- The paper introduces OpenBG, a billion-scale business KG with 2.6B triples, 88M entities, and 2,681 relation types.
- It details an ontology-driven approach using RDF and Apache Jena to integrate diverse, multimodal data efficiently.
- Results show significant improvements in e-commerce tasks, enabling better model pre-training and downstream application performance.
Construction and Applications of Billion-Scale Pre-Trained Multimodal Business Knowledge Graph
Introduction
The development of business Knowledge Graphs (KGs) is critical for enterprises engaged in e-commerce and other business activities. The challenges include accommodating diverse data modalities and handling large-scale noisy datasets. This paper discusses the construction of OpenBG, an open, multimodal business KG, at a scale of 2.6 billion triples, designed to address these challenges, particularly in non-trivial real-world systems at Alibaba Group. OpenBG is crafted with an intricate core ontology that encapsulates 88 million entities and 2,681 relation types, offering rich semantic structures for deploying numerous business applications.
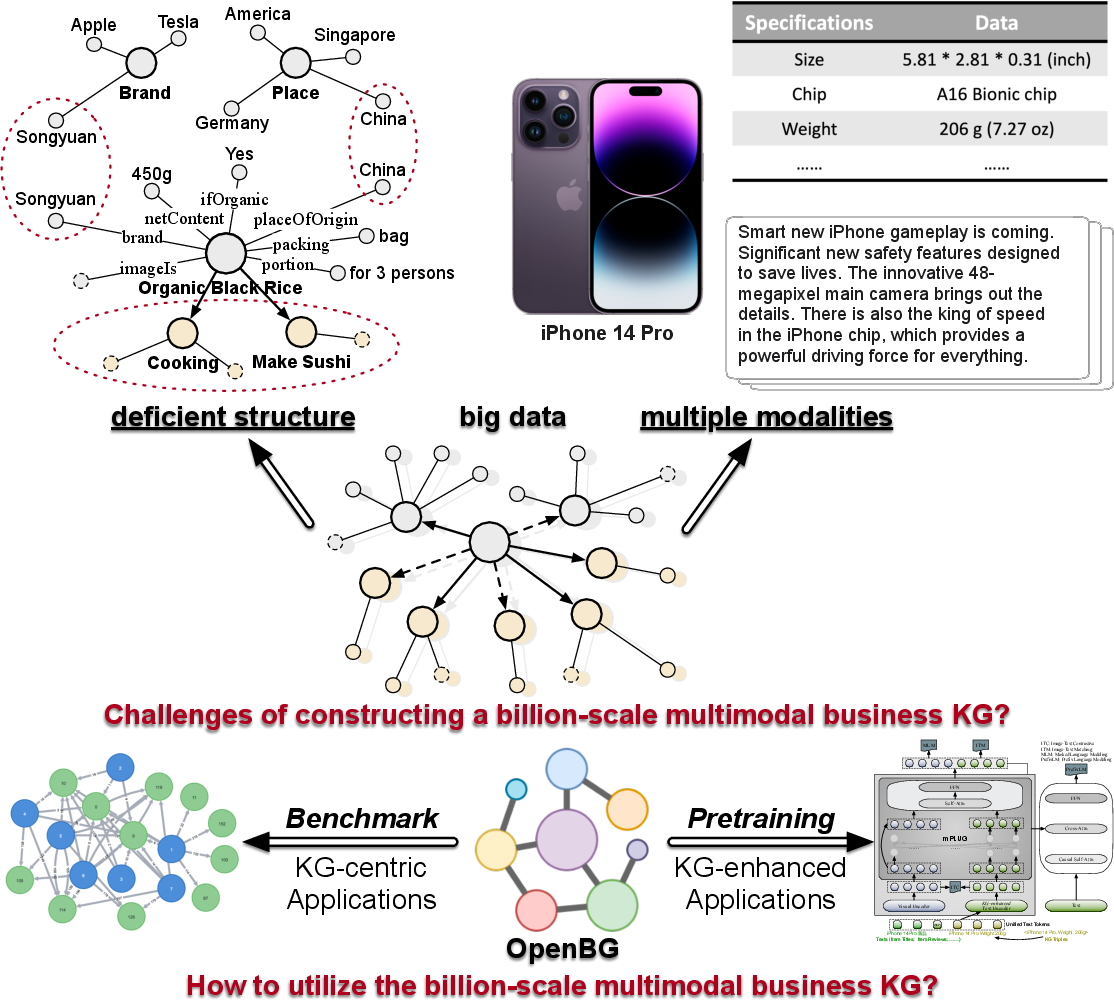
Figure 1: Challenges of building a large-scale business KG from multi-source and noisy big data, and illustration of KG applications.
Construction of OpenBG
The foundation of OpenBG lies in its core ontology, depicted in Figure 2, constructed by referencing W3C standards. This ontology comprises three major classes—Category, Brand, and Place—and five concept types—Time, Scene, Theme, Crowd, and Market Segment. The approach deals with structural deficiencies through precise ontology specification and multimodal handling via RDF triples.
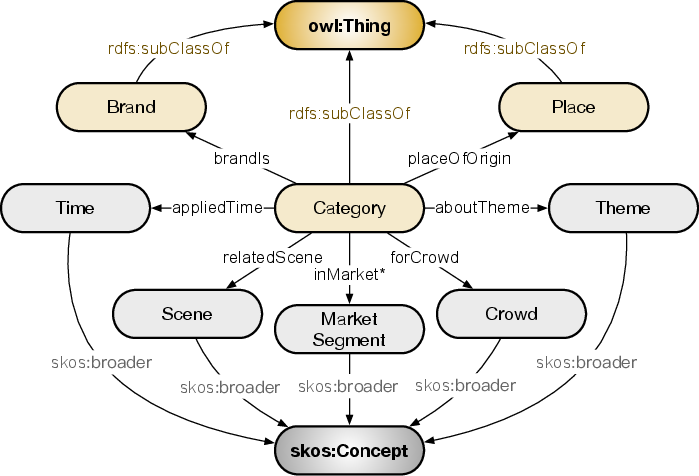
Figure 2: The core ontology of OpenBG.
The ontology-driven approach allows the systematic integration of multimodal knowledge, with extensive human resources and computational power for data annotation and processing. Apache Jena is used to formalize the ontology and populate it by linking vast amounts of multimodal data.
Applications and Enhancements
OpenBG not only functions as a standalone KG but also serves as a foundation for pre-training large models, as illustrated in Figure 3, enhancing various downstream e-commerce tasks. These tasks range from link prediction and named entity recognition (NER) for item titles to salience evaluation in commonsense knowledge.
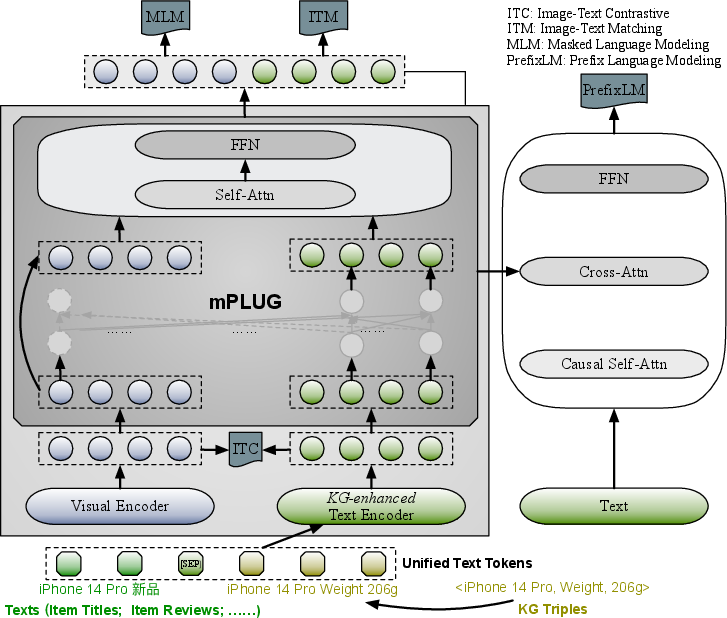
Figure 3: A illustration of the large model pre-training enhanced with OpenBG.
The enhancements provided by OpenBG are rigorous in benchmarks like OpenBG-IMG and OpenBG500, demonstrating superior performance over existing baseline models in both single-modal and multimodal contexts.
Results and Discussion
Experiments illustrate the efficacy of OpenBG in KG-centric and KG-enhanced tasks. Table \ref{tab:openbg-img} and \ref{tab:openbg500} present the link prediction results, underscoring translational distance models' superiority. The pre-trained models enhanced with OpenBG display significant improvements in downstream applications, such as category prediction accuracy and NER F1 scores.
Future Directions
To further refine OpenBG, attention must be focused on quality management, such as refinement and expansion of the KG. The continual growth of OpenBG's capabilities and applications presents an exciting opportunity for leveraging KGs in cross-disciplinary fields beyond e-commerce.
Conclusion
OpenBG stands as a formidable, billion-scale multimodal business KG, unprecedented in its scope and application versatility. By releasing resources and benchmarks to the community, OpenBG fosters the continued advancement of KG applications. Future enhancements include extending OpenBG's utility to broader applications, ultimately facilitating a deeper integration of structured knowledge in AI-driven systems.