Reproducibility in NLP: What Have We Learned from the Checklist?
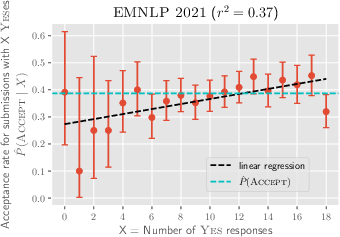
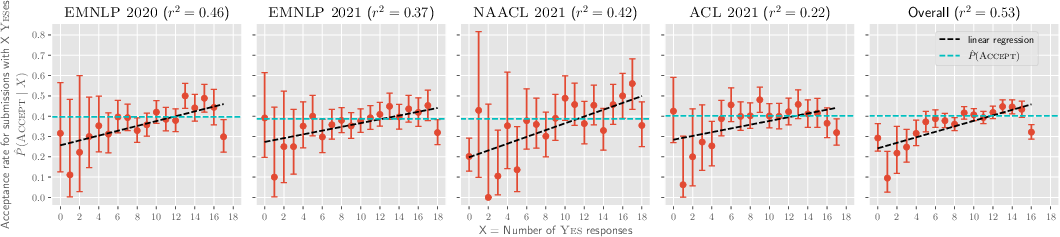
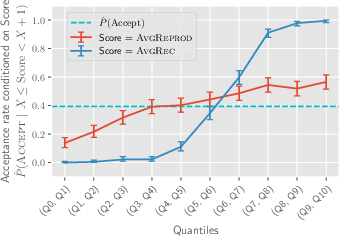
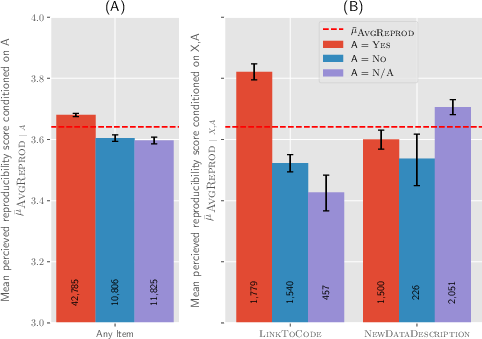
Abstract: Scientific progress in NLP rests on the reproducibility of researchers' claims. The *CL conferences created the NLP Reproducibility Checklist in 2020 to be completed by authors at submission to remind them of key information to include. We provide the first analysis of the Checklist by examining 10,405 anonymous responses to it. First, we find evidence of an increase in reporting of information on efficiency, validation performance, summary statistics, and hyperparameters after the Checklist's introduction. Further, we show acceptance rate grows for submissions with more Yes responses. We find that the 44% of submissions that gather new data are 5% less likely to be accepted than those that did not; the average reviewer-rated reproducibility of these submissions is also 2% lower relative to the rest. We find that only 46% of submissions claim to open-source their code, though submissions that do have 8% higher reproducibility score relative to those that do not, the most for any item. We discuss what can be inferred about the state of reproducibility in NLP, and provide a set of recommendations for future conferences, including: a) allowing submitting code and appendices one week after the deadline, and b) measuring dataset reproducibility by a checklist of data collection practices.
- Estimating the reproducibility of psychological science. Science, 349(6251):aac4716.
- Monya Baker. 2016. 1,500 scientists lift the lid on reproducibility. Nature, 533:452–454.
- Emily M. Bender. 2019. The #benderrule: On naming the languages we study and why it matters.
- Emily M. Bender and Batya Friedman. 2018. Data statements for natural language processing: Toward mitigating system bias and enabling better science. Transactions of the Association for Computational Linguistics, 6:587–604.
- The plos one collection on machine learning in health and biomedicine: Towards open code and open data. PloS one, 14(1):e0210232.
- Kamalika Chaudhuri and Ruslan Salakhutdinov. 2019. The icml 2019 code-at-submit-time experiment.
- Association between author metadata and acceptance: A feature-rich, matched observational study of a corpus of iclr submissions between 2017-2022.
- Show your work: Improved reporting of experimental results. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2185–2194, Hong Kong, China. Association for Computational Linguistics.
- Documenting large webtext corpora: A case study on the colossal clean crawled corpus. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 1286–1305, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Jesse Dodge and Noah A. Smith. 2020. Guest post: Reproducibility at EMNLP 2020.
- Toward standard practices for sharing computer code and programs in neuroscience. Nature neuroscience, 20(6):770–773.
- Offspring from reproduction problems: What replication failure teaches us. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1691–1701, Sofia, Bulgaria. Association for Computational Linguistics.
- Datasheets for datasets. Communications of the ACM, 64:86 – 92.
- Odd Erik Gundersen and Sigbjørn Kjensmo. 2018. State of the art: Reproducibility in artificial intelligence. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1).
- Transparency and reproducibility in artificial intelligence. Nature, 586 7829:E14–E16.
- Towards accountability for machine learning datasets: Practices from software engineering and infrastructure. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency.
- Scientific credibility of machine translation research: A meta-evaluation of 769 papers. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7297–7306, Online. Association for Computational Linguistics.
- Reproducibility in machine learning for health.
- What do nlp researchers believe? results of the nlp community metasurvey.
- Nature. 2018. Checklists work to improve science. Nature, 556(7701):273–274.
- Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830.
- Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program). ArXiv, abs/2003.12206.
- Data cards: Purposeful and transparent dataset documentation for responsible ai. In 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’22, page 1776–1826, New York, NY, USA. Association for Computing Machinery.
- Do ImageNet classifiers generalize to ImageNet? In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 5389–5400. PMLR.
- Anna Rogers. 2021. Changing the world by changing the data. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 2182–2194, Online. Association for Computational Linguistics.
- ‘just what do you think you’re doing, dave?’ a checklist for responsible data use in NLP. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4821–4833, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Practices in source code sharing in astrophysics. Astronomy and Computing, 1:54–58.
- SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

