BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
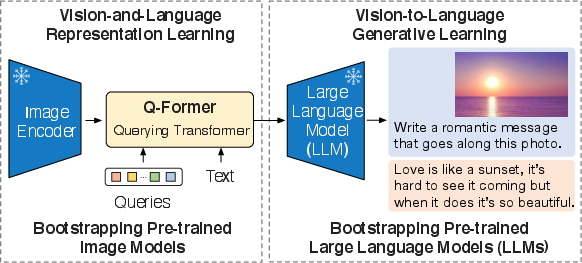
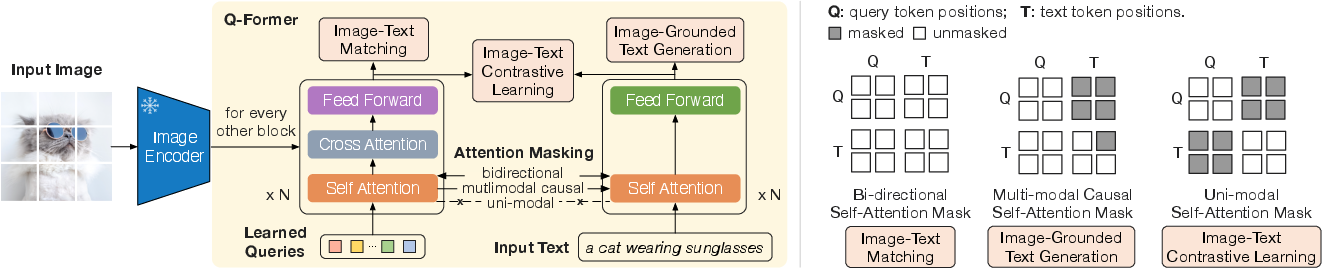
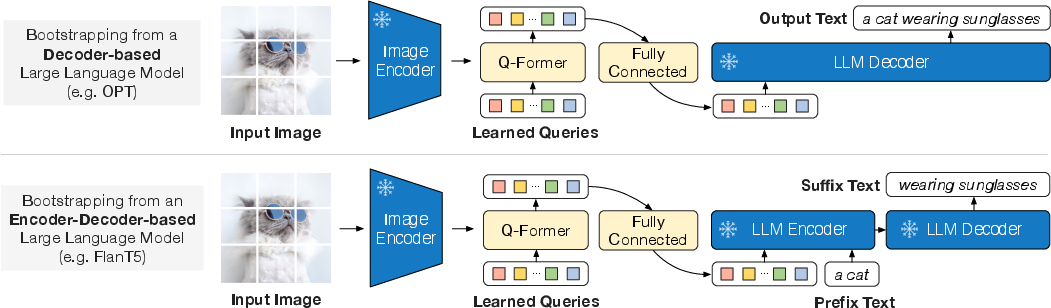
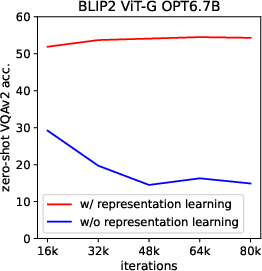
Abstract: The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen LLMs. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen LLM. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.
- nocaps: novel object captioning at scale. In ICCV, pp. 8947–8956, 2019.
- Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198, 2022.
- Language models are few-shot learners. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), NeurIPS, 2020.
- Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In CVPR, 2021.
- Visualgpt: Data-efficient adaptation of pretrained language models for image captioning. In CVPR, pp. 18009–18019, 2022a.
- Pali: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794, 2022b.
- UNITER: universal image-text representation learning. In ECCV, volume 12375, pp. 104–120, 2020.
- Unifying vision-and-language tasks via text generation. arXiv preprint arXiv:2102.02779, 2021.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Enabling multimodal generation on CLIP via vision-language knowledge distillation. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.), ACL Findings, pp. 2383–2395, 2022.
- BERT: pre-training of deep bidirectional transformers for language understanding. In Burstein, J., Doran, C., and Solorio, T. (eds.), NAACL, pp. 4171–4186, 2019.
- Unified language model pre-training for natural language understanding and generation. In Wallach, H. M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E. B., and Garnett, R. (eds.), NeurIPS, pp. 13042–13054, 2019.
- Eva: Exploring the limits of masked visual representation learning at scale. arXiv preprint arXiv:2211.07636, 2022.
- Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In CVPR, pp. 6325–6334, 2017.
- From images to textual prompts: Zero-shot VQA with frozen large language models. In CVPR, 2022.
- Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- GQA: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, pp. 6700–6709, 2019.
- Scaling up visual and vision-language representation learning with noisy text supervision. arXiv preprint arXiv:2102.05918, 2021.
- A good prompt is worth millions of parameters: Low-resource prompt-based learning for vision-language models. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.), ACL, pp. 2763–2775, 2022.
- Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 123(1):32–73, 2017.
- Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021.
- BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, pp. 12888–12900, 2022.
- Oscar: Object-semantics aligned pre-training for vision-language tasks. In ECCV, pp. 121–137, 2020.
- Microsoft COCO: common objects in context. In Fleet, D. J., Pajdla, T., Schiele, B., and Tuytelaars, T. (eds.), ECCV, volume 8693, pp. 740–755, 2014.
- Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- MAPL: parameter-efficient adaptation of unimodal pre-trained models for vision-language few-shot prompting. In EACL, 2023.
- Ok-vqa: A visual question answering benchmark requiring external knowledge. In CVPR, 2019.
- Im2text: Describing images using 1 million captioned photographs. In Shawe-Taylor, J., Zemel, R. S., Bartlett, P. L., Pereira, F. C. N., and Weinberger, K. Q. (eds.), NIPS, pp. 1143–1151, 2011.
- Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In ICCV, pp. 2641–2649, 2015.
- Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Gurevych, I. and Miyao, Y. (eds.), ACL, pp. 2556–2565, 2018.
- LXMERT: learning cross-modality encoder representations from transformers. In Inui, K., Jiang, J., Ng, V., and Wan, X. (eds.), EMNLP, pp. 5099–5110, 2019.
- Plug-and-play VQA: zero-shot VQA by conjoining large pretrained models with zero training. In EMNLP Findings, 2022.
- Multimodal few-shot learning with frozen language models. In Ranzato, M., Beygelzimer, A., Dauphin, Y. N., Liang, P., and Vaughan, J. W. (eds.), NeurIPS, pp. 200–212, 2021.
- OFA: unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvári, C., Niu, G., and Sabato, S. (eds.), ICML, pp. 23318–23340, 2022a.
- Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. arXiv preprint arXiv:2111.02358, 2021a.
- Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442, 2022b.
- Simvlm: Simple visual language model pretraining with weak supervision. arXiv preprint arXiv:2108.10904, 2021b.
- FILIP: fine-grained interactive language-image pre-training. In ICLR, 2022.
- Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917, 2022.
- Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432, 2021.
- Lit: Zero-shot transfer with locked-image text tuning. In CVPR, pp. 18102–18112, 2022.
- Vinvl: Making visual representations matter in vision-language models. arXiv preprint arXiv:2101.00529, 2021.
- OPT: open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

