- The paper introduces CoELA, a modular framework integrating perception, memory, planning, communication, and execution for cooperative embodied agents.
- It employs LLMs for decentralized decision-making in multi-objective tasks, demonstrating around 40% efficiency gains over baseline models.
- The framework is validated on complex tasks in TDW-MAT and C-WAH environments, highlighting improved human-agent interactions and robust collaboration.
Building Cooperative Embodied Agents Modularly with LLMs
This study presents a novel approach to building cooperative embodied agents utilizing LLMs in complex multi-agent environments. The focus of the research is to address the challenges surrounding decentralized control, costly communication, and multi-objective tasks without the reliance on cost-free communication channels or centralized controllers with shared observations.
Introduction and Motivation
Recent advancements in LLMs have demonstrated capabilities in language understanding, reasoning, dialogue generation, and world knowledge. These capabilities can be leveraged to tackle the challenges of embodied multi-agent cooperation. The paper proposes a cognitive-inspired modular framework named Cooperative Embodied Language Agent (CoELA), designed to incorporate perception, memory, planning, and execution within a multi-agent setting.
The main goal is to validate whether LLMs can effective cooperative planning and efficient communication amidst decentralized settings. Two primary environments, ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH), serve as testbeds. These environments challenge agents with tasks demanding efficient multi-agent communication and collaboration.
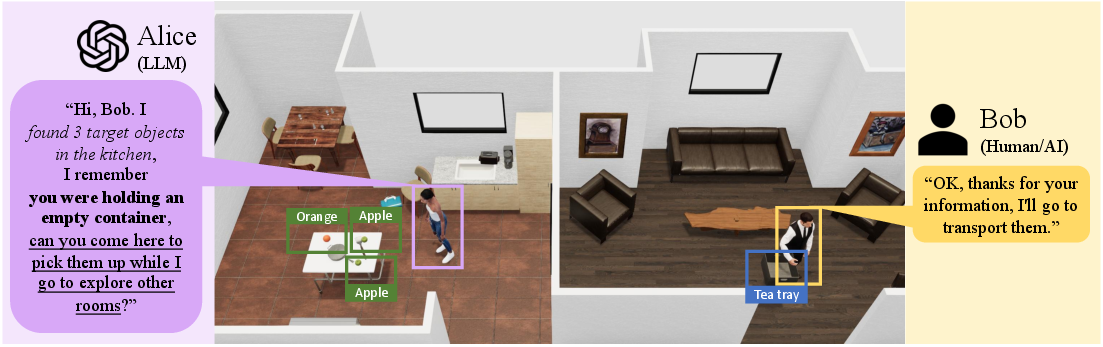
Figure 1: A challenging multi-agent cooperation problem with decentralized control, raw sensory observations, costly communication, and long-horizon multi-objective tasks.
Framework Overview
CoELA's architecture consists of five functional modules:
- Perception Module: Handles raw sensory inputs using methodologies such as Mask-RCNN for object detection, allowing the agent to build a semantic understanding from RGB-D observations.
- Memory Module: Mimics human long-term memory by maintaining semantic, episodic, and procedural memories. This setup allows agents to store knowledge about past experiences, current task progress, and procedural instructions essential for executing plans.
- Communication Module: Leverages LLMs for generating and sending messages. It involves deliberation on what to communicate, ensuring messages are concise and relevant, and includes contextual prompts for LLMs to formulate communication effectively.
- Planning Module: Utilizes LLMs for high-level decision making by leveraging task-relevant prompts and a compiled list of possible actions. Techniques such as chain-of-thought prompting are used to enhance the reasoning process of LLMs.
- Execution Module: Translates high-level plans into primitive actions using procedural knowledge, thus enabling the Planning Module to focus on complex reasoning by offloading execution-specific details.
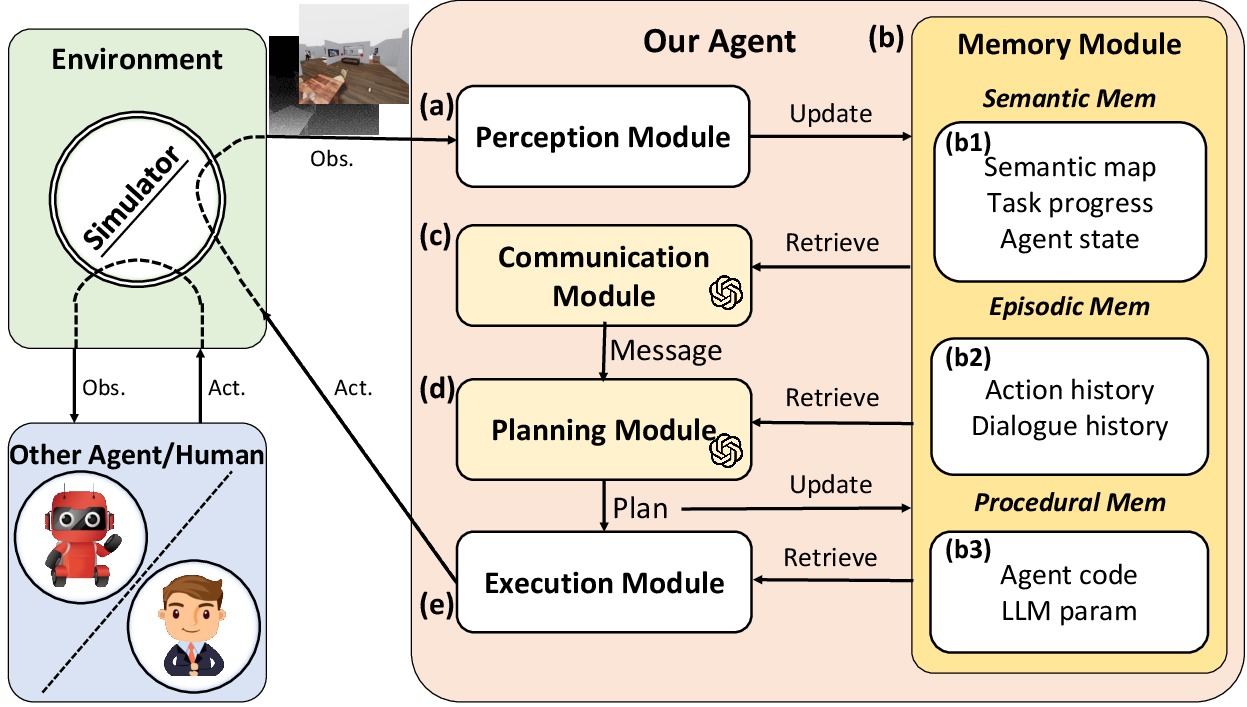
Figure 2: An overview of CoELA. Key modules leverage LLMs for communication, planning, memory storage, perception, and execution.
Experimental Setup
Environments
- TDW-MAT: A multi-agent transport challenge on the ThreeDWorld platform, presenting tasks that require transporting objects with constraints on object handling and navigation.
- C-WAH: Extends the Watch-And-Help task to include communication, requiring agents to perform tasks like setting tables or preparing meals.
Evaluation Metrics
The effectiveness of CoELA is measured using metrics such as Transport Rate (TR) and Average Steps. These metrics help quantify efficiency improvements brought about by the agent's cooperation strategies.

Figure 3: Example cooperative behaviors demonstrating CoELA can communicate effectively and are good cooperators.
Results and Analysis
CoELA driven by GPT-4 exhibits significant improvements in collaboration tasks, showcasing approximately 40% efficiency gains over strong baselines. When compared with models such as LLAMA-2, fine-tuned CoLLAMAs demonstrate promising potential, albeit with slight performance gaps due to LLMs' varied reasoning capabilities.
Human-agent interactions indicate that CoELA enhances trust and cooperation efficiency when communicating in natural language. Agents exhibit behaviors like sharing progress and adapting plans collaboratively — critical to effective multi-agent cooperation.
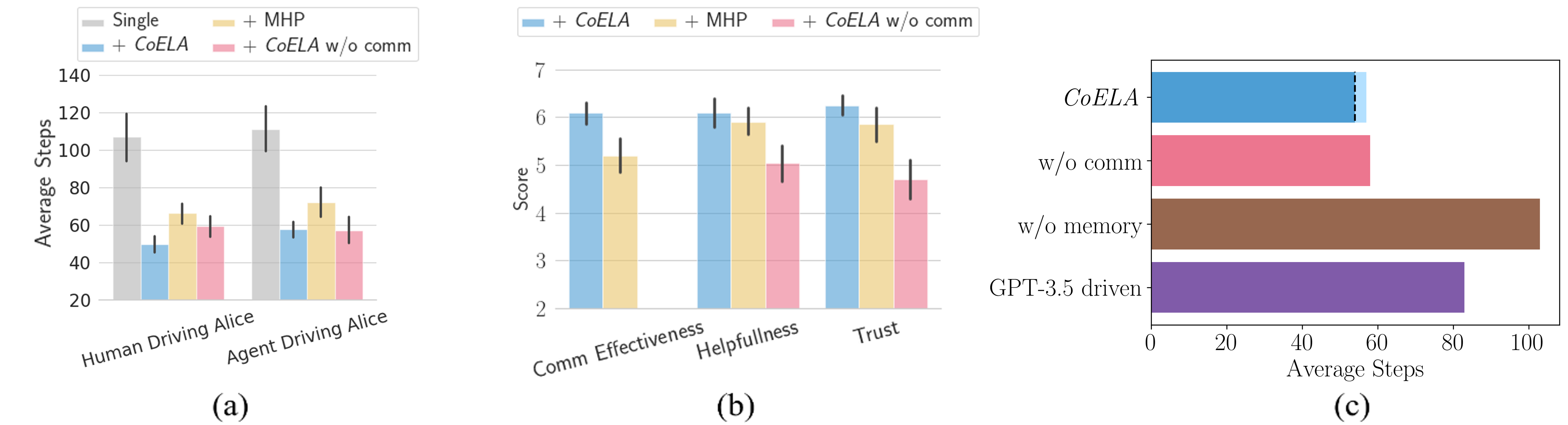
Figure 4: Human experiments results show CoELA's trustworthiness and efficiency in human interaction contexts.
Limitations and Future Work
Several limitations are recognized, such as the restricted use of 3D spatial information and occasional reasoning errors from LLMs. Further work could explore multi-modal models that integrate spatial reasoning more effectively and enhance instructional capabilities for improved task execution.
Conclusion
This research introduces a modular framework integrating LLMs to facilitate multi-agent cooperation in embodied environments. By addressing challenges in decentralized communication and planning, CoELA highlights the potential of LLMs in realizing sophisticated cooperative behaviors in embodied AI systems. The results suggest significant avenues for future work in designing robust, language-powered cooperative agents capable of advanced interaction both with peers and humans.