- The paper demonstrates that leveraging an adjacency list structure with adaptive multi-task learning effectively mitigates error propagation in relational fact extraction.
- The model DIRECT utilizes a shared BERT encoder with task-specific modules, achieving superior F1 scores on NYT (92.5) and WebNLG (93.2) benchmarks.
- The work introduces a systematic taxonomy for RFE architectures, providing a clear framework for future scalable and efficient information extraction designs.
This paper proposes a unified analytical view on relational fact extraction (RFE) based on the output data structure, positioning all RFE models within the paradigm of graph-oriented representations: edge lists, adjacency matrices, and adjacency lists. The core argument is that the choice of output structure fundamentally constrains expressiveness, efficiency, and the capacity to resolve overlapping relational triples. Edge list models (such as seq2seq-based approaches) suffer from triplet overlap and order-dependence issues, whereas adjacency matrix models, despite their coverage, incur significant space inefficiency due to inherent sparsity. The adjacency list representation is advocated as an optimal trade-off, combining search efficiency with space parsimony. However, fully leveraging the structural advantages of adjaceny lists requires algorithmic innovations to mitigate sub-task error propagation and optimize multi-task synergy.
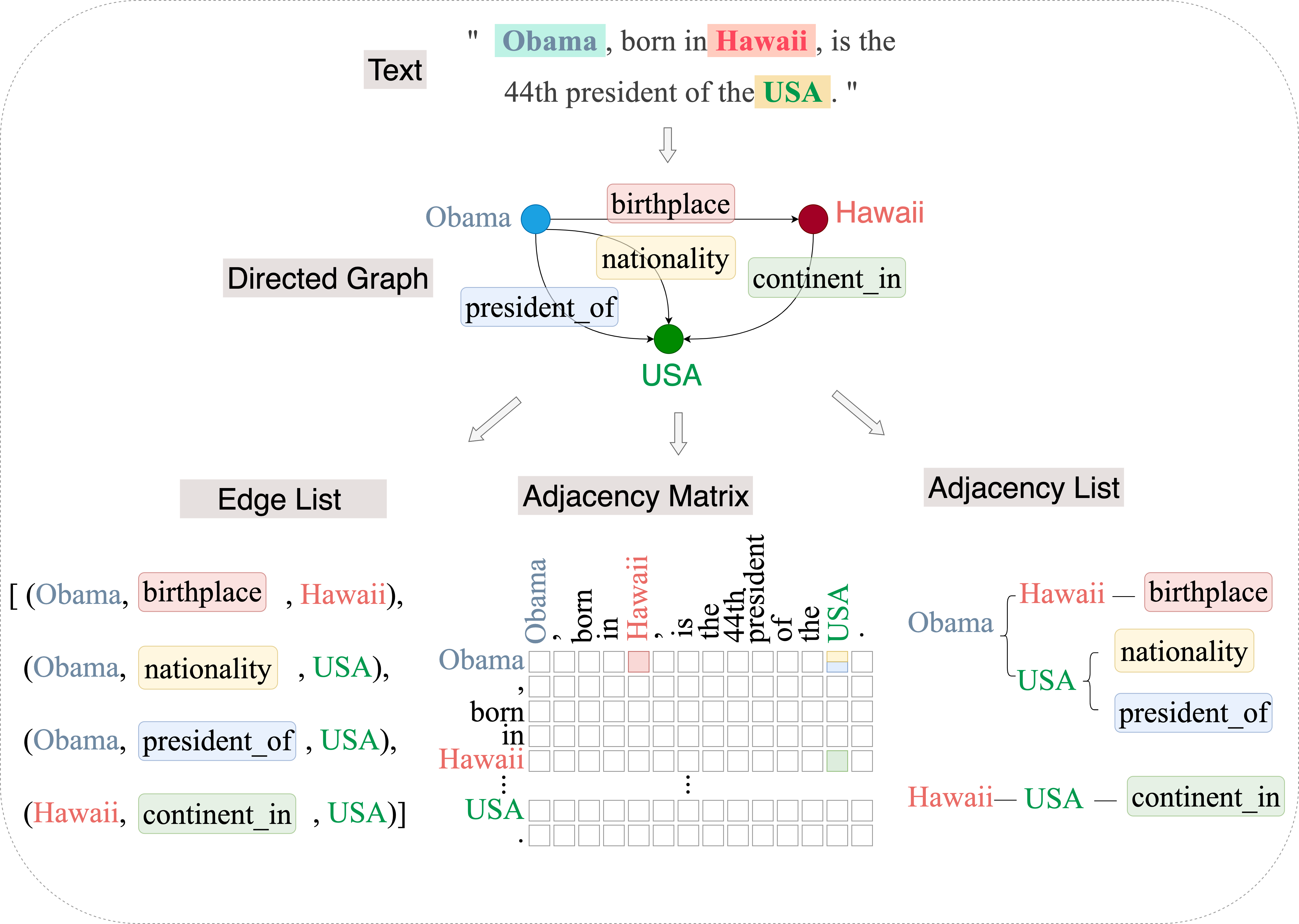
Figure 1: Relational fact extraction formulated as a directed graph using adjacency lists, highlighting mapping of entities and relations to graph-structured representations.
The authors introduce DIRECT (aDjacency lIst oRiented rElational faCT extraction), a model that comprehensively operationalizes the adjacency list output structure for end-to-end relational triple extraction. The DIRECT architecture comprises a shared BERT encoder yielding contextually rich token representations, upon which three task-specific modules are stacked: subject extraction, object extraction (both Pointer Network-based with sigmoid/BCE for multi-span output), and relation classification (multi-label objective). Subject-object pairs are constructed sequentially, adhering to adjacency list semantics.
Adaptive multi-task learning with dynamic sub-task loss balancing is the distinguishing algorithmic innovation. Here, sub-tasks (subject, object, relation) receive dynamically modulated weights based on the exponential moving average (EMA) of their recent losses, normalized by batch counts. This dynamically accounts for disparate convergence rates and prevents overfitting to any particular sub-task, directly addressing the error propagation endemic in cascade architectures and the loss imbalance in naïve MTL.
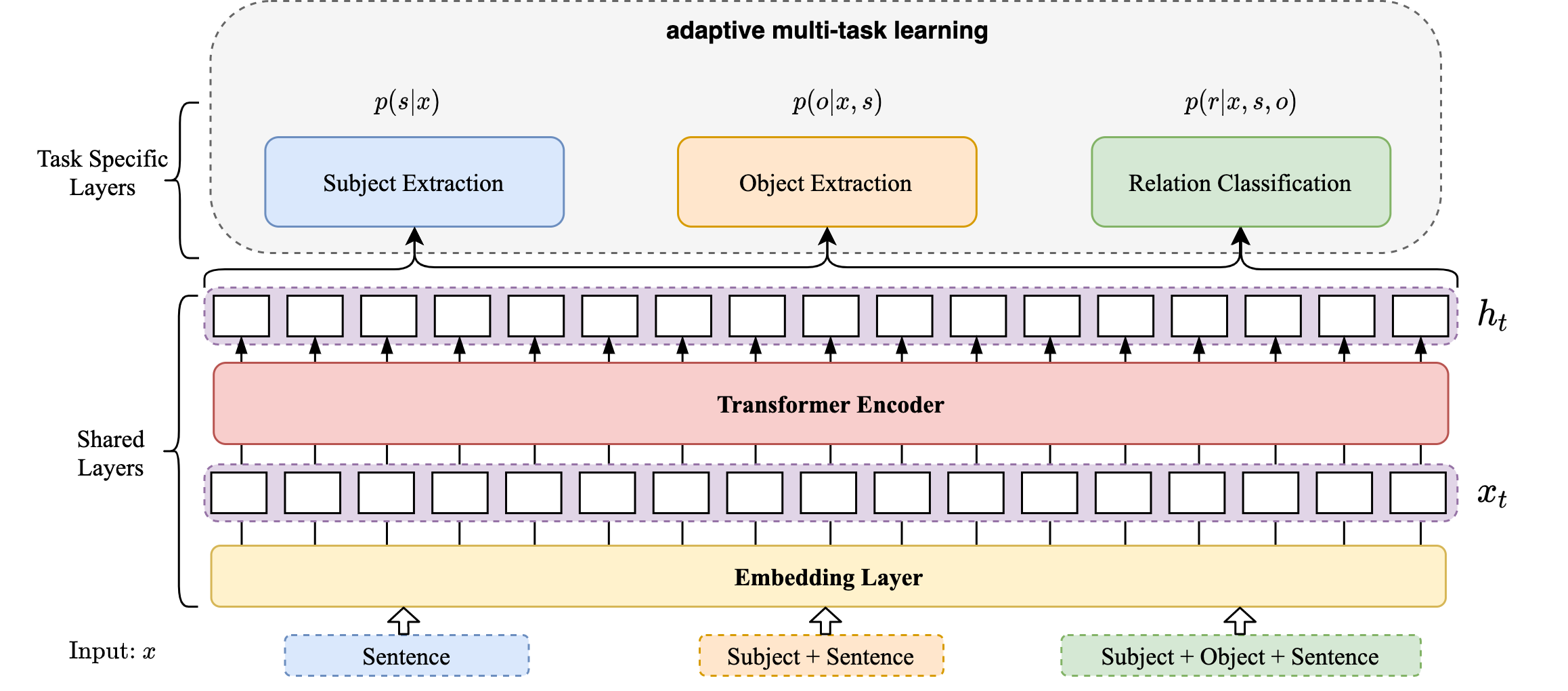
Figure 2: Overview of the DIRECT framework integrating shared encoding and adaptive multi-task strategies for efficient, robust triplet extraction.
Empirical Evaluation
DIRECT is extensively benchmarked on NYT and WebNLG, using standard micro-averaged precision, recall, and F1 metrics. Against strong SOTA baselines—NovelTagging, CopyRE, GraphRel, CopyRL, and CasRel—DIRECT achieves superior F1 scores (NYT: 92.5, WebNLG: 93.2), with statistically significant improvements over CasRel, the best previous adjacency list-oriented model. Element-level analysis shows DIRECT yields higher F1 for subject, object, and relation identification, reinforcing the empirical advantage of full adjacency list orientation combined with adaptive MTL.
Crucially, DIRECT demonstrates consistent robustness across sentences with overlapping entity/relation patterns (Normal, EPO, SEO) and excels on sentences with high relational triplet density. Its performance margin widens as relational complexity increases, underscoring the model's scalability and generalizability for realistic, ambiguous information extraction scenarios.
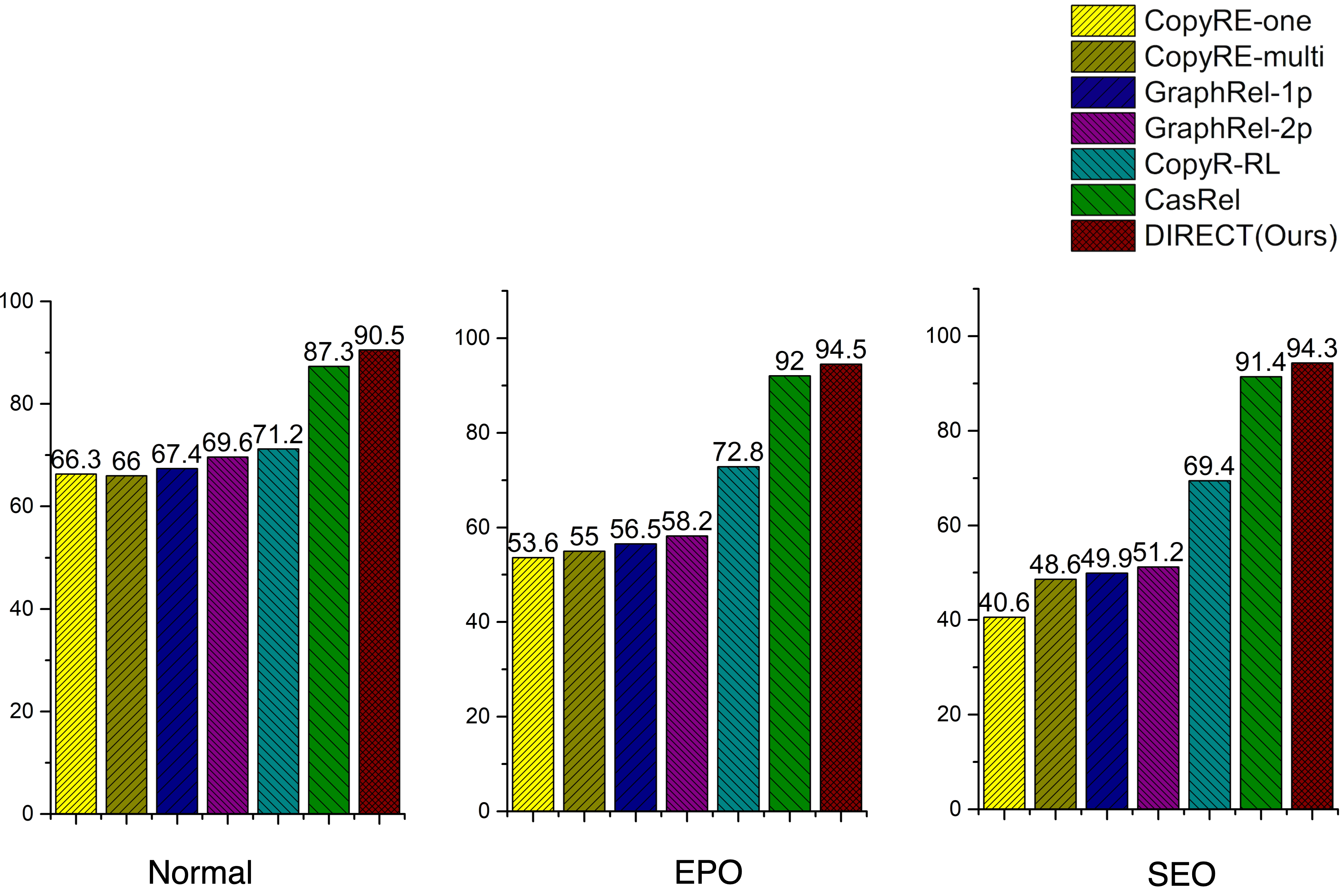
Figure 3: DIRECT exhibits robust F1 scores for triplet extraction across all overlapping patterns on the NYT dataset, outperforming all baseline models.
Graph representation efficiency, measured by predicted logits required per instance, clearly favors DIRECT, which exhibits a substantially lower output complexity compared to adjacency matrix and cascade-based methods, indicating lower computational and memory burden without sacrificing expressivity.
Ablation and Component Analysis
Ablation studies confirm that sharing output parameters between subject and object extractors degrades performance, validating the design of independent modules despite architectural similarity. Replacing adaptive loss weighting with static, equal-weighted summation results in a notable F1 drop (91.0), evidencing the necessity of dynamic loss balancing. The EMA-based loss weighting helps ensure both rapid convergence and effective sharing of encoder parameters while preventing task starvation.
Theoretical and Practical Implications
This work introduces a systematic methodology for analyzing RFE architectures via the lens of output data structure, providing a taxonomic baseline for future model design. The results demonstrate that adjacency list orientation is inherently advantageous when paired with carefully constructed adaptive MTL, both in terms of extraction accuracy and computational efficiency. From a practical standpoint, DIRECT is compelling for high-throughput knowledge graph construction, especially in settings characterized by dense, overlapping relational structures such as biomedical text or large-scale document corpora.
Theoretically, this research supports the conjecture that output structure-awareness—explicit in model design and loss balancing—can resolve core limitations in traditional sequence and matrix-based approaches, offering a robust framework for complex IE tasks where entity and relation ambiguity is prevalent.
Conclusion
DIRECT establishes a benchmark for adjacency list-oriented relational fact extraction, integrating advanced multi-task learning strategies to address both architectural and optimization challenges. The framework is extensible to arbitrary multi-relational text domains and offers clear directions for future work, including more sophisticated structure-aware decoders, integration with pre-trained LLMs at higher scales, and joint learning with upstream/downstream knowledge graph modules.