- The paper presents ParameterNet, a method to augment model parameters via dynamic convolutions, effectively bypassing the low-FLOPs pitfall in visual pretraining.
- It employs a lightweight MLP and multiple expert modules to dynamically generate convolution weights, achieving higher accuracy on ImageNet datasets without significant FLOPs increases.
- The framework extends to language models, demonstrating improved inference outcomes while maintaining computational efficiency, thus paving the way for scalable AI architectures.
ParameterNet: Parameters Are All You Need
The paper, "ParameterNet: Parameters Are All You Need" (2306.14525), addresses a key issue in the field of large vision models known as the low FLOPs pitfall. This phenomenon describes the inability of low-FLOPs models to leverage benefits from large-scale visual pretraining, a limitation despite significant improvements observed in high-FLOPs counterparts. The authors propose ParameterNet, a framework that augments the number of parameters in visual pretraining models with minimal increases in computational complexity defined by FLOPs.
Introduction to ParameterNet
ParameterNet is conceptualized to overcome the inherent drawbacks faced by low-FLOPs models during large-scale pretraining. While conventional models scale primarily through increased FLOPs, the authors focus on augmenting model capacity via additional parameters introduced dynamically. The utilization of dynamic convolutions serves as the cornerstone of this approach, enabling efficient integration of supplementary parameters without proportionate increases in FLOPs.
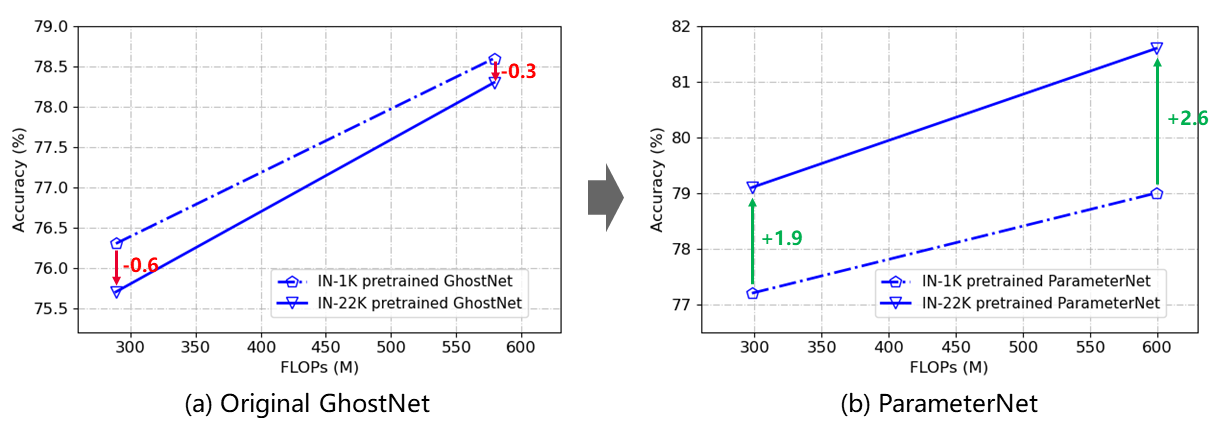
Figure 1: Results on ImageNet-1K validation set. The original GhostNet falls into the low FLOPs pitfall. The proposed ParameterNet overcomes the low FLOPs pitfall.
The authors extend this augmentation strategy to LLMs, revealing that increased parameters enhance inference outcomes while maintaining inference speeds. Tests conducted on ImageNet-22K demonstrate ParameterNet's superior performance relative to traditional models like the Swin Transformer.
Observations and Challenges in FLOPs Pitfall
Large-scale datasets such as ImageNet-22K and smaller counterparts like ImageNet-1K were used in experiments with vision transformers and CNNs. A key observation is that while accuracy generally scales with FLOPs and dataset size, low-FLOPs models do not benefit equivalently from large datasets due to structural limitations—hence the low FLOPs pitfall.
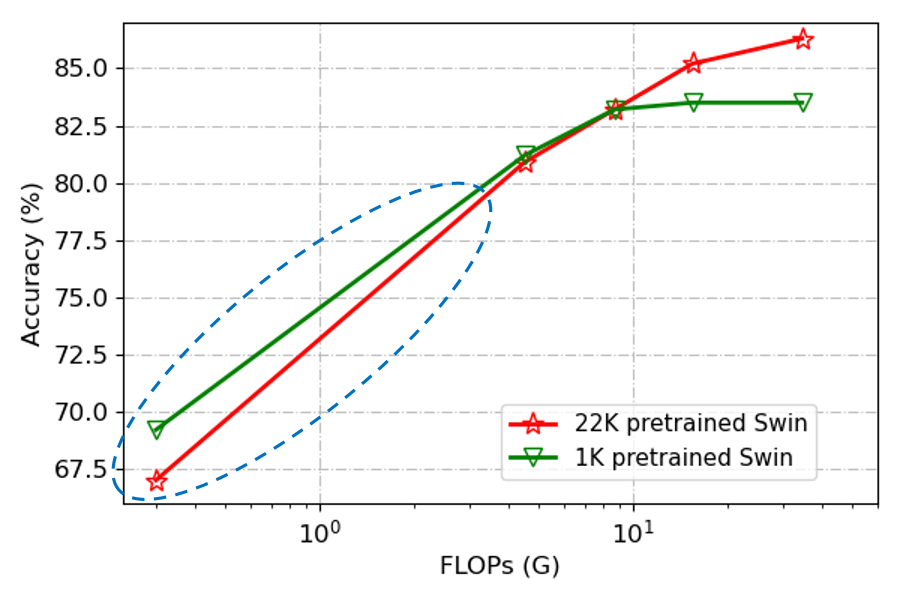
Figure 2: Low FLOPs pitfall. Swin Transformer results on ImageNet-1K validation set. The red and blue lines denote ImageNet-22K and ImageNet-1K pretraining, respectively.
The empirical analysis using Swin Transformer and EfficientNetV2 confirms the trends. In both architectures, the performance disparity is evident, particularly with less computationally demanding models (below 2G FLOPs), which fail to realize gains from extensive datasets.
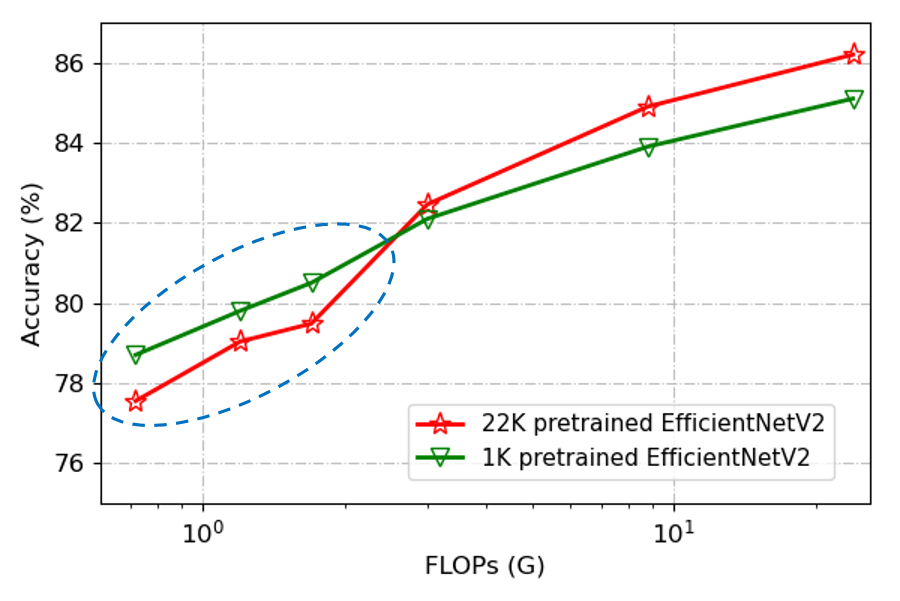
Figure 3: Low FLOPs pitfall. EfficientNetV2 results on ImageNet-1K validation set. The red and blue lines denote ImageNet-22K and ImageNet-1K pretraining, respectively.
Implementation of ParameterNet
The innovation in ParameterNet lies in leveraging dynamic convolutions. These are devised as a composition of multiple experts, enabling additional trainable parameters without substantive increase in FLOPs. Each convolutional layer dynamically creates its weights based on sample-specific inputs through a lightweight MLP module.
The parameters and FLOPs of dynamic convolutions are discussed with comprehensive analysis illustrating approximately a multiplicative increase in parameters relative to minimal FLOPs change. Experiments substantiate substantial accuracy improvements on ImageNet-1K through ImageNet-22K pretraining, with ParameterNet models outperforming vanilla models in both vision and language domains.
ParameterNet Application in LLMs
A scaled LLaMA model benefits similarly from ParameterNet, underscoring the strategy's versatility across domains. Through the use of sparse-activated MoE models, language tasks experience enhanced accuracy metrics, affirming the principle that parameters, rather than FLOPs, dictate learning success in large-scale pretraining scenarios.
Conclusion
The paper successfully presents ParameterNet as a robust approach to circumvent the low FLOPs pitfall encountered in large-scale training. By prioritizing parameter augmentation alongside minimal FLOPs increases, the method enhances the pretraining robustness for vision and language tasks alike. Such strategies herald promising computational efficiency avenues within both current and next-generation AI model development frameworks. The broader implications suggest potential applications in multimodal models and further expansion of efficient learning paradigms within the AI field.
