Published 8 Jun 2020 in cs.LG, cs.NE, and stat.ML | (2006.04751v1)
Abstract: Gradient descent has been a central training principle for artificial neural networks from the early beginnings to today's deep learning networks. The most common implementation is the backpropagation algorithm for training feed-forward neural networks in a supervised fashion. Backpropagation involves computing the gradient of a loss function, with respect to the weights of the network, to update the weights and thus minimize loss. Although the mean square error is often used as a loss function, the general stochastic gradient descent principle does not immediately connect with a specific loss function. Another drawback of backpropagation has been the search for optimal values of two important training parameters, learning rate and momentum weight, which are determined empirically in most systems. The learning rate specifies the step size towards a minimum of the loss function when following the gradient, while the momentum weight considers previous weight changes when updating current weights. Using both parameters in conjunction with each other is generally accepted as a means to improving training, although their specific values do not follow immediately from standard backpropagation theory. This paper proposes a new information-theoretical loss function motivated by neural signal processing in a synapse. The new loss function implies a specific learning rate and momentum weight, leading to empirical parameters often used in practice. The proposed framework also provides a more formal explanation of the momentum term and its smoothing effect on the training process. All results taken together show that loss, learning rate, and momentum are closely connected. To support these theoretical findings, experiments for handwritten digit recognition show the practical usefulness of the proposed loss function and training parameters.
The paper presents a novel loss function that interlinks learning rate and momentum based on the golden ratio to optimize neural network training.
Experimental results on handwritten digit recognition using CNNs show improved accuracy (99.4%) compared to traditional parameter settings.
The study bridges biological synaptic transmission mechanisms with mathematical modeling, providing a theoretical basis for refined parameter selection.
The Golden Ratio of Learning and Momentum
Introduction
The paper "The Golden Ratio of Learning and Momentum" explores a novel information-theoretical loss function inspired by neural signal processing at synapses. Traditionally, the backpropagation algorithm serves as the cornerstone for training artificial neural networks (ANNs), specifically deep learning models, through gradient descent. A key challenge in this context is the empirical determination of optimal learning rate and momentum weight parameters, which influence the rate of convergence and stability of the learning process.
This research proposes a new framework wherein the loss function, learning rate, and momentum weight are intrinsically interconnected through the mathematical concept of the golden ratio, offering theoretically derived parameter values. The framework seeks to provide a formal understanding of the momentum term's smoothing role and its contribution to training efficacy. This paper also substantiates the theoretical framework with empirical evidence from experiments on handwritten digit recognition.
Theoretical Framework
Backpropagation and Synaptic Transmission
Backpropagation remains a vital technique for supervised learning in ANNs, where weights are adjusted to minimize differences between predicted outputs and expected results. This adjustment process involves computing gradients of a loss function, such as the sum of squared errors.
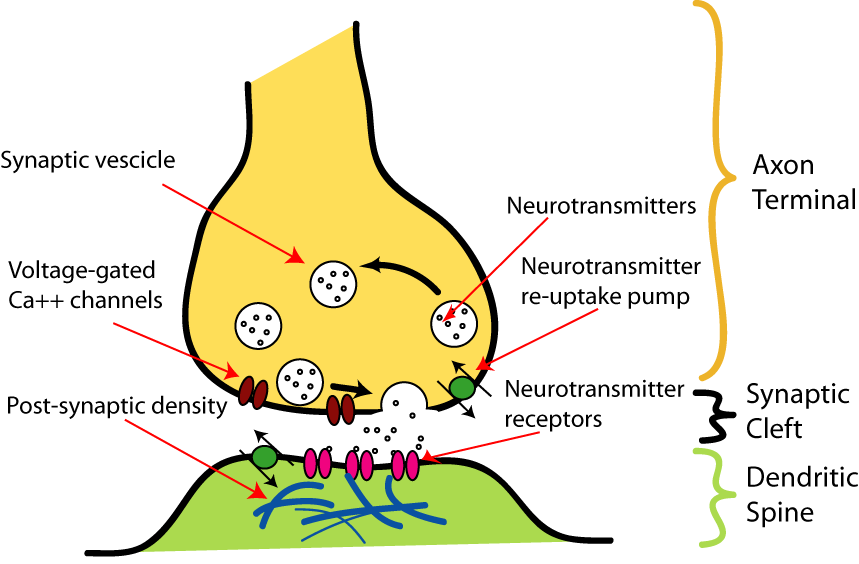
In biological neural systems, neurons communicate through synapses, using neurotransmitters for signal transmission. The concentration of calcium ions is pivotal in this process, influencing synaptic strength as depicted in signal transmission models of chemical synapses (Figure 1).
Figure 1: Signal transmission at a chemical synapse~\citep{julien2005}.
The proposed computational model links synaptic transmission to an expected information or energy measure expressed as:
E=−p⋅ln(p1−p),
where p signifies the probability of calcium ion entry, highlighting equilibrium at p=21.
Golden Ratio and Learning Parameters
The golden ratio, recognized across various domains, manifests in this context as the ratio where neural input equals output, indicating minimal uncertainty:
p=p1−p.
This paper utilizes the golden ratio to derive specific learning rate (η) and momentum weight (α) values that align with typical empirical observations. The golden ratio posits equilibrium as the optimal learning state, thus theoretically prescribing:
Momentum weight: α≈0.874,
Learning rate: η≈0.016.
Loss Function Development
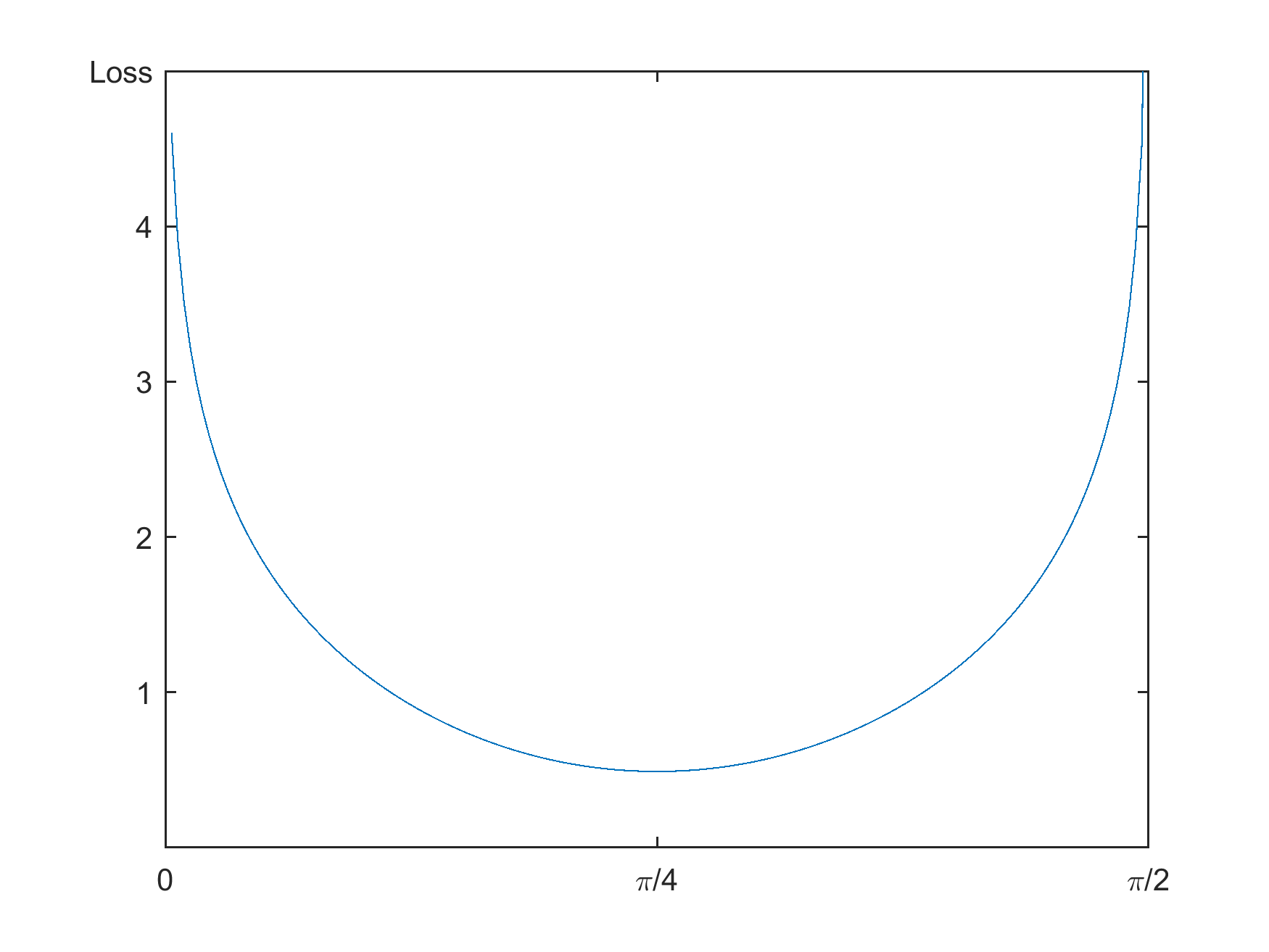
The loss function transitions from an information-theoretic perspective to a practical sigmoid-based form, facilitating training by constraining output within specified bounds. The loss function is defined as:
L(d)=1+exp(−LI(d)/2)1,
where LI(d) represents angular difference information loss. This paper refines the function further, optimizing with the golden ratio framework.
Figure 2: Information loss as defined by Eq.~\ref{informationLossFunction}.
Experimental Evaluation
The effectiveness of the proposed loss function and parameterization is assessed through experiments on handwritten digit recognition, employing a convolutional neural network (CNN) architecture (Figure 3).
Figure 3: Network architecture.
The CNN is evaluated using a dataset of artificially rotated digits from the MNIST database, achieving a notable classification accuracy of 99.4% when trained with the proposed loss function and derived parameters, as opposed to the 98.9% accuracy with traditional parameters and momentum inclusion.
These findings emphasize the impact of theoretically informed parameter selection, enhancing both performance and stability in training, as evidenced by reduced standard deviation in results.
Conclusion
The paper delineates a novel approach to ANN training, intertwining synaptic biological principles with mathematical formalisms to optimize learning. It provides a robust theoretical justification for commonly employed heuristic parameters, presenting an innovative perspective on the learning rate and momentum term interplay. The experimental results reinforce the applicability and advantages of this theoretical framework, potentially guiding future ANN training paradigms.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.