- The paper introduces GPCR-Filter, a deep learning framework that fuses protein sequence embeddings with ligand graph features to improve GPCR modulator discovery.
- The methodology leverages Transformer-style cross-attention to interpret binding pockets, achieving high precision in both in-distribution and out-of-distribution evaluations.
- Experimental validation demonstrated the framework’s capability by identifying potent 5-HT1A agonists and outperforming state-of-the-art models in predictive performance.
GPCR-Filter: A Deep Learning Framework for Efficient and Precise GPCR Modulator Discovery
Introduction
GPCRs represent the largest family of cell-surface receptors targeted by pharmaceutical agents and are critical for mediating complex physiological responses. Despite the clinical significance of identifying functional GPCR modulators, the discovery pipeline is hampered by the intrinsic dynamism and allostery of GPCRs and the paucity of comprehensive structural data. This paper introduces GPCR-Filter, a sequence-focused deep learning framework designed to address the challenges of GPCR modulator discovery by leveraging large-scale, curated experimental data, representation learning from advanced protein LLMs, and attention-based fusion with ligand graph representations.
GPCR-Filter Model Architecture and Workflow
GPCR-Filter integrates two state-of-the-art representation learning elements: residue-level embeddings from the ESM-3 protein LLM for GPCR sequences and per-atom graph features encoded by a GNN for ligand structures. The model fuses these in a Transformer-style decoder using ligand-to-protein cross-attention to capture functional receptor-ligand relationships. The full workflow positions GPCR-Filter as a post-docking filter to maximize in vitro hit rates via pure sequence/SMILES-based prioritization.
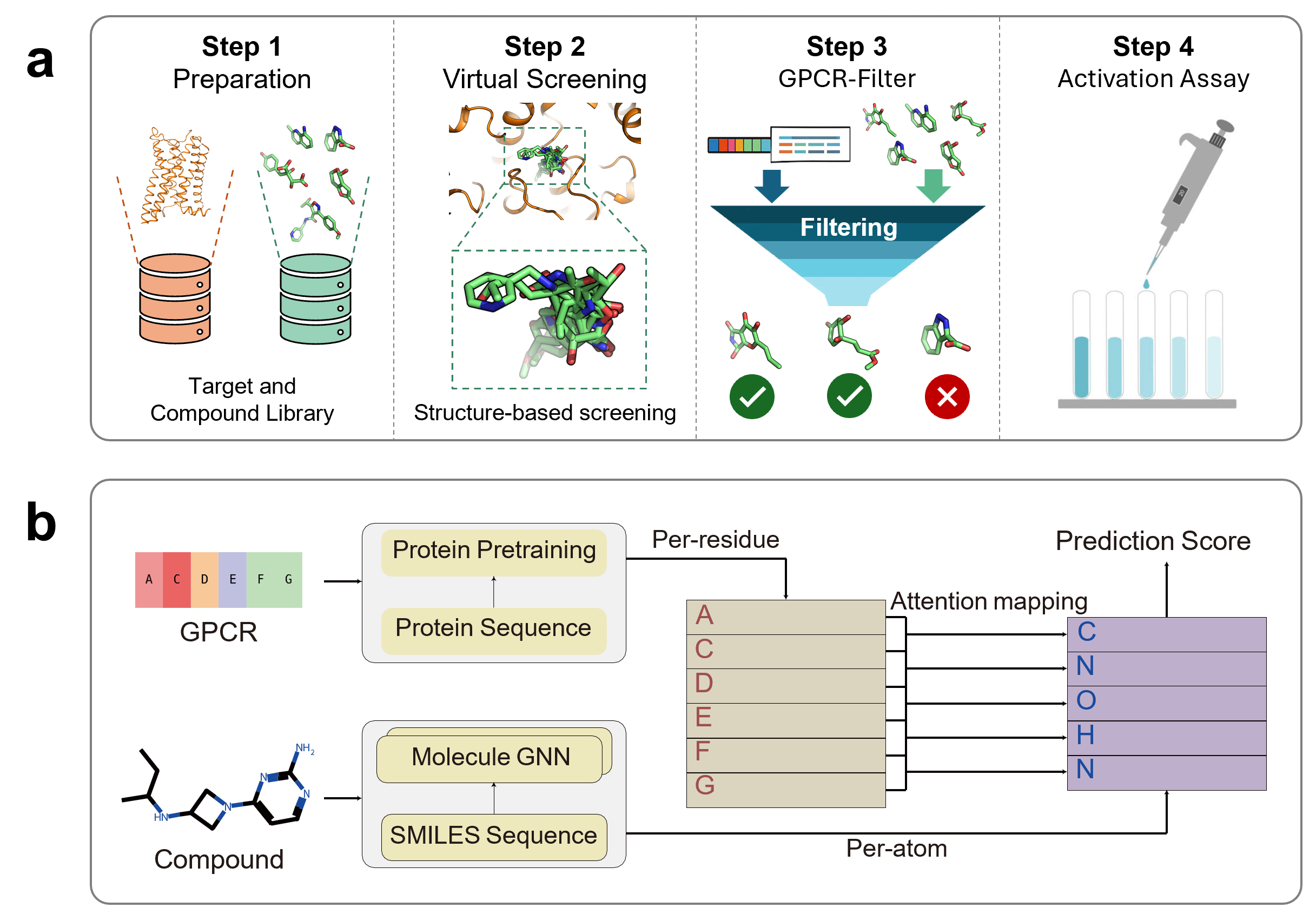
Figure 1: The end-to-end discovery pipeline integrates initial structure-based virtual screening with GPCR-Filter to prioritize ligand candidates, based on a cross-attention-fused architecture that decodes the interaction potential from sequence and SMILES.
Performance is contingent on a dataset comprising >90,000 curated and experimentally validated human GPCR–ligand pairs, with comprehensive negatives constructed through stringent, balanced subsampling, and sequence/ligand curation to canonical forms.
Performance benchmarking employed three increasingly challenging evaluation regimes: (1) random splits (in-distribution ligand and receptor combinations), (2) intra-target splits (unseen ligands per receptor), and (3) inter-target splits (completely unseen GPCRs). In all settings, comparisons were made against sequence-based baselines TransformerCPI2.0 and ConPLex.
GPCR-Filter markedly surpassed previous SOTA models, especially in out-of-distribution scenarios. In the random split, it achieved an AUC of 99.0% and AP of 98.9%. Importantly, even in the inter-target split (novel receptors), AUC remained at 80.3%, with clear separation versus a >16% reduction for TransformerCPI2.0 and even sub-random performance for ConPLex. These results confirm both high in-distribution discriminative power and strong transferability in receptor sequence space.
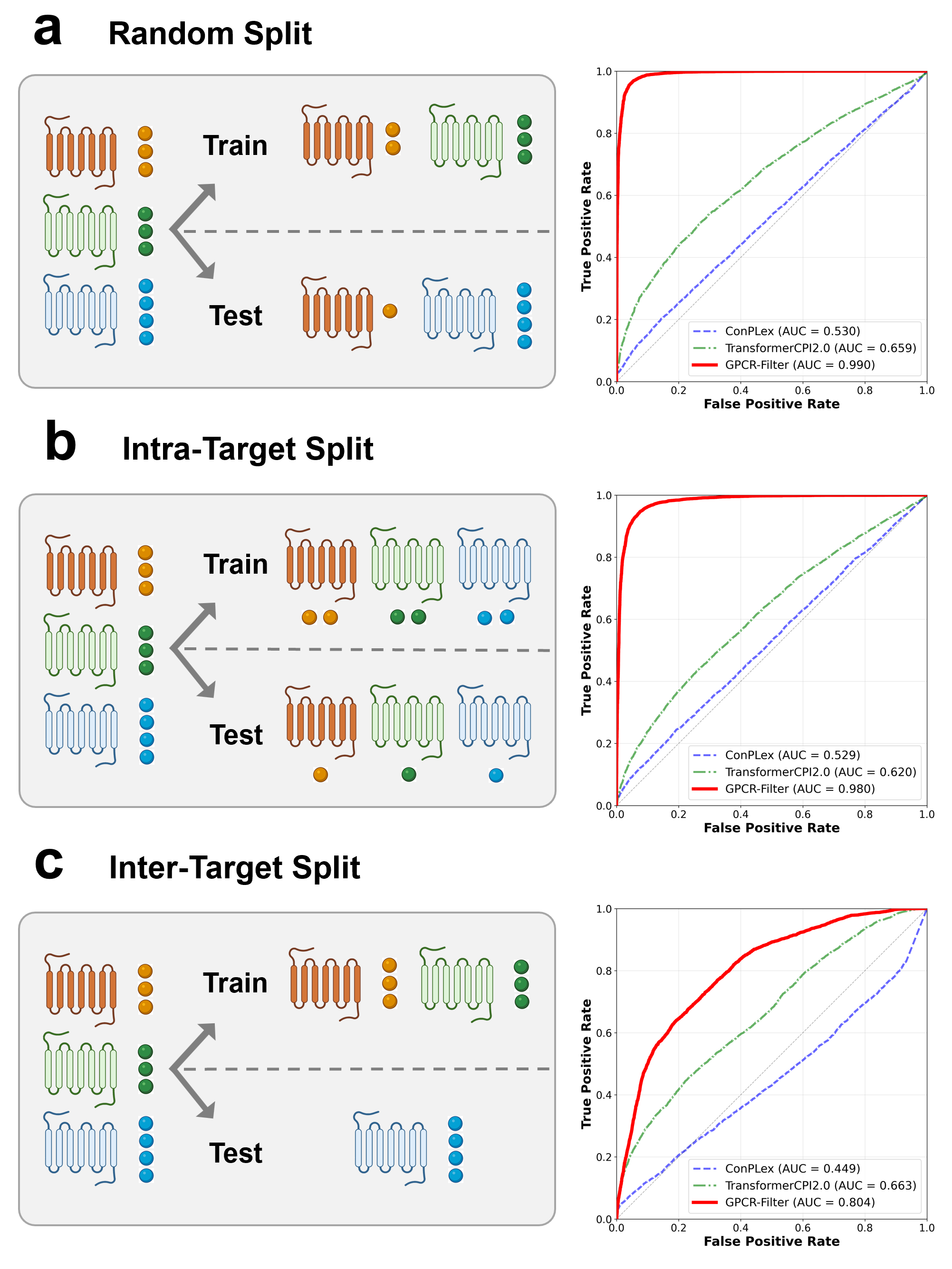
Figure 2: Summary of dataset splits and ROC performance across evaluation protocols, illustrating GPCR-Filter’s maintained discriminative power even under stringent inter-target settings.
This robustness was maintained under alternative protocols (scaffold split, GPCR-family hold-out), securing the utility of GPCR-Filter for generalizable modulator discovery beyond mere memorization of training pairs.
Mechanistic Interpretability via Attention Analysis
The model’s interpretability is supported analytically at the sequence, chemical, and structural level. Hierarchical clustering of ligand fingerprints aggregated by GPCR reveals a latent chemical organization, mapping receptors to regions of modulatory chemical space suited for attention-based learning. At the structural level, cross-attention weights derived from the ligand graph-level token robustly highlight crystallographic pocket residues. Across two PDB-solved GPCR complexes, the Top-20 attended residues are reliably enriched in the binding pocket regardless of training regime, validating that GPCR-Filter’s cross-modal fusion focuses on authentic physical determinants rather than spurious correlations.
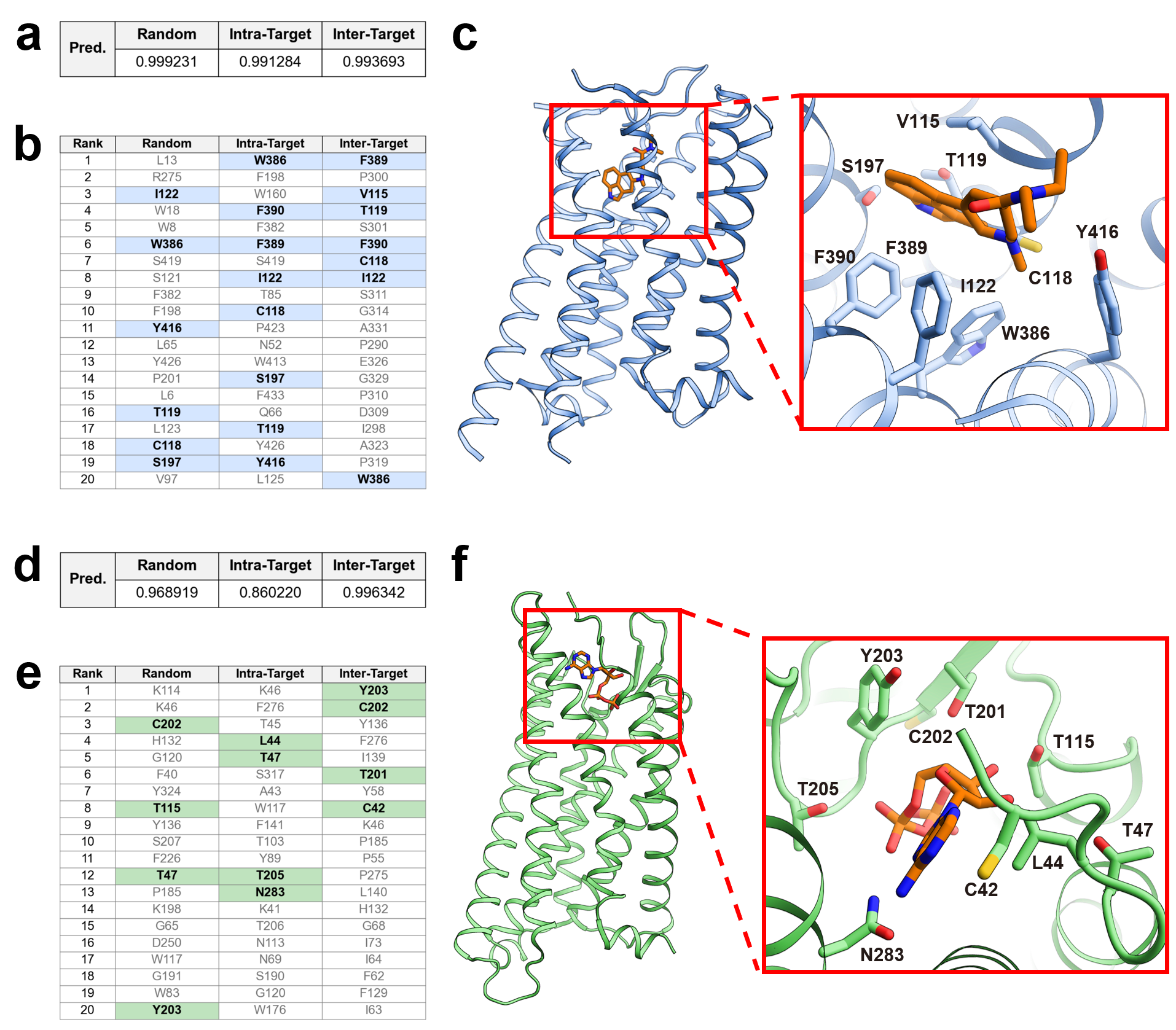
Figure 3: For two GPCR-ligand complexes, attention-focused residues align with crystallographic binding pockets, and prediction scores are robust across all split regimes, confirming physically meaningful model focus.
Experimental Validation: Prospective 5-HT1A Agonist Discovery
To assess practical discovery impact, GPCR-Filter was prospectively applied in a 5-HT1A virtual screening campaign. Following large-scale structure-based docking, GPCR-Filter was used to prioritize candidates for testing. Four micromolar-level agonists with diverse scaffolds were confirmed in a GloSensor-cAMP assay. Their potency, defined by EC50 values, and efficacy, as maximum effect Emax, established these as prioritized hits.
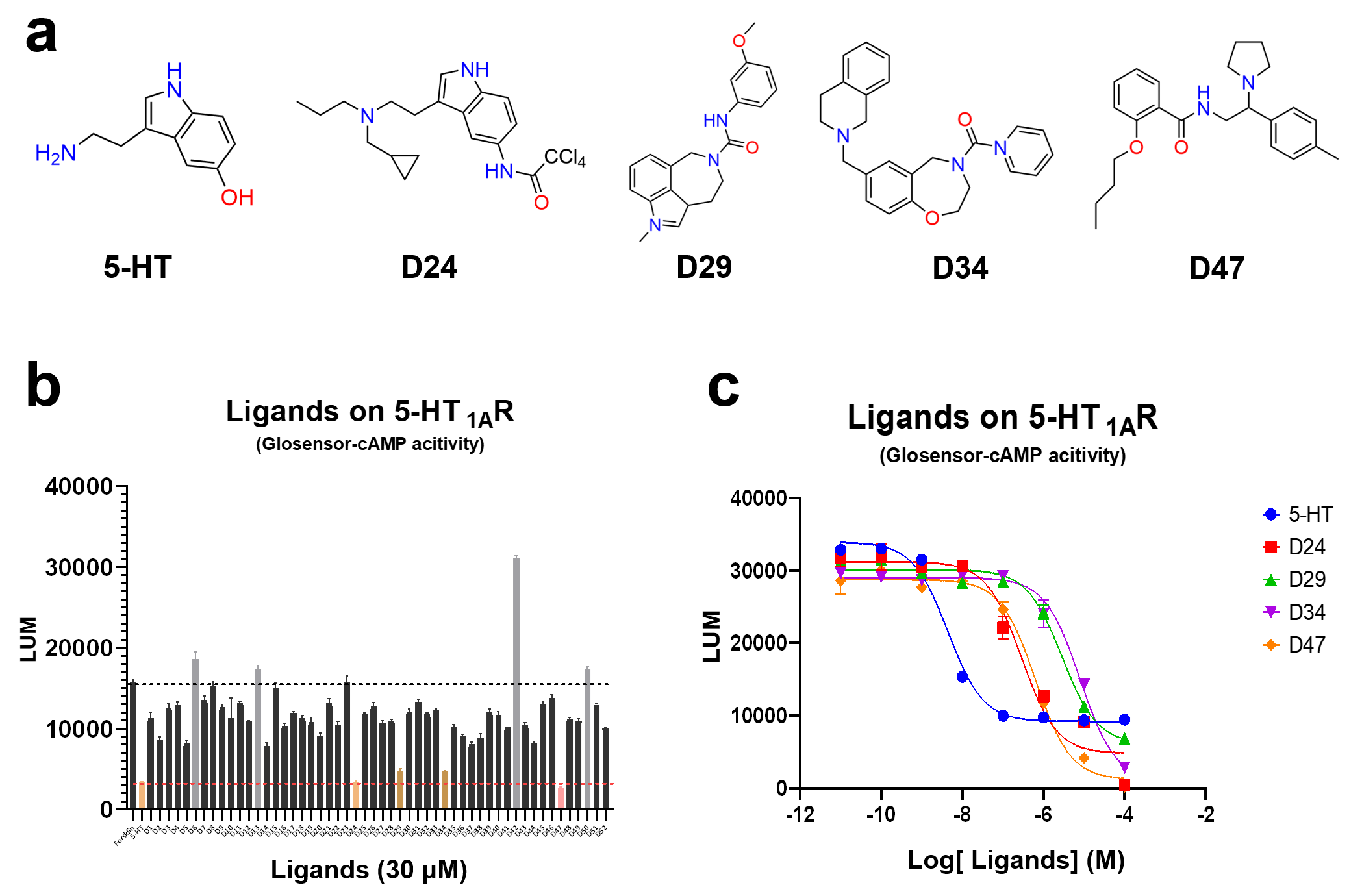
Figure 4: Experimental validation process demonstrates discovery of multiple potent and efficacious 5-HT1A receptor agonists among top-ranked GPCR-Filter predictions.
These results underscore GPCR-Filter’s capacity to enrich true actives among virtual screening hits, confirming its applicability and translational relevance for drug discovery.
Discussion and Implications
GPCR-Filter demonstrates that integrating chemically structured, GPCR-specific training data with multi-level attention architectures yields quantitative and practical advances in ligand discovery. The method’s ability to generalize, attribute importance to biophysically meaningful features, and directly enhance downstream experimental hit rates addresses core obstacles in current DTI modeling for GPCRs.
Outstanding limitations include the reliance on negative sampling procedures that may still include latent positives, and the allowance of ligand duplication in inter-target splits that may facilitate chemotype learning shortcuts—both are amenable to further experimental protocol tightening.
The adoption of advanced protein LMs (ESM-3) coupled with cross-attention fusion invites application to pharmacologically challenging receptor families beyond GPCRs, especially where structure-based approaches are hampered by absence of high-resolution complexes or noncanonical allosteric mechanisms.
Conclusion
GPCR-Filter is established as a high-precision, interpretable, and scalable component for next-generation AI-driven GPCR modulator discovery. Its sequence-centric approach, leveraging large-scale curated data, robust attention-based fusion, and validated predictive performance marks a concrete advance over prior sequence-only DTI models. Future developments will focus on incorporating negative sampling refinements, enforcing stricter out-of-distribution evaluations, and extending architecture components to additional receptor superfamilies, with the ultimate goal of generalizing functional modulator discovery throughout the proteome.
Reference: "GPCR-Filter: a deep learning framework for efficient and precise GPCR modulator discovery" (2601.19149)