InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
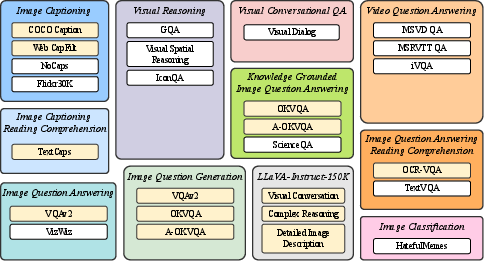
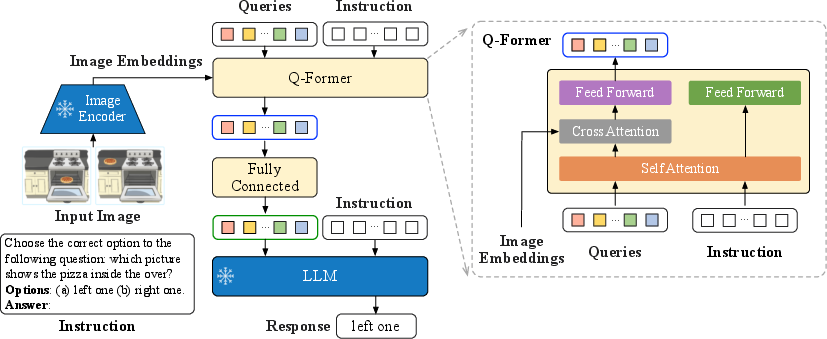
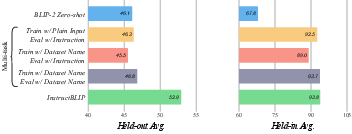
Abstract: Large-scale pre-training and instruction tuning have been successful at creating general-purpose LLMs with broad competence. However, building general-purpose vision-LLMs is challenging due to the rich input distributions and task diversity resulting from the additional visual input. Although vision-language pretraining has been widely studied, vision-language instruction tuning remains under-explored. In this paper, we conduct a systematic and comprehensive study on vision-language instruction tuning based on the pretrained BLIP-2 models. We gather 26 publicly available datasets, covering a wide variety of tasks and capabilities, and transform them into instruction tuning format. Additionally, we introduce an instruction-aware Query Transformer, which extracts informative features tailored to the given instruction. Trained on 13 held-in datasets, InstructBLIP attains state-of-the-art zero-shot performance across all 13 held-out datasets, substantially outperforming BLIP-2 and larger Flamingo models. Our models also lead to state-of-the-art performance when finetuned on individual downstream tasks (e.g., 90.7% accuracy on ScienceQA questions with image contexts). Furthermore, we qualitatively demonstrate the advantages of InstructBLIP over concurrent multimodal models. All InstructBLIP models are open-sourced at https://github.com/salesforce/LAVIS/tree/main/projects/instructblip.
- Chatgpt. https://openai.com/blog/chatgpt, 2023.
- Vicuna. https://github.com/lm-sys/FastChat, 2023.
- nocaps: novel object captioning at scale. In ICCV, pages 8948–8957, 2019.
- Flamingo: a visual language model for few-shot learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, NeurIPS, 2022.
- Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Unifying vision-and-language tasks via text generation. arXiv preprint arXiv:2102.02779, 2021.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Visual dialog. In CVPR, 2017.
- Palm-e: An embodied multimodal language model, 2023.
- Eva: Exploring the limits of masked visual representation learning at scale. ArXiv, abs/2211.07636, 2022.
- Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In CVPR, July 2017.
- Vizwiz grand challenge: Answering visual questions from blind people. In CVPR, 2018.
- Unnatural instructions: Tuning language models with (almost) no human labor. ArXiv, abs/2212.09689, 2022.
- Lora: Low-rank adaptation of large language models. In ICLR, 2022.
- Promptcap: Prompt-guided task-aware image captioning, 2023.
- Gqa: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, 2019.
- Andrej Karpathy and Li Fei-Fei. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
- The hateful memes challenge: Detecting hate speech in multimodal memes. In NeurIPS, 2020.
- Lavis: A library for language-vision intelligence, 2022.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2023.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022.
- Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021.
- Microsoft coco: Common objects in context. In ECCV, 2014.
- Visual spatial reasoning. Transactions of the Association for Computational Linguistics, 2023.
- Visual instruction tuning. 2023.
- Decoupled weight decay regularization. In ICLR, 2019.
- 12-in-1: Multi-task vision and language representation learning. In CVPR, 2020.
- Learn to explain: Multimodal reasoning via thought chains for science question answering. In NeurIPS, 2022.
- Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning. In NeurIPS Track on Datasets and Benchmarks, 2021.
- Ok-vqa: A visual question answering benchmark requiring external knowledge. In CVPR, 2019.
- Ocr-vqa: Visual question answering by reading text in images. In ICDAR, 2019.
- Large-scale pretraining for visual dialog: A simple state-of-the-art baseline. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors, ECCV, 2020.
- OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 2020.
- Multitask prompted training enables zero-shot task generalization. In ICLR, 2022.
- A-okvqa: A benchmark for visual question answering using world knowledge. In Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors, ECCV, 2022.
- Prompting large language models with answer heuristics for knowledge-based visual question answering. Computer Vision and Pattern Recognition (CVPR), 2023.
- Textcaps: a dataset for image captioningwith reading comprehension. 2020.
- Towards vqa models that can read. In CVPR, pages 8317–8326, 2019.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Cider: Consensus-based image description evaluation. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4566–4575, 2015.
- Git: A generative image-to-text transformer for vision and language, 2022.
- Self-instruct: Aligning language model with self generated instructions. ArXiv, abs/2212.10560, 2022.
- Super-NaturalInstructions: Generalization via declarative instructions on 1600+ NLP tasks. In EMNLP, 2022.
- Finetuned language models are zero-shot learners. In ICLR, 2022.
- Video question answering via gradually refined attention over appearance and motion. In Proceedings of the 25th ACM International Conference on Multimedia, page 1645–1653, 2017.
- Multiinstruct: Improving multi-modal zero-shot learning via instruction tuning. ArXiv, abs/2212.10773, 2022.
- Just ask: Learning to answer questions from millions of narrated videos. In ICCV, pages 1686–1697, 2021.
- mplug-owl: Modularization empowers large language models with multimodality. 2023.
- From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2, 2014.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.