asymmetric (rectangular) and symmetric (Wigner) matrix ensembles.
Analytical Framework and Proof Techniques
Key to the analysis is expanding f in a system of polynomials {qk} orthogonal with respect to the law μ of the noise, expressing f as f(z)=∑k=1∞akqk(z). The dominant term in the asymptotic spectral expansion is then determined by τ(f,μ)=∥f∥μ−1k=1∑∞akbk, where bk=⟨qk′,1⟩μ quantifies how derivatives of the basis functions interact with the measure μ. This technical machinery extends and unifies prior kernel random matrix results and the spectral theory of linear spiked models.
Applications and Algorithmic Implications
Discrete, Truncated, and Preprocessed Data
A principal application is the justification of PCA for transformed or discretely valued data, such as binomial or binary count matrices relevant in genomics and social science, where the model directly describes high-dimensional datasets like those in [N08]. Here, PCA consistently identifies latent structure, and the empirical spectrum closely tracks the Marchenko-Pastur distribution, even without approximate normality of the data.
Activation nonlinearities: For f(z)=max(z,0) (ReLU), the model describes data with systematically missing negative entries. The analysis yields precise formulas: e.g., under Gaussian noise, the recovery threshold for PCA increases by a factor of 2(π−1)/π.
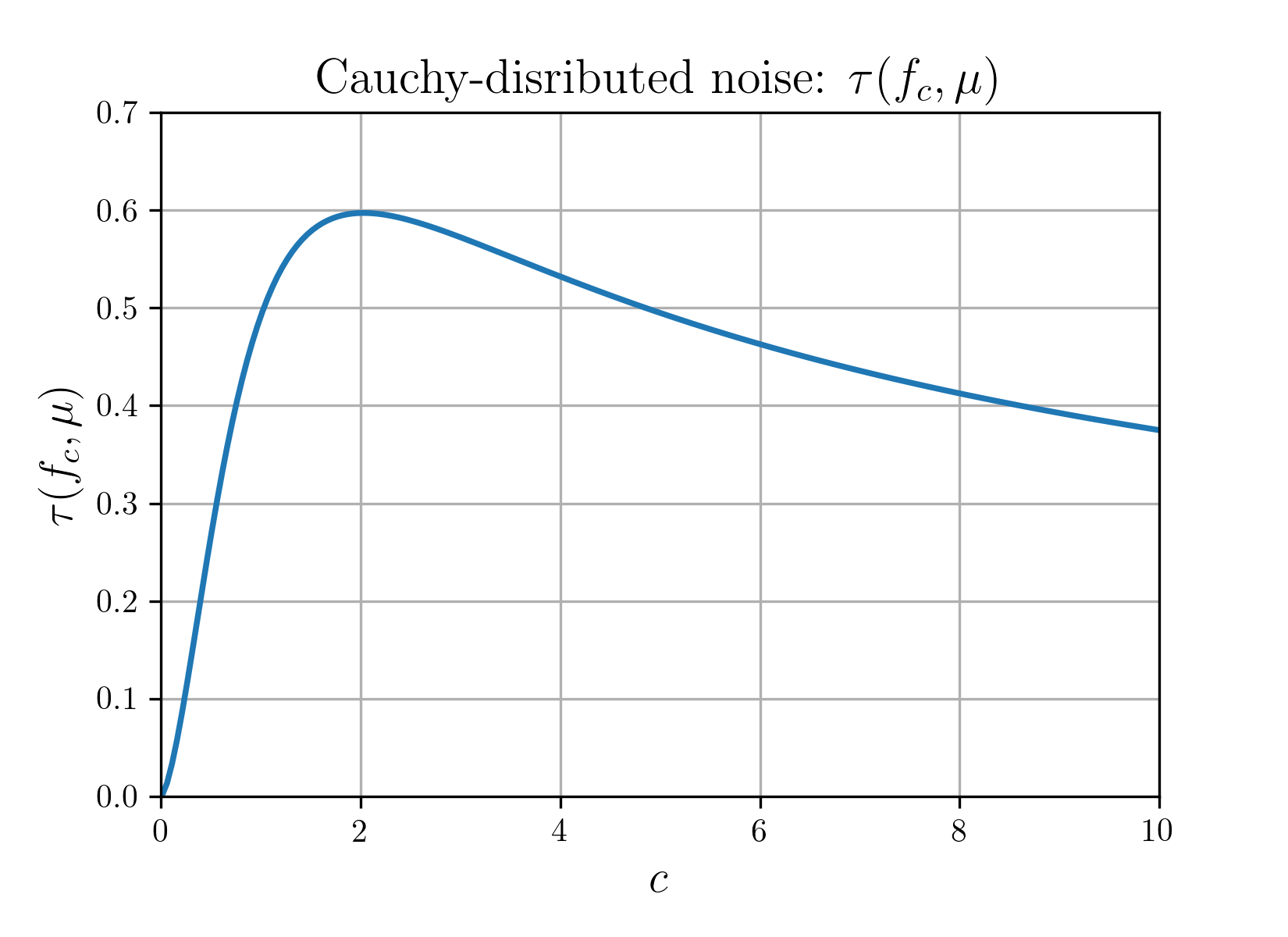
Truncated observations: For fc(z)=zI(∣z∣≤c), the effect of truncation varies dramatically by the tail properties of μ. Under Cauchy noise, the work provides and analyzes an explicit optimal truncation level that recovers the BBP-like transition that is otherwise lost without transformation.
Heteroskedastic and Binomial data: For yij∼Bin(m,logistic(xij)), the spectral edge and the alignment of principal components with the signal can be computed and are confirmed in simulation.
Optimal Preprocessing and Eigenvalue Shrinkage
The analysis also derives the optimal entrywise transform f∗ that maximizes τ(f,μ) when μ is known, generalizing eigenvalue shrinkage and singular value denoising results for inference under arbitrary noise. The optimal f∗ is given by f∗(z)=ω′(z)/ω(z) (where ω is the noise density), corresponding to maximizing Fisher information. This reduces the recovery threshold below the standard universal values for non-Gaussian settings.
Additionally, the work extends the optimal singular value shrinkage rules for estimating Xn under operator norm loss from classical to nonlinear-transformed spiked models, showing the minimax estimator remains optimal when applied to Yn.
Numerical and Simulation Validation
Extensive simulations validate the theoretical predictions: recovery phase transitions, spectral distributions, and alignment of empirical principal components with signal subspaces match analytic results across a range of nonlinearities, preprocessing schemes, and noise types.
Figure 2: Left panel (not shown) demonstrates the agreement between empirical and theoretical cosine similarities for various nonlinear transformation and noise regimes.
Implications and Future Prospects
This work fundamentally clarifies the behavior of PCA for data subjected to arbitrary monotonic or discontinuous preprocessing, justifying the use of linear spectral methods for a much broader class of high-dimensional data. The explicit criteria on f and μ allow principled selection of preprocessing strategies or imputation methods when data has missingness, truncation, or discrete noise—all prevalent in modern applications.
Open research directions include extending these results to other spectral inference methods (e.g., robust and nonlinear PCA variants), characterizing finite-sample corrections, and automatic selection or learning of the optimal elementwise transform in settings where μ is unknown or estimated.
Conclusion
The paper rigorously establishes the spectral landscape of elementwise-transformed spiked random matrices, providing precise phase transition characterizations and optimality results for PCA and related estimators beyond the classical linear Gaussian paradigm. Its framework enables theoretically justified spectral inference for complex, preprocessed, or discrete data in high-dimensional regimes (2311.02040).