- The paper introduces DF-TransFusion, a multimodal framework combining audiovisual data with cross-attention and self-attention for robust deepfake detection.
- It utilizes a fine-tuned VGG-16, transformer encoders, and cuboid embedding to capture spatio-temporal features and lip-audio synchronization anomalies.
- Results demonstrate superior performance with an AUC of 0.979 on DFDC and a perfect score on DF-TIMIT, highlighting its practical effectiveness.
DF-TransFusion: Multimodal Deepfake Detection via Lip-Audio Cross-Attention and Facial Self-Attention
The paper "DF-TransFusion: Multimodal Deepfake Detection via Lip-Audio Cross-Attention and Facial Self-Attention" (2309.06511) introduces a sophisticated deepfake detection framework that processes both audio and video data. Using cross-attention and self-attention mechanisms, it aims to accurately detect manipulated content involving both lip synchronization and visual artifacts.
Introduction
Deepfake technologies exploit deep learning capabilities, particularly GANs, for the generation of fake media content, posing threats to privacy, authenticity, and security. Conventional detection methods predominantly focus on either video or audio. However, this paper addresses the limitation by proposing a multimodal approach that enhances detection accuracy through the integration of audio-visual data.
Several deepfake generation tools such as FaceSwap and DeepFaceLab have facilitated the creation of highly realistic fake media. Given the evolving abuse of these technologies, there's a pressing need for advanced detection mechanisms leveraging sophisticated computational models.
Methodology
Architecture Overview
The DF-TransFusion model architecture integrates fine-tuned VGG-16 networks and transformer encoders to perform both facial self-attention and lip-audio cross-attention.
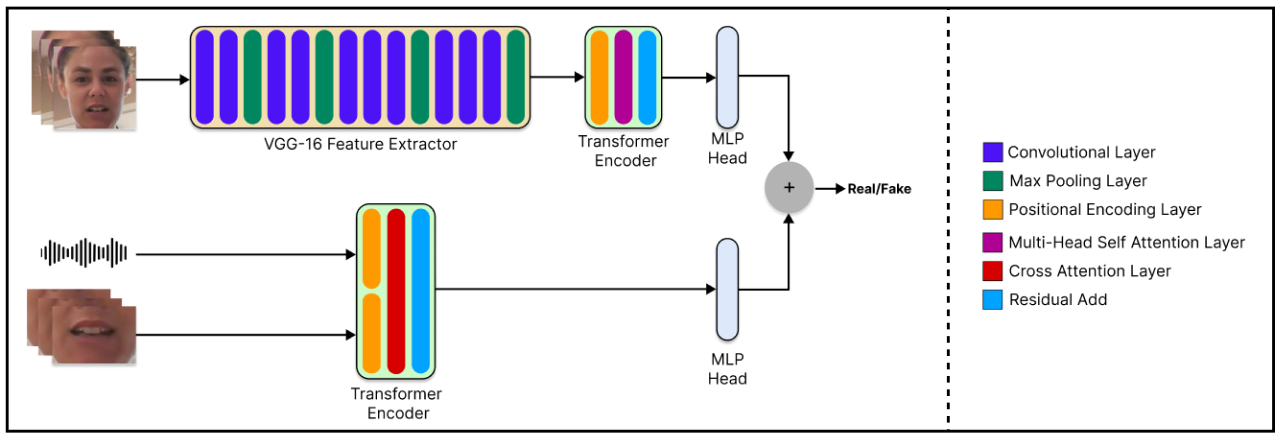
Figure 1: Our model architecture shows input video frames, audio and lip region along with fine-tuned VGG-16 feature extractor, transformer encoders, and multi-layer perceptron heads.
Video inputs are processed through VGG-16 for feature extraction, which is followed by capsule-based embedding techniques to capture spatial and temporal properties. The architectural pipeline employs self-attention mechanisms for analyzing video discrepancies, while cross-attention mechanisms disentangle lip-audio synchronization anomalies.
Cuboid Embedding
The cuboid embedding technique plays a crucial role in enhancing spatio-temporal analysis, allowing the model to efficiently process video data by creating higher-dimensional representations. It serves to encompass both spatial layouts and temporal sequences.
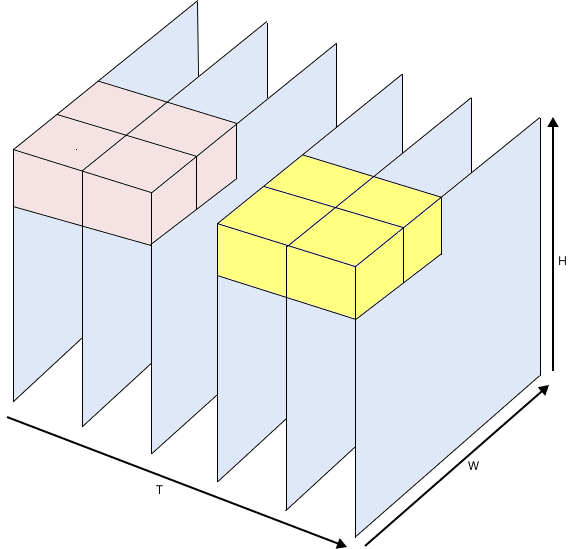
Figure 2: Cuboid Embedding for spatio-temporal 3-D Attention
Cross-Attention Mechanism
Cross-attention is implemented by simultaneously considering lip regions and audio signals to examine synchronization inconsistencies. Two sets of linear layers adjust the dimensions of inputs from different modalities, facilitating effective cross-modal interactions without compromising temporal integrity.
Results
Quantitative Evaluation
The experimental results demonstrate the superiority of DF-TransFusion over thirteen baseline models across three datasets: DFDC, DF-TIMIT, and FakeAVCeleb.
The multimodal method achieves an AUC score of 0.979 on the DFDC dataset and a perfect 1.000 on DF-TIMIT, underscoring its robustness in detecting deepfakes across diverse scenarios.
Qualitative Evaluation
The model is tested with in-the-wild video sources to assess its performance under real-world conditions.

Figure 3: Qualitative Results: We show some sample frames from the DFDC, FakeAVCeleb, and DF-TIMIT that the model uses during training and testing. Our model uses both audio-video modality and the cross-attention between the two modalities to classify as real and fake videos.
Future Work
Although DF-TransFusion sets a new benchmark in deepfake detection, there remain challenges such as class imbalance within datasets and handling multi-speaker scenarios. Future research should focus on improving model adaptability to varied environmental conditions and noisy data.
Additionally, advancements in real-time applications and integration with IoT systems could further enhance deepfake detection capabilities, mitigating security risks in more proactive scenarios.

Figure 4: Evaluation on In-The-Wild Videos: To evaluate the robustness of our model, we tested it on out-of-dataset videos. Our model correctly detected sample videos downloaded from Youtube, MIT Deepfake Lab, and other public sources.
Conclusion
DF-TransFusion exemplifies the potential of leveraging multimodal data for superior deepfake detection. Its innovative use of cross-attention and self-attention mechanisms to analyze lip-audio synchronization and facial anomalies sets it apart from existing methodologies. Despite its significant advancements, the quest for optimized real-time detection in diverse contexts continues to drive future research landscapes.