- The paper benchmarks multiple segmentation models on the S3DIS dataset, revealing key performance trade-offs in accuracy and speed.
- It explores projection-based, voxel-based, and direct consumption methods to effectively process complex 3D point cloud data.
- Results highlight Point Transformer's superior mIoU and Cylinder3D's faster inference, underscoring practical trade-offs for real-time applications.
Summary of "Point Cloud Semantic Segmentation" (2305.00773)
Introduction
The paper explores the domain of semantic segmentation of point clouds, an integral task in computer vision that aims to classify each point in the cloud into semantic categories. Unlike 2D images, which use pixel arrays, point clouds comprise collections of points defined by spatial coordinates, potentially augmented with features like RGB values. The research utilizes the S3DIS dataset, applying several models including PointCNN, PointNet++, Cylinder3D, Point Transformer, and RepSurf, to benchmark against standard evaluation metrics.
Methodology
The study explores three primary approaches to learning from point clouds: projection-based methods, voxel-based methods, and direct consumption methods. For direct consumption, PointNet is foundational, focusing on symmetrical functions like max pooling for invariance to point order. PointNet++, an advancement over PointNet, incorporates hierarchical processing to leverage point distance.
Models
- PointCNN leverages convolution on KxK matrix transformations for neighboring points to maintain invariance and order.
- Cylinder3D targets point clouds acquired by LiDAR systems, implementing transformations to cylindrical coordinates before voxelization.
- Point Transformer, based on the Transformer architecture, employs self-attention suited for sets, enhancing its application in semantic segmentation.
- RepSurf integrates local surface structures (e.g., umbrella surfaces) in point representation, extending PointNet++ for better local neighborhood modeling.
Dataset and Preprocessing
The S3DIS dataset comprises over 273 million points scanned from interior spaces, organized into 6 areas representing different floors. Each point is tagged with semantic labels like ceiling or wall. Models are evaluated via 6-fold cross-validation combined with processing strategies such as voxelization for uniform data handling across different model architectures.
Experiments
Evaluation uses overall accuracy (OA), mean class accuracy (mAcc), and mean Intersection over Union (mIoU) as benchmarks. Point Transformer demonstrates top performance in mIoU, but the computational efficiency makes Cylinder3D notable for practical applications due to faster inference times. The paper also highlights variations in reproduced metrics across different model implementations, suggesting further investigation into hyperparameter optimizations.
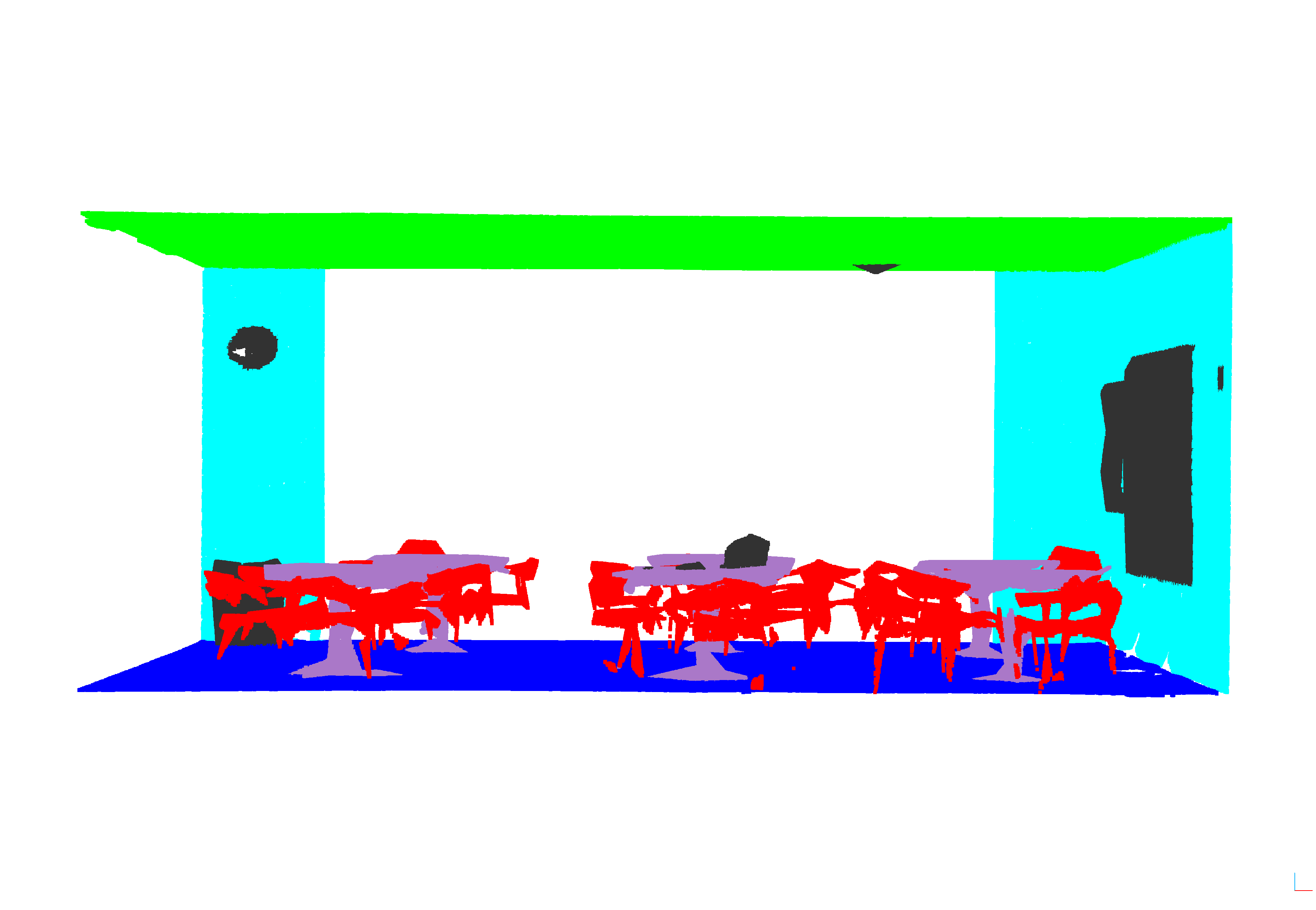
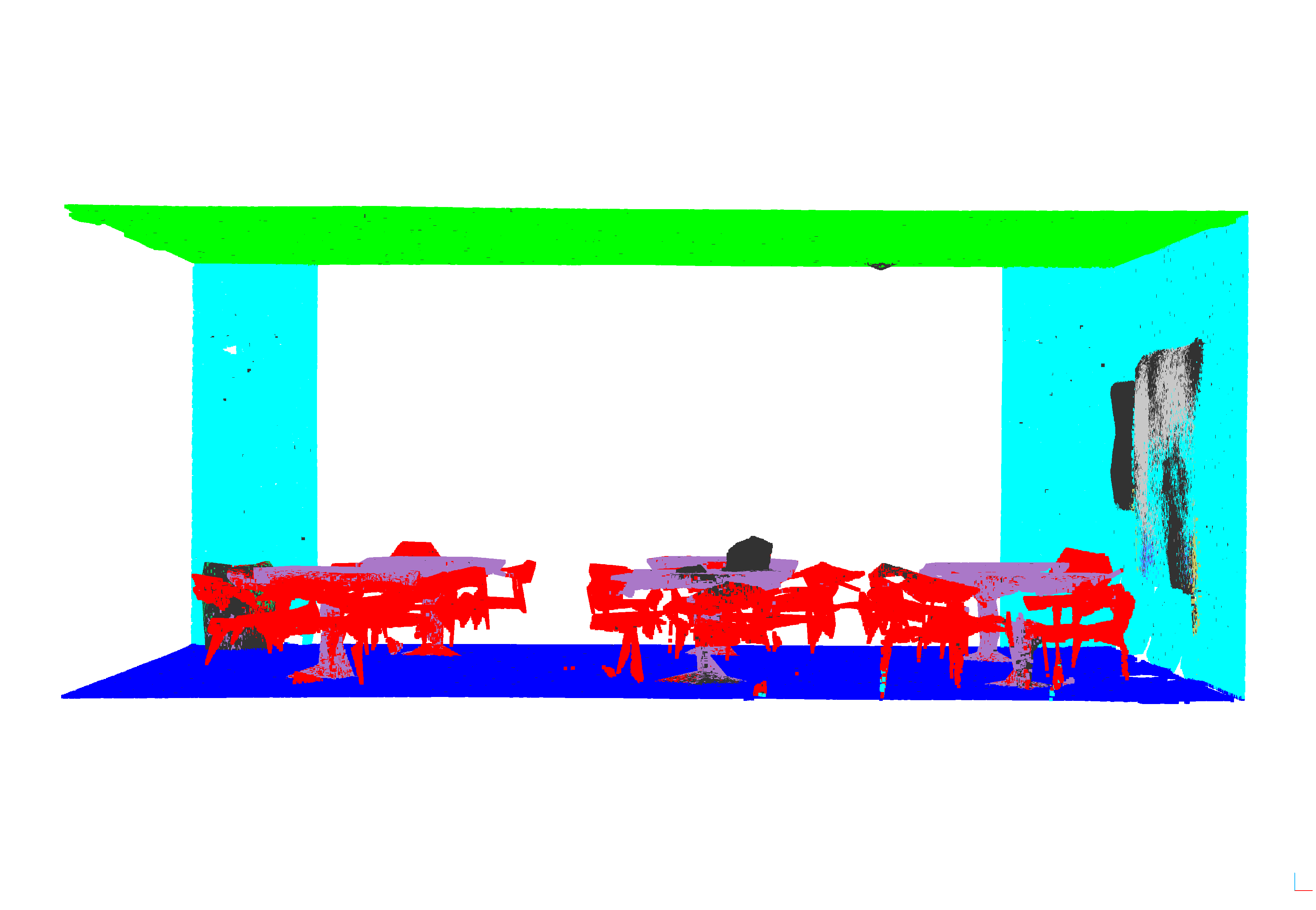





Figure 1: Vizualizacija rezultata za sve modele i prostoriju lobby1 iz podruÄja 5, highlighting diverse model predictions and real labels.
Discussion
While Point Transformer achieves the highest accuracy according to mIoU, cylinder3D excels in processing speed, advantageous in real-time applications. Observations indicate that models substantially favor well-represented classes (e.g., ceiling, floor) in the dataset, raising questions about class balance. Discrepancies between reproduced and published results for models like RepSurf and PointNet++ suggest continued exploration into architecture tuning.







Figure 2: Vizualizacija rezultata za sve modele i prostoriju conferenceRoom2 iz podruÄja 1, demonstrating model performance across different environments.
Conclusion
The paper’s experiments confirm Point Transformer’s prominence in accuracy, but recognize Cylinder3D’s efficiency as a practical consideration in resource-constrained scenarios. Future work should address parameter optimization peculiarities and investigate how grid sampling impacts computational efficiency without compromising segmentation quality.

