- The paper presents a novel VAE framework that leverages trainable linear transformations to compose and invert latent space augmentations.
- It employs a three-stage training methodology that populates the latent space with original, augmented, and composed data to learn explicit transformation mappings.
- Experimental results on MNIST show superior reconstruction performance and stability in recursive augmentations compared to standard VAE and CVAE models.
Towards Composable Distributions of Latent Space Augmentations
Introduction
The paper "Towards Composable Distributions of Latent Space Augmentations" (2303.03462) introduces a novel framework for latent space augmentation within the Variational Autoencoder (VAE) architecture. Traditional image augmentation techniques aim to improve classification and generation tasks by transforming image data, yet they can be limited by the need to select appropriate transformations for specific tasks. This paper presents an innovative approach that applies linear transformations within the VAE latent space, allowing for the composition and inversion of augmentations in a way that enhances interpretability and control. This technique demonstrates significant advancements over existing methods in terms of performance and flexibility, particularly in its ability to transfer learned latent spaces to other augmentation sets.
Latent Augmentation VAE Framework
The framework proposed employs trainable linear transformations to map between original and augmented latent representations, effectively creating a linear proxy model of transformations applicable directly in the latent space. This architecture enables the model to handle augmentation, inversion, and composition seamlessly. A significant aspect of this approach is its ability to preserve specific latent space geometries, improving augmentation performance when transferring to new augmentation pairs through additional decoder heads.
(Figure 1)
Figure 1: Eight samples of "Flips" latent augmentations with baseline image space augmentations for comparison.
Training Methodology
The training process is conducted in three stages, emphasizing the learning of mappings between original and augmented spaces. The methodology involves populating the latent space with original, augmented, and composed data, which facilitates the learning of explicit linear transformations. These allow the latent space to maintain certain properties when transferred to different augmentation sets. The architecture leverages multiple decoder heads, offering a strategic advantage by enabling the effective transfer and adaptation of trained latent spaces across various augmentations.
Experimental Results
The experimental analysis, focusing primarily on the MNIST dataset, demonstrates that the proposed augmentation method results in superior performance compared to standard VAE and Conditional VAE (CVAE) architectures. The results suggest the model's robustness in preserving latent space integrity, even when subjected to recursive augmentation processes. Intriguingly, some augmentations show a radius of stability in their latent trajectory, implying potential for stable recursive generation.

Figure 2: Initial augmentation pair choice vs. transferred augmentation MSE reconstruction error (across all augmentations).
Comparison to Conditional VAE
The paper also explores the limitations of the CVAE in handling augmentation tasks. The CVAE struggles with disentangling augmentation from data variables, indicating a degree of 'entanglement' that undermines its efficacy in augmentation-constrained tasks. By contrast, the LAVAE framework exhibits independence between augmentation and image data in the latent space, leading to better reconstruction and compositional properties, a unique feature demonstrated by the new framework. The LAVAE's clear superiority over the CVAE highlights the broader potential of the methodology for generative modeling tasks.
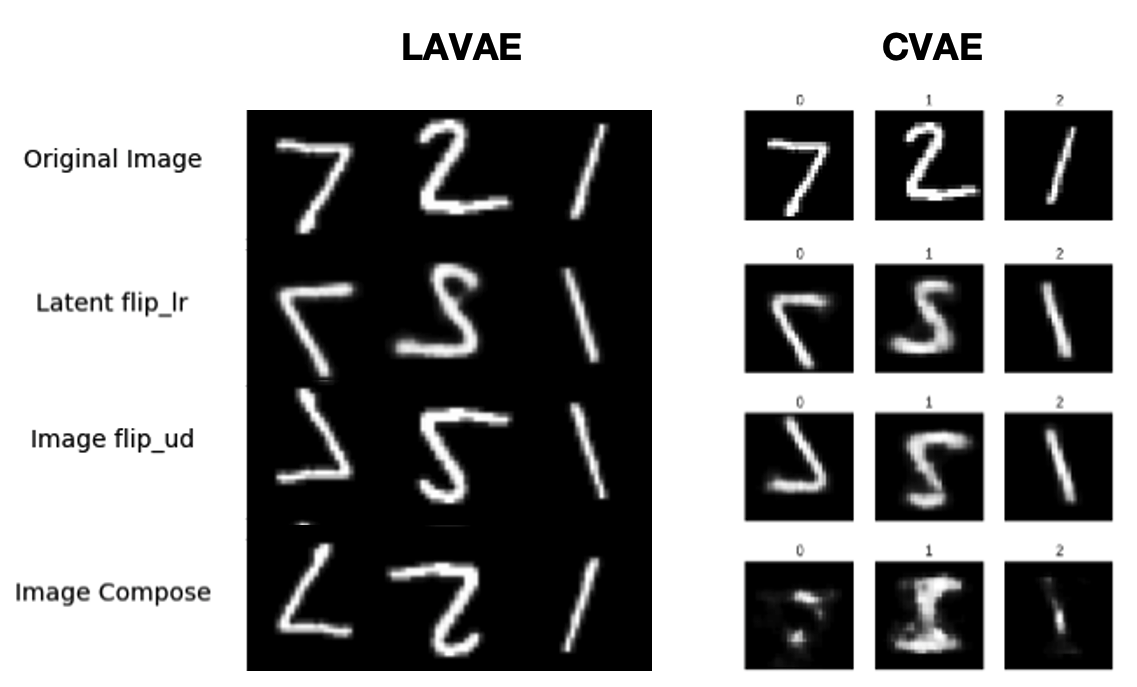
Figure 3: $ vs CVAE reconstructions.
Implications and Future Work
This research presents a significant step forward in the composability and control of data augmentations within latent spaces. Practical implications include enhanced model training efficiencies and improved interpretability of underlying transformations in latent spaces. The prospect of combining LAVAE with CVAE to develop class-conditional latent augmentations opens avenues for further investigation. Applications in unknown image models, or tasks like 2D to 3D reconstruction, reveal the potential for extension beyond the domain of image augmentation into broader AI tasks.
Conclusion
The "Composable Distributions of Latent Space Augmentations" methodology presents a compelling enhancement to VAE architectures, particularly through its latent space augmentation capabilities. The framework markedly improves performance metrics and robustness of augmentation tasks compared to traditional augmentation techniques. By viewing augmentations as latent proxy operations rather than purely data transformations, the approach significantly enhances model generalization and lays a foundation for continued exploration in latent space manipulation and its applications across complex AI challenges.