- The paper presents MetaGenRL, which meta-learns neural objective functions to effectively guide policy updates with improved generalization.
- It employs population-based learning with second-order gradients, outperforming traditional RL algorithms in sample efficiency and adaptation.
- Empirical results on continuous control tasks demonstrate robust performance across unseen environments, highlighting the benefits of learned objectives.
Introduction
The paper "Improving Generalization in Meta Reinforcement Learning using Learned Objectives" (1910.04098) introduces MetaGenRL, a meta reinforcement learning (meta-RL) algorithm designed to enhance the generalization capabilities of learned objectives across different environments. MetaGenRL draws inspiration from the process of natural evolution, leveraging the collective experiences of multiple complex agents to meta-learn a low-complexity neural objective function. This function instructs future learning by encapsulating experiences across various environments, aiming to overcome the limitations of human-engineered reinforcement learning algorithms which often struggle with generalization.
MetaGenRL is a gradient-based meta-RL framework where the objective functions themselves are learned, rather than relying on fixed hand-crafted rules. The architecture uses second-order gradients to enhance sample efficiency, differentiating it from previous approaches like Evolved Policy Gradients (EPG). This allows MetaGenRL to generalize to environments substantially different from those seen during training, even outperforming several fixed reinforcement learning algorithms.
The core mechanism involves using a parameterized objective function, Lα, implemented as a neural network. This function receives trajectories (s0:T−1,a0:T−1,r0:T−1), predicted actions, value estimates, and outputs an objective value. The overarching idea is to refine policies by leveraging off-policy second-order gradients computed via a critic network, similar to DDPG, but with an added layer of meta-learned objectives.
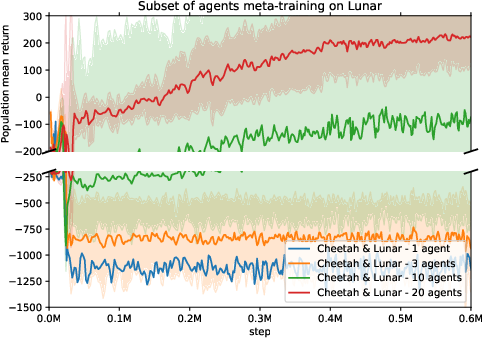
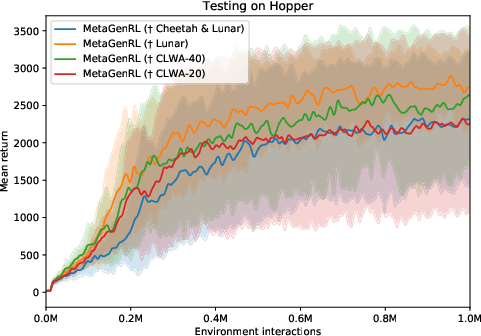
Figure 2: Stable meta-training requires a large population size of at least 20 agents. Meta-training performance is shown for a single run with the mean and standard deviation across the agent population.
Practical Implementation
- Population-Based Learning: MetaGenRL utilizes a population of agents simulating different environments for robust meta-learning. Each agent iteratively updates policy parameters through Lα, sharing insights across the agent population.
- Sample Efficiency: By utilizing second-order gradients and off-policy data, MetaGenRL achieves higher sample efficiency than prior methods like EPG, which require extensive simulations.
- Neural Objective Function: The objective function, Lα, is parameterized using an LSTM network that processes trajectories in reverse. This function is capable of varying input dimensions due to environment-specific action and state differences, maintaining versatility and generalization power.
- Ablation Studies and Adaptation: Experiments reveal that aspects like the inclusion of value estimates and trajectory processing order significantly impact the stability and performance of meta-learning, shedding light on necessary conditions for effective generalization.
Empirical Analysis and Results
MetaGenRL was evaluated using diverse continuous control tasks, demonstrating substantial improvements over traditional RL algorithms such as PPO, REINFORCE, and RL2. It shows a marked ability to generalize, evidenced by its success at applying learned objectives across unseen environments, notably achieving competitive results with DDPG under specific conditions.
In ablation studies, the importance of parameters like the size of the agent population and the incorporation of multiple environments during training were highlighted, indicating that larger populations and diverse training environments improve stability and performance.
The evaluation metrics consistently demonstrate MetaGenRL's strength in training randomly initialized agents to effectively learn optimal policies in both familiar and novel scenarios.
Figure 3: Meta-training on Cheetah, Lunar, Walker, and Ant with 20 or 40 agents; meta-testing on the out-of-distribution Hopper environment. We compare to previous MetaGenRL configurations.
Conclusion
MetaGenRL represents a significant advance in the field of meta-RL by meta-learning the objectives used to guide policy updates. Its ability to generalize across environments substantiates the benefit of treating learning rules as learnable functions. The insights gained from this research open avenues for further exploration into adaptive, environment-agnostic meta-learning strategies that exploit richer meta-contextual information and enhance long-term learning capabilities in AI agents. Future research could explore extending the input capabilities of Lα or improving introspection and representation learning within the objective function to further refine learning dynamics.

