- The paper presents C2, a jointly modeled system integrating coreference resolution and character linking for multiparty conversations, achieving notable F1 improvements.
- It leverages a mention-level self-attention module to refine contextual representations and aggregate speaker information across dialogue turns.
- Empirical results on the Friends dataset demonstrate robust gains for both main and secondary characters, enhancing overall dialogue understanding.
Joint Coreference Resolution and Character Linking for Multiparty Conversation: An Expert Overview
Problem Motivation and Task Challenges
The task of character linking in multiparty dialogues tackles the challenge of grounding conversational mentions to concrete real-world entities, particularly in domains where the majority of references use pronouns or nominal expressions rather than canonical named entities. The paper demonstrates that over 88% of person mentions in conversational transcripts are not named entities—a significant deviation from typical entity linking tasks and a complicating factor for conventional models reliant on knowledge bases and string similarity.
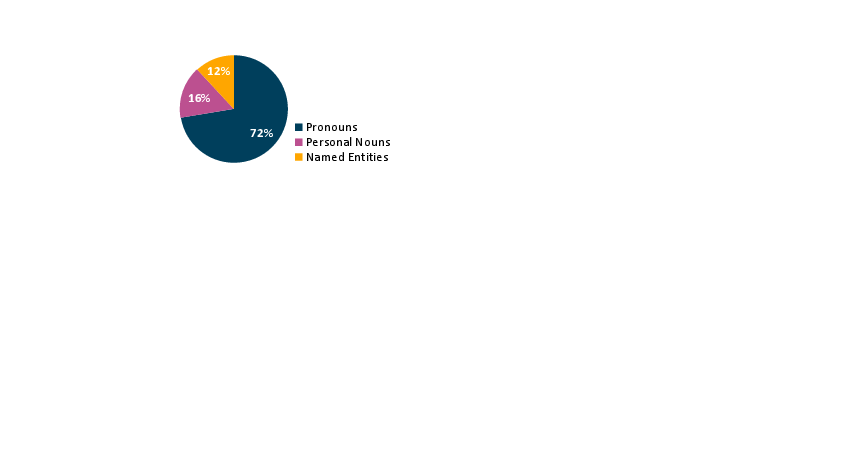
Figure 1: The distribution of conversational mentions highlights that the vast majority are pronouns or nominals, which substantially complicates the linking problem.
These phenomena exacerbate ambiguity and often reduce the utility of local context, particularly in informal settings such as television show transcripts. Linking the pronoun "he" or a phrase like "that girl" requires aggregation of rich conversational cues and cross-utterance dependencies that are not adequately captured by span-based approaches.
Model Design: Joint Modeling via C2
The proposed solution, C2, is a unified framework that jointly addresses coreference resolution and character linking. The central claim is that these two tasks are mutually reinforcing: robust coreference clusters boost the aggregation of contextual evidence for linking, while explicit grounding to character entities can regularize and inform pronoun and nominal resolution, especially in multiparty turn-taking settings.
A key architectural element is the mention-level self-attention (MLSA) module, which incrementally refines mention representations by integrating global conversational cues and speaker information. Initial span representations are extracted from a pre-trained transformer encoder (BERT or SpanBERT) and enhanced via speaker embeddings. These representations are further refined through multiple layers of MLSA, allowing for contextual integration from all mentions within a scene or document.
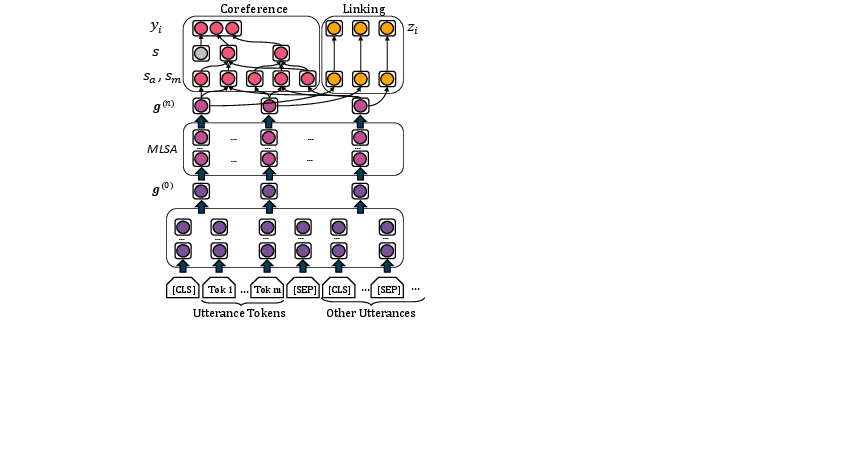
Figure 3: C2 utilizes shared mention encodings, refined over self-attention layers, as input for both coreference and linking modules—enabling cross-task information flow.
The model outputs are produced via two task-specific feed-forward networks: an antecedent selection mechanism for coreference resolution and a softmax-based character classification layer for entity linking. Losses for both tasks are jointly optimized, using negative log-likelihood for both the linking and coreference objectives.
Leveraging Coreference for Richer Linking Context
The contextual ambiguity in conversational mentions often makes local clues insufficient for correct linking, while coreference chains span multiple turns and speakers, aggregating disparate cues into comprehensive entity representations. For instance, the paper illustrates examples where only the aggregation of separate utterances—not their isolated spans—permits accurate resolution of mentions linked to a minor character.
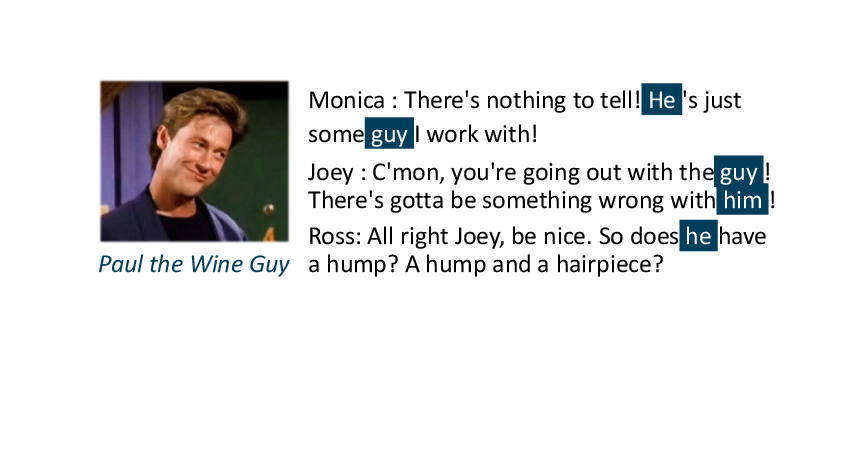
Figure 2: Coreference clusters act as context bridges, enabling information from multiple utterances to be pooled for more accurate character resolution.
Further, grounding mentions to explicit character entities provides top-down global supervision that can disambiguate pronouns when multiple valid options exist, as shown in multi-speaker interactions.
Empirical Results
The empirical evaluation uses the Character Identification V2.0 dataset, derived from annotated "Friends" TV show episodes. C2 is benchmarked against state-of-the-art baselines for both tasks, including ACNN (feature-based), C2F (transformer-based end-to-end coreference), and CorefQA (QA-formulated coreference). The model is evaluated under the singular-mention setting.
Key findings (for C2 with SpanBERT-Large):
- Coreference F1 (averaged over B3, CEAFϕ4, BLANC): 85.06—a 15% improvement over ACNN.
- Character Linking Macro F1: 81.1—a 26% improvement over ACNN.
The results are robust across main and secondary characters and demonstrate greater consistency in difficult cases requiring long-range context aggregation.
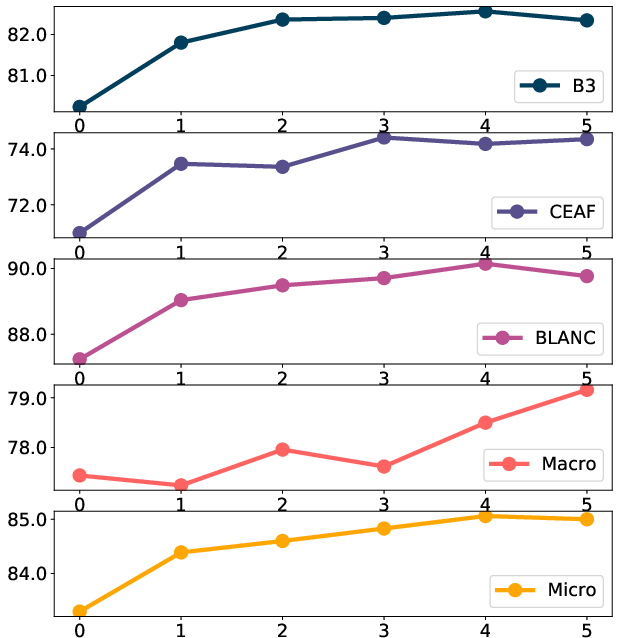
Figure 5: Increasing the number of MLSA layers generally yields monotonic improvements in F1 scores for both coreference and linking, validating the benefit of deeper context aggregation.
Module Contributions and Joint Learning Gains
Ablation studies show that:
- Removing MLSA layers degrades both coreference and linking F1 by up to 1.2 points.
- Removing the joint optimization (training tasks separately) results in significant performance drops for both tasks.
Thus, the cross-task inductive bias and deep representation sharing are key drivers of the observed gains.
Qualitative Analysis
Case studies highlight both strengths and residual challenges.

Figure 4: In example conversations, all mentions in correctly resolved clusters are consistently linked to the same character, except a single error involving real-world knowledge beyond what is present in context.
- Strengths: Improved handling of long-distance coreference, robustness for mentions referring to rarely mentioned characters.
- Weaknesses: Errors often arise where correct resolution requires world knowledge or inference about extra-dialogue facts (e.g., telephone conversation participants).
Theoretical and Practical Implications
The study corroborates long-standing hypotheses in NLP that coreference and entity linking are symbiotic. By sharing token- and span-level representations and optimizing over both tasks, the model benefits from both bottom-up aggregation and top-down regularization. The approach is a blueprint for more tightly coupled multi-task architectures for dialogue understanding, suggesting gains in downstream dialogue modeling, narrative structure inference, and conversational AI agents capable of tracking arbitrary entities.
Future Directions
Future work should explore the use of external knowledge sources to support cases requiring extra-linguistic inference, scale the approach to broader domains, and extend joint modeling to include group or plural mentions. There is also potential to adapt the approach to multimodal sources (video, audio), where non-textual cues may further inform mention resolution and linking.
Conclusion
The C2 framework establishes a new performance benchmark for both coreference resolution and character linking in multiparty conversational domains by tightly coupling mention representation refinement and inter-task learning. The joint modeling approach convincingly demonstrates the practical and theoretical advantage of cross-task integration for conversational entity grounding, inviting further research into richer joint architectures and broader applications in complex dialogue understanding.