- The paper identifies that pervasive label errors in test sets can mislead performance evaluations, averaging a 3.3% error rate across benchmarks.
- Using Confident Learning algorithms and human validation, the study quantifies the impact of label errors and demonstrates shifts in model rankings.
- Findings suggest that lower-capacity models may outperform higher-capacity ones in noisy conditions, urging re-evaluation of model selection criteria.
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
The paper "Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks" identifies significant label errors within the test sets of widely used datasets. These errors have implications for model evaluation, challenging the accuracy of machine learning benchmarks used to assess and compare models.
Introduction
Label errors are inherent in the construction of datasets used for supervised learning across various domains such as computer vision, natural language processing, and audio classification. Despite their importance in driving ML progress, these datasets often feature label inaccuracies due to automated labeling processes or crowd-sourcing errors. This paper reveals that such errors are not only present in training sets but also pervade test sets, potentially invalidating reported benchmark performances.

Figure 1: An example label error from each category for image datasets, illustrating the diversity of label errors across different datasets.
Methodology
The paper utilizes Confident Learning (CL) algorithms to algorithmically identify potential label errors within test datasets. These errors are then confirmed through human validation via crowdsourcing. In analyzing 10 benchmarks used for ML models, the paper finds that an average of 3.3% of test set labels are incorrect, with ImageNet showing highest at 6%. These inaccuracies suggest the necessity for caution when choosing models based solely on conventional test set performance.

Figure 2: Examples of difficult cases where Confident Learning identified potential errors, but no actual errors existed upon human verification.
Findings and Case Studies
Through empirical analysis, the paper discovers that lower capacity models are often more robust than their higher capacity counterparts with noisy real-world data. For example, ResNet-18 outperformed ResNet-50 on corrected test labels when error prevalence was increased by 6%. Similarly, VGG-11 excelled over VGG-19 under increased noise conditions in CIFAR-10 data.
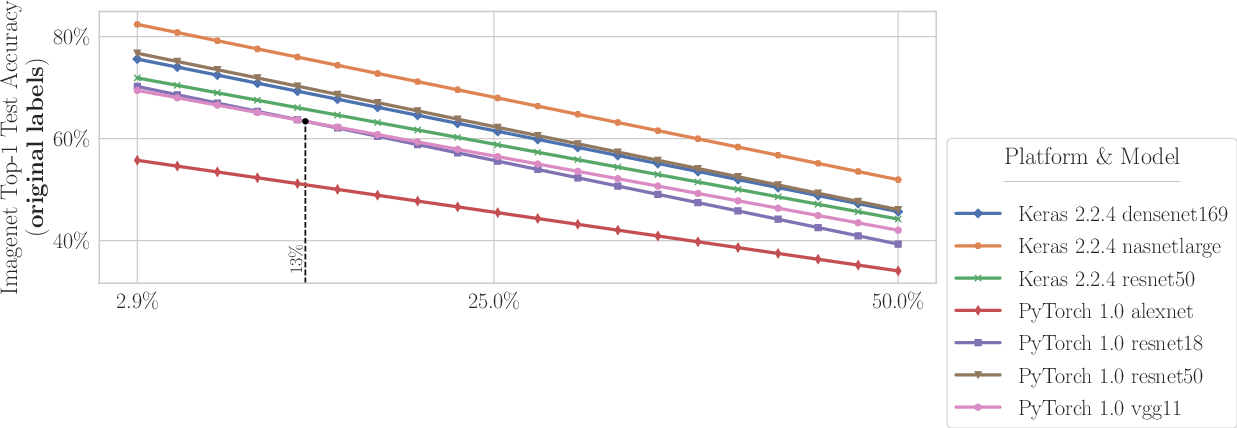
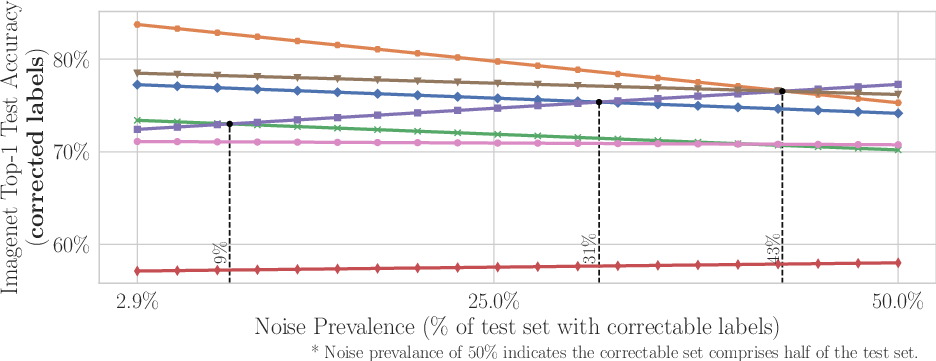
Figure 3: Analysis of ImageNet top-1 accuracy for models using original and corrected labels under different noise prevalence thresholds.
Discussion and Implications
The presence of label errors calls into question the stability and reliability of benchmarks, particularly in practical noise-prone environments. This challenges the traditional methods of model selection based on test accuracy alone, advocating for an evaluation based on corrected test sets. The paper suggests that ML practitioners carefully curate test set labels to more accurately reflect model performance in real-world deployments.
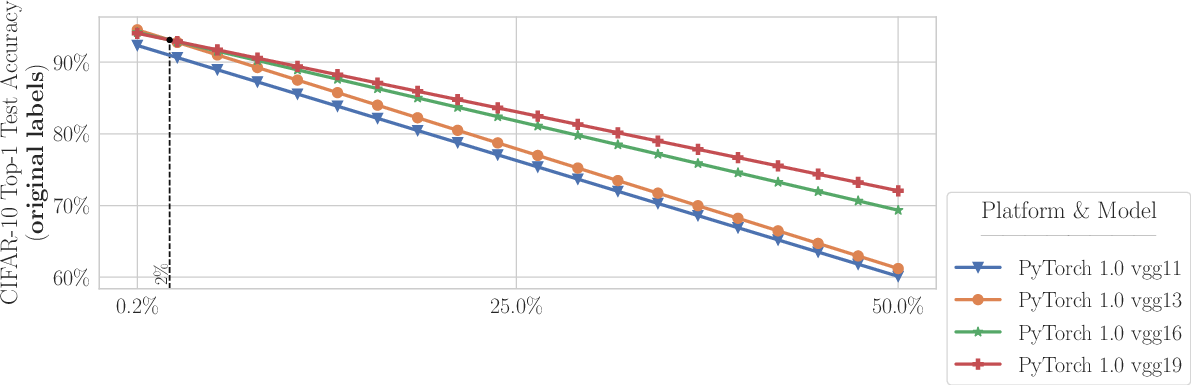
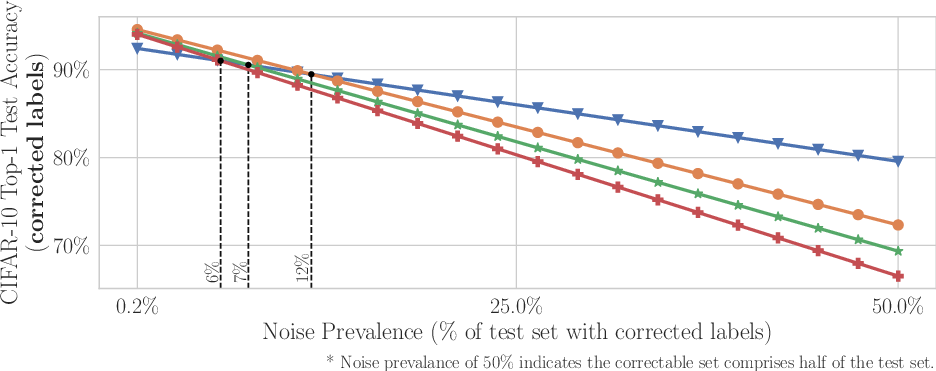
Figure 4: The impact of errors in CIFAR-10 datasets on model accuracy under various noise thresholds.
Conclusion
The paper concludes that significant label errors exist within test datasets commonly used for model benchmarking, which can alter perceived model rankings. It advises the ML community to incorporate label correction processes prior to model evaluation, ensuring benchmarks that better reflect true model performance capabilities. Future research should focus on understanding how these errors affect model generalization and explore strategies for error mitigation in data labeling practices.