- The paper introduces a novel method that converts images into region adjacency graphs for classification using Graph Attention Networks.
- It leverages superpixel segmentation with GATs to assign adaptive weights to neighboring regions, enhancing feature representation.
- Experimental results demonstrate high accuracy on simpler datasets, highlighting both the benefits and challenges of RAG-based approaches.
Superpixel Image Classification with Graph Attention Networks
This essay provides a comprehensive summary of the research paper "Superpixel Image Classification with Graph Attention Networks" (2002.05544). The paper explores the application of Graph Neural Networks (GNNs), specifically Graph Attention Networks (GATs), for image classification using superpixel representations. The transformation of images into region adjacency graphs (RAGs) forms the basis of this methodology, which facilitates the handling of non-Euclidean data types such as spherical panoramas.
Introduction
The study introduces a novel approach to image classification by leveraging GNNs, a versatile framework that effectively models various domains. Traditionally, image classification models rely on convolutional neural networks (CNNs) that operate on rectangular grids [krizhevsky2012imagenet], but these are inadequate for domains such as spherical panoramas where data is inherently non-uniform. GNNs, particularly GATs, offer a potential solution by allowing for the modeling of images as graphs, where nodes represent superpixels and edges connect neighboring superpixels.
Methodology
The methodology comprises several key steps:
- Superpixel Segmentation: Each image is segmented into superpixels using the SLIC algorithm. These superpixels serve as nodes in the subsequent graph structure.
- Region Adjacency Graph Construction: A RAG is constructed where each node corresponds to a superpixel, and edges are formed between adjacent superpixels.
- Graph Attention Network (GAT) Application: The RAG is processed using GATs, a class of neural networks that combine graph convolutional operations with self-attention mechanisms, allowing nodes to assign different importance to their neighbors based on learned parameters.


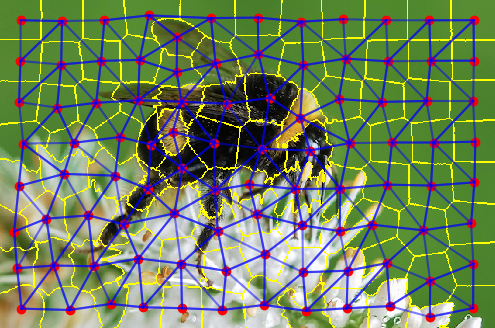
Figure 1: From left to right, the image to be converted into a RAG; the image with superpixel segmentation; the image with the generated region adjacency graph overlayed.
Experimental Results
The experiments conducted across multiple datasets, including MNIST, FashionMNIST, SVHN, and CIFAR-10, demonstrate that GATs effectively utilize the graph-based representations for classification tasks. The GAT models, when applied to these datasets, consistently outperformed traditional GNN models such as MoNET and exhibited competitive results even against other graph-based models like SplineCNN and Geo-GCN.
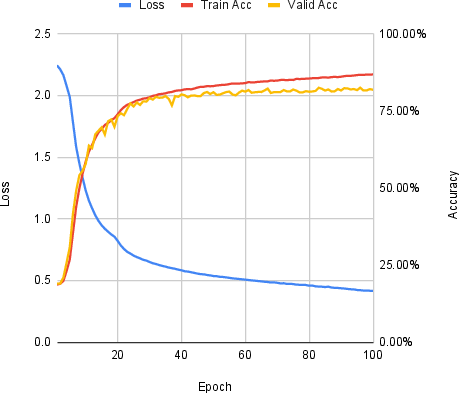
Figure 2: Training Curve for the Street View House Numbers 32×32 dataset.
The results indicate that although the use of RAGs with GATs does not achieve state-of-the-art performance on complex datasets such as CIFAR-10, it yields promising outcomes for simpler datasets like MNIST. The GAT models' test accuracy for MNIST-75 and FashionMNIST-75 were 96.19% and 83.07%, respectively, showcasing the effectiveness of the approach on datasets with reduced spatial complexity.


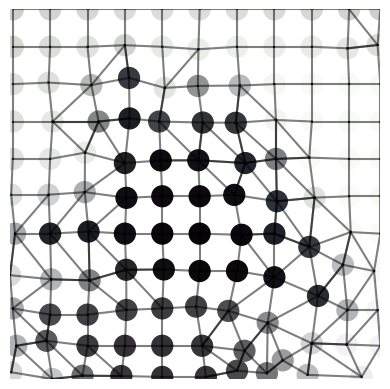





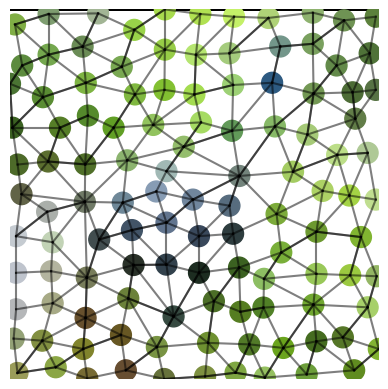








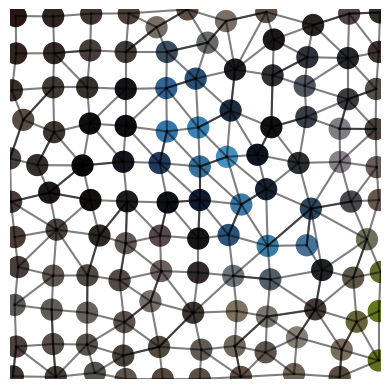
Figure 3: Examples showing the loss of information in the RAG procedure when using only the average of each channel, which negatively affects the performance of the network.
Discussion and Implications
The research highlights the advantages of employing GATs in graph-based representations for image classification, particularly in scenarios where traditional CNNs face challenges due to the geometric nature of the data. The approach shows potential for applications in non-Euclidean domains, such as omnidirectional images and point clouds, where a flexible representation like graphs can naturally model the data without topology issues.
However, the transformation of images into RAGs inherently leads to information loss, which imposes limitations on the classification performance for complex images. Future research could focus on mitigating this information loss and investigating alternative feature vectors to enhance the richness of the node features. Moreover, advancements in scaling GNN architectures to handle larger graphs efficiently could extend the applicability of this methodology to more complex datasets.
Conclusion
The study establishes a foundational methodology for utilizing GNNs in image classification tasks through superpixel representations. While challenging data types like CIFAR-10 reveal the constraints of current models in handling information loss, the approach demonstrates considerable promise for domains where conventional methods fall short. Future developments in this domain could see improvements in handling non-Euclidean data, leading to broader applications across diverse fields within machine learning and computer vision.