INT2.1: Towards Fine-Tunable Quantized Large Language Models with Error Correction through Low-Rank Adaptation
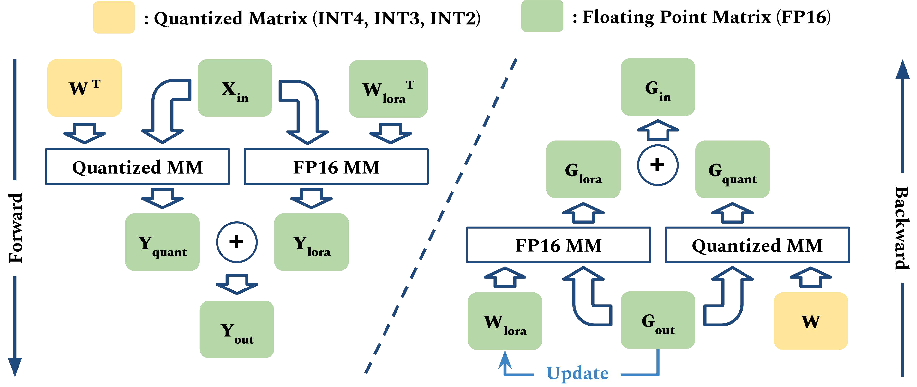
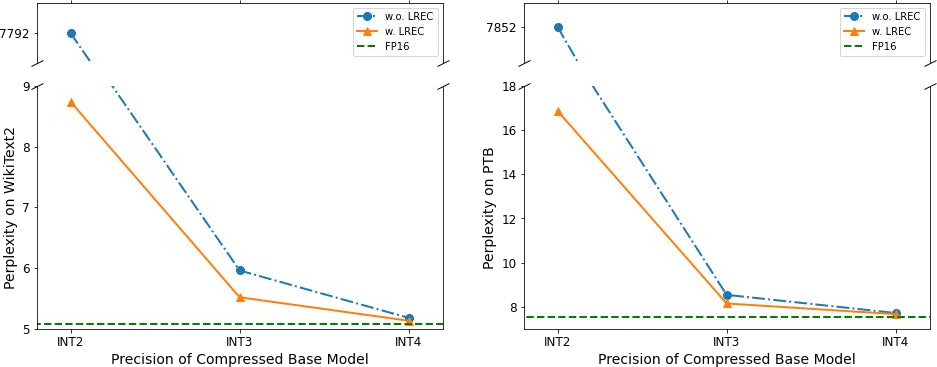
Abstract: We introduce a method that dramatically reduces fine-tuning VRAM requirements and rectifies quantization errors in quantized LLMs. First, we develop an extremely memory-efficient fine-tuning (EMEF) method for quantized models using Low-Rank Adaptation (LoRA), and drawing upon it, we construct an error-correcting algorithm designed to minimize errors induced by the quantization process. Our method reduces the memory requirements by up to 5.6 times, which enables fine-tuning a 7 billion parameter LLM on consumer laptops. At the same time, we propose a Low-Rank Error Correction (LREC) method that exploits the added LoRA layers to ameliorate the gap between the quantized model and its float point counterpart. Our error correction framework leads to a fully functional INT2 quantized LLM with the capacity to generate coherent English text. To the best of our knowledge, this is the first INT2 LLM that has been able to reach such a performance. The overhead of our method is merely a 1.05 times increase in model size, which translates to an effective precision of INT2.1. Also, our method readily generalizes to other quantization standards, such as INT3, INT4, and INT8, restoring their lost performance, which marks a significant milestone in the field of model quantization. The strategies delineated in this paper hold promising implications for the future development and optimization of quantized models, marking a pivotal shift in the landscape of low-resource machine learning computations.
- Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020.
- Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Scaling instruction-finetuned language models, 2022.
- Flashattention: Fast and memory-efficient exact attention with io-awareness, 2022.
- Gpt3.int8(): 8-bit matrix multiplication for transformers at scale. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 30318–30332. Curran Associates, Inc., 2022.
- 8-bit optimizers via block-wise quantization. 9th International Conference on Learning Representations, ICLR, 2022.
- Optimal brain compression: A framework for accurate post-training quantization and pruning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022.
- Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- Distilling the knowledge in a neural network. In NIPS Deep Learning and Representation Learning Workshop, 2015.
- Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR, 2019.
- Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations.
- The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, 2021.
- {BRECQ}: Pushing the limit of post-training quantization by block reconstruction. In International Conference on Learning Representations, 2021.
- P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602, 2021.
- Gpt understands, too. arXiv preprint arXiv:2103.10385, 2021.
- Biogpt: Generative pre-trained transformer for biomedical text generation and mining. 10 2022.
- Building a large annotated corpus of English: The Penn Treebank. Computational Linguistics, 19(2):313–330, 1993.
- Pointer sentinel mixture models, 2016.
- OpenAI. Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Lut-gemm: Quantized matrix multiplication based on luts for efficient inference in large-scale generative language models, 2023.
- Language models are unsupervised multitask learners. 2019.
- Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv e-prints, 2019.
- Multitask Prompted Training Enables Zero-Shot Task Generalization. In ICLR 2022 - Tenth International Conference on Learning Representations, Online, Unknown Region, April 2022.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Ul2: Unifying language learning paradigms, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- Finetuned language models are zero-shot learners. CoRR, abs/2109.01652, 2021.
- Emergent abilities of large language models, 2022.
- Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564, 2023.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention, 2023.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.