The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation
Abstract: Recent advances in video generation have produced models capable of synthesizing stunning visual content from simple text prompts. However, these models struggle to generate long-form, coherent narratives from high-level concepts like dialogue, revealing a ``semantic gap'' between a creative idea and its cinematic execution. To bridge this gap, we introduce a novel, end-to-end agentic framework for dialogue-to-cinematic-video generation. Central to our framework is ScripterAgent, a model trained to translate coarse dialogue into a fine-grained, executable cinematic script. To enable this, we construct ScriptBench, a new large-scale benchmark with rich multimodal context, annotated via an expert-guided pipeline. The generated script then guides DirectorAgent, which orchestrates state-of-the-art video models using a cross-scene continuous generation strategy to ensure long-horizon coherence. Our comprehensive evaluation, featuring an AI-powered CriticAgent and a new Visual-Script Alignment (VSA) metric, shows our framework significantly improves script faithfulness and temporal fidelity across all tested video models. Furthermore, our analysis uncovers a crucial trade-off in current SOTA models between visual spectacle and strict script adherence, providing valuable insights for the future of automated filmmaking.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI to turn a simple conversation (dialogue) into a short, movie-like video that looks and feels like a real scene. Instead of asking a video model to “just make something cool,” the authors say the missing piece is the script—the detailed plan filmmakers use. So they build a “team” of AI helpers that first writes a professional script, then directs a video based on it, and finally reviews the result like a film critic.
What questions is the paper trying to answer?
The authors focus on a few clear questions anyone who’s tried making a film would care about:
- How can we turn rough dialogue into a full, shootable script with shot types, camera moves, timing, and character positions?
- How can we keep longer videos consistent across multiple clips, so characters don’t change faces, outfits, or positions randomly?
- How do we measure if the video actually follows the script moment-by-moment, not just “kind of matches” overall?
- Do today’s best video models do better when given a real script, and what trade-offs do they have?
How did they do it?
The method works like a small film crew made of three AIs, plus a new training and testing set.
The three AI “agents”
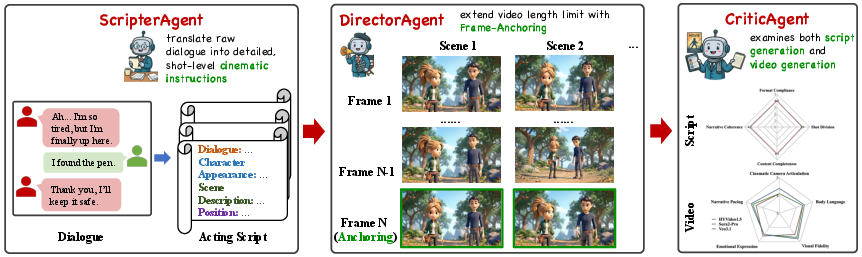
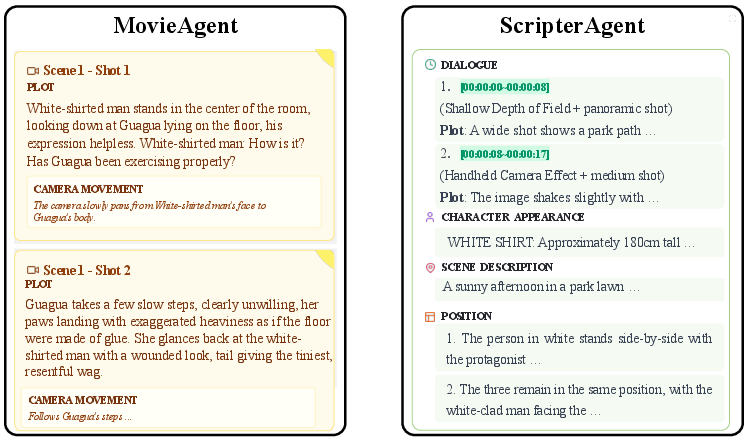
- ScripterAgent (the scriptwriter): Takes the dialogue and turns it into a detailed, step-by-step cinematic script. Think of it like a pro assistant who decides shot types (close-up, wide shot), camera movements, who stands where, timing, and mood.
- DirectorAgent (the director): Uses that script to guide existing video models so the final video is smooth and consistent across multiple parts.
- CriticAgent (the reviewer): Scores scripts and videos on how technically correct and cinematic they are, a bit like a judge at a film festival.
The training data: ScriptBench
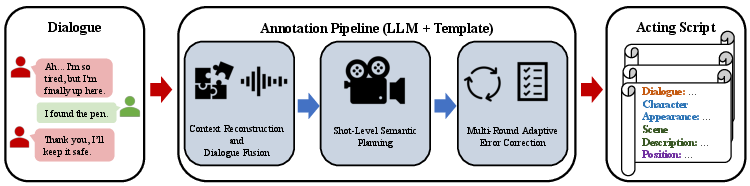
The team built a new dataset called ScriptBench with 1,750 examples. Each example includes dialogue, audio, where characters are, and a carefully made shot-by-shot script. They created it using a multi-step, expert-checked process that:
- Understands the scene (who’s speaking, where they are, what’s happening).
- Breaks it into shots that make sense for the story and fit within current video model limits (usually short clips).
- Automatically checks for common mistakes (like a character “teleporting” across the room) and fixes them in multiple rounds.
How ScripterAgent learns to write scripts
- First, Supervised Fine-Tuning (SFT): This is like teaching by example. The model copies the structure and style of real scripts until it can produce clean, complete shot lists on its own.
- Then, Reinforcement Learning (RL): This is like a game with points. The model writes several script options; the system scores them and nudges the model toward better choices. The score mixes:
- Rule checks (Is the format correct? Is everyone in the right place?)
- Human taste (Do directors like the pacing, emotions, and visuals?)
- A method called GRPO (Group Relative Policy Optimization) helps the model pick the best choices among several options, which is useful since there can be many valid ways to film the same scene.
How DirectorAgent keeps videos consistent
Current video models make short clips (like 8–12 seconds). Stitching many clips together can cause problems: characters may change faces or clothes, or the room might look different. The DirectorAgent fixes this with two ideas:
- Smart cutting: It splits the script at natural movie points (like at the end of a line or a camera change), not in the middle of moving shots.
- Frame anchoring: It takes the very last frame (like a photo) from one clip and feeds it to the next as a “starting point.” This helps keep the same faces, costumes, and room layout from scene to scene.
How CriticAgent and metrics evaluate results
- CriticAgent grades both scripts and videos on story flow, camera work, emotions, and more.
- They also introduce a new metric called VSA (Visual-Script Alignment). Instead of only checking if the right things appear, VSA checks if they appear at the right time. For example, if the script says “close-up on Alex looking worried from 0:10 to 0:15,” VSA checks if that actually happens in those seconds.
What did they find, and why is it important?
- The “script-first” approach works. ScripterAgent wrote better scripts than other methods in both automated checks and human director ratings—especially for dramatic tension and vivid visual details.
- The RL “taste tuning” step matters. Teaching with rules alone made the scripts tidy, but adding the reward-based stage made them more cinematic and emotionally engaging.
- Videos improved across the board when guided by these scripts. No matter which video model they tried (like Sora2-Pro or HYVideo1.5), giving it a structured script led to:
- Better faithfulness to the planned story
- More consistent characters and backgrounds
- Smoother pacing and shot timing
- The new VSA metric went up too. This shows the video matched the script’s timing more closely, not just the overall look.
- There’s a real trade-off between “wow factor” and strict storytelling. Some models (like Sora2-Pro) shine at stunning, physically realistic visuals; others (like HYVideo1.5) are better at following the script exactly. This helps creators pick the right tool for the job.
Why does this matter?
This work shows a practical path toward AI-assisted filmmaking that feels professional: start with a strong script, then let the AI direct based on that plan, and finally evaluate carefully. The benefits include:
- More reliable long scenes, even with today’s short-clip video models
- Better control over story beats, camera choices, and emotions
- Clear measurements (like VSA) for when a video truly follows a script
Looking ahead, this approach could power tools for YouTubers, indie filmmakers, game cutscenes, and education, making it easier to turn ideas and dialogue into polished, coherent videos. Future improvements could add finer control (like perfect lip-sync) and more diverse cinematic styles, bringing us closer to automated, high-quality storytelling.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper to guide future research.
Dataset and benchmark (ScriptBench)
- Limited test size (50 instances) and short average duration (~15.4 s) constrain statistical power and claims about long-horizon generalization; report CIs/significance and evaluate on substantially longer scenes (1–3+ minutes).
- Domain bias toward “high-fidelity cinematic cutscenes” (likely from games/films) with unclear licensing and demographic diversity; assess generalization to real-world footage, varied genres (documentary, sports, UGC), non-Western cinematic styles, and multilingual dialogue.
- Trimodal context (dialogue, audio, character positions) is provided in curation but not clearly leveraged in model training/inference; quantify gains from incorporating audio prosody, pauses, overlap, and positional tracks directly into ScripterAgent.
- Automated verification yields a 94% pass rate with only 60% human auditing; identify residual systematic errors (e.g., prop continuity, subtle staging violations) via full audits on a representative subset and release error taxonomies.
- Hard caps and rules used in annotation (e.g., 10 s shot cap, avoiding segmentation during complex camera moves) may bias scripts toward certain styles; study their impact and introduce datasets with relaxed or style-specific constraints.
- Provide detailed data statements (sources, licenses, genre/language distribution, character/scene diversity) and release comprehensive annotation templates, prompts, and validation logic to improve reproducibility.
ScripterAgent modeling and training
- The model is text-only (Qwen-Omni-7B) despite dataset trimodality; evaluate multimodal ScripterAgents that condition on speech prosody, timing, and acoustic emotion to improve pacing and emotion-to-shot planning.
- Preference model is trained on ~500 samples scored by three directors; report inter-rater reliability, calibration, and out-of-domain robustness, and investigate larger, more diverse rater pools to avoid aesthetic homogenization.
- Potential reward hacking/overfitting to structural validators and the small preference model; add adversarial tests and holdout evaluators to detect gaming and measure true generalization.
- Missing ablations on GRPO design choices (α weight between structural/human rewards, group size K, KL coefficient β, sampling temperature, length penalties); quantify sensitivity and stability across seeds.
- Style controllability is underexplored; develop conditioning for genre, director style, cultural conventions, and editing grammar (e.g., 180° rule, shot–reverse–shot), and measure adherence.
- Editability and iterative workflow support are not evaluated; benchmark script revision loops (user-in-the-loop edits, constraint violations, and recovery) and latency/cost trade-offs for practical use.
- Generalization to sparse or no-dialogue scenes (action sequences, montage, musical numbers) is untested; create tasks where visual planning must be inferred from non-dialogue cues or high-level beats.
DirectorAgent and execution strategy
- Frame-anchoring uses only the last frame as a visual prior; investigate error accumulation, exposure drift, and compounding artifacts across many segments, and compare against stronger continuity mechanisms (latent/state carryover, 3D scene graphs, identity embeddings, optical flow or pose continuity, inpainting-based handoffs).
- Audio-visual synchronization (lip sync, prosody-aligned cuts) remains a stated limitation; integrate speech-aligned beat tracking and viseme-driven control, and introduce objective A/V sync metrics.
- Continuity control beyond identity (lighting continuity, prop states, makeup/wardrobe evolution, time-of-day, weather) is not explicitly modeled or measured; add constraints and detectors for these dimensions.
- Mapping script-level camera parameters to black-box video generators is unspecified; document control interfaces per model, evaluate cross-model portability of directives, and explore adapters/controlnets for camera motion fidelity.
- Scalability to multi-minute narratives is not empirically demonstrated; measure performance and failure modes over longer horizons with many segment transitions, including computational cost and latency.
- No ablation of DirectorAgent components; isolate contributions of intelligent segmentation vs. frame anchoring vs. prompt phrasing (“Continuing from the previous scene”).
Evaluation methodology and metrics
- Potential evaluation circularity: gemini-2.5-pro is used both to annotate (in curation pipeline) and to evaluate (CriticAgent); quantify bias by cross-checking with independent LLM evaluators and larger human panels.
- VSA (CLIP-based per-frame similarity within script-defined windows) lacks validation against human judgments of temporal-semantic alignment; report correlations, error analyses, and robustness to rephrasings and visual paraphrase.
- VSA may miss motion- and action-level fidelity, identity tracking, and edit continuity; extend with temporal encoders, action detectors, identity matchers, and edit-aware metrics (eyeline matches, 180° rule compliance, match-on-action).
- Human evaluation scales and protocols are under-specified (rater counts, sampling, confidence intervals, statistical significance); standardize, report reliability, and release guidelines/prompts to reduce evaluator variance.
- Trade-off between spectacle and script adherence is observed but not explained; analyze causal factors (prompt length budget, model architecture, guidance scales) and propose controllable knobs to navigate the trade-off.
- Lack of baselines specifically optimized for cinematic planning (e.g., recent director/film-agent systems) limits comparative conclusions; include stronger, purpose-built baselines and report per-genre breakdowns.
Reproducibility and transparency
- Many implementation details (exact prompts, script schema variants, segmentation thresholds, anchor extraction settings per model, decoding parameters) are not fully specified; release full configs and seeds.
- The reported naming inconsistency (ScriptAgent vs. ScripterAgent) and LaTeX issues in equations hinder clarity; provide a unified spec and corrected mathematical formulations.
- Dependence on closed-source models (gemini-2.5-pro, Sora, Veo) threatens reproducibility; replicate results with open models and quantify performance gaps/sensitivity to proprietary model updates.
Safety, ethics, and legal considerations
- Copyright and likeness concerns for “high-fidelity cinematic cutscenes” are not addressed; provide licensing verification, usage constraints, and data filtering for protected content and identifiable individuals.
- Risks of generating convincing deepfakes and misaligned portrayals (bias in character depiction, cultural stereotypes) are not evaluated; include safety audits, bias diagnostics, and mitigation mechanisms in both scripts and videos.
- Absence of content safety controls in planning (e.g., violent choreography, dangerous stunts) and execution; integrate safety classifiers and human-in-the-loop checkpoints for high-risk content.
Broader open questions
- Can end-to-end training with script tokens as conditioning improve adherence compared with black-box orchestration? Explore joint training/fine-tuning of video generators with script-conditioned controls.
- How to support collaborative co-creation (director, editor, cinematographer) with role-specific constraints and multi-agent negotiation?
- What is the minimal script granularity that maximizes fidelity without degrading aesthetics or creativity? Study the information–fidelity–aesthetics frontier under prompt-length constraints.
Practical Applications
Immediate Applications
The following applications can be deployed with existing models and workflows, leveraging the paper’s ScripterAgent (dialogue-to-script), DirectorAgent (cross-scene orchestration with frame-anchoring), CriticAgent (AI evaluation), and the ScriptBench dataset plus VSA metric.
- Film/TV previsualization co-pilot (sector: media/entertainment)
- Use case: Turn dialogue drafts or table reads into shot-accurate previz videos and detailed shot lists.
- Workflow/product: “Script-to-Previz” pipeline that exports ScripterAgent’s JSON to an EDL/timeline and calls DirectorAgent to generate coherent clips via HYVideo/Sora/Veo; CriticAgent scores cuts for quality control.
- Assumptions/dependencies: Access to high-end video generation APIs; human-in-the-loop for final polish; licensing for reference audio; compute budget.
- Advertising pitch simulator (sector: marketing/advertising)
- Use case: Convert ad copy and dialogue into storyboard-level scripts and coherent spec videos for client reviews.
- Workflow/product: SaaS “PitchViz” that picks a video model based on the visual–fidelity trade-off identified in the paper; frame-anchoring ensures brand asset continuity across scenes.
- Assumptions/dependencies: Brand asset libraries; legal review for synthetic content use; time limits of video generators.
- Game cutscene prototyping (sector: gaming/software)
- Use case: Rapidly prototype dialogue-driven cutscenes from narrative scripts, preserving character identity across shots.
- Workflow/product: Unity/Unreal plug-in that ingests dialogue, produces ScripterAgent shot plans, and renders previz via DirectorAgent; exports timing to engine sequencers.
- Assumptions/dependencies: Engine integration; IP constraints on character likeness; potential lip-sync limitations.
- NLE integration for shot planning (sector: post-production software)
- Use case: Auto-generate shot breakdowns, camera specs, and timings from transcripts and import them directly into Premiere, DaVinci, or Final Cut.
- Workflow/product: “ScriptAgent NLE Bridge” that maps script JSON to timeline markers, bins, and camera notes; optional video previews via DirectorAgent.
- Assumptions/dependencies: Stable JSON schema; plug-in SDK access; editor adoption.
- Content creator co-pilot (sector: creator economy/media)
- Use case: Turn podcast segments or scripted skits into coherent, multi-shot shorts with consistent character styling.
- Workflow/product: Mobile/desktop tool that uses ScripterAgent for shot planning and DirectorAgent for clip stitching; CriticAgent flags pacing or narrative issues.
- Assumptions/dependencies: Creator consent for synthetic renderings; alignment with platform policies; compute/bandwidth limits.
- Film school teaching assistant (sector: education)
- Use case: Teach cinematography and shot division by generating scripts from dialogue and critiquing students’ scene plans.
- Workflow/product: Classroom platform using ScripterAgent to propose shot structures; CriticAgent provides rubric-based feedback; VSA quantifies timing alignment in student projects.
- Assumptions/dependencies: Curriculum adaptation; instructor calibration to AI rubrics; limited reliance on aesthetic scores for grading.
- Corporate e-learning video builder (sector: enterprise education)
- Use case: Convert training dialogues into multi-shot instructional videos with consistent environments and actors.
- Workflow/product: “Dialogue-to-Learning Video” toolkit with ScripterAgent for scripts and DirectorAgent for coherent segment generation; VSA used to validate timing with the narration.
- Assumptions/dependencies: Compliance with corporate content policies; voice rights; QA for factual accuracy.
- Localization timing and QA (sector: media localization/policy)
- Use case: Validate that localized voice tracks stay aligned with visuals and script structure.
- Workflow/product: “VSA Auditor” to score temporal-script alignment; CriticAgent flags narrative or character consistency issues across language versions.
- Assumptions/dependencies: CLIP-based encoders tuned for multilingual prompts; robust handling of culture-specific edits.
- Studio asset continuity for brand series (sector: media/branding)
- Use case: Maintain consistent character identity, styling, and set layout across episodic synthetic content.
- Workflow/product: DirectorAgent’s frame-anchoring used to condition each episode’s first shots on the prior episode’s final frames.
- Assumptions/dependencies: Persistent asset libraries; careful prompt anchoring; residual identity drift must be monitored.
- Model selection assistant based on trade-offs (sector: software tooling)
- Use case: Choose the best video model per project objective (visual spectacle vs. strict script fidelity).
- Workflow/product: “Model Router” that scores candidate models with CriticAgent and automated metrics (including VSA), then routes tasks to HYVideo for faithfulness or Sora for aesthetics.
- Assumptions/dependencies: Consistent API access; project-level preferences; periodic re-benchmarking as models update.
- Academic benchmarking and reproducible evaluation (sector: academia)
- Use case: Evaluate new dialogue-to-video systems on structure, aesthetics, and temporal-script alignment.
- Workflow/product: Public ScriptBench usage for SFT/RL training setups; VSA integrated as a standard metric; CriticAgent prompts for reproducible scoring.
- Assumptions/dependencies: Availability of dataset/license; careful reporting of human preference modeling; compute costs for GRPO.
- Storyboarding for comics/graphic novels (sector: publishing/design)
- Use case: Convert dialogue into camera-aware panels, blocking, and emotional beats for visual narrative planning.
- Workflow/product: “Script-to-Storyboard” tool exporting shot descriptions to panel layouts; optional reference frames from DirectorAgent.
- Assumptions/dependencies: Adaptation of cinematic camera language to panel conventions; illustrator workflows.
Long-Term Applications
The following applications require further research, scaling, or development, particularly to improve lip-sync, identity persistence over long durations, controllable acting, and to address policy and infrastructure needs.
- End-to-end episodic and feature-length synthetic production (sector: media/entertainment)
- Use case: Generate entire episodes or films from dialogue drafts with consistent characters and sets.
- Workflow/product: Studio-scale “Agentic Production Suite” that chains ScripterAgent, DirectorAgent, and high-capacity video models; robust asset management; multi-pass CriticAgent reviews.
- Assumptions/dependencies: Longer temporal windows; strong lip-sync/acting control; high compute; clear IP/licensing frameworks.
- Real-time on-set co-director (sector: virtual production/film tech)
- Use case: Provide shot suggestions, blocking, and camera movements during live shoots based on evolving dialogue.
- Workflow/product: AR-enabled “Director Co-Pilot” that overlays shot plans, dynamically updates scripts as actors improvise, and ensures continuity.
- Assumptions/dependencies: Low-latency models; robust speech-to-script fusion; safety buffers for operator override.
- Interactive, conversation-driven streaming narratives (sector: media/streaming)
- Use case: Audience dialogues or choices dynamically drive shot-level video generation in real time.
- Workflow/product: “Interactive Cinematic Engine” where ScripterAgent updates shot plans and DirectorAgent stitches scenes on demand; CriticAgent ensures pacing and coherence.
- Assumptions/dependencies: Scalable generation; content moderation pipelines; real-time personalization constraints.
- Simulation training for high-stakes domains (sector: healthcare/public safety/defense)
- Use case: Convert scenario dialogues (e.g., triage, emergency response, de-escalation) into standardized multi-shot simulation videos for training.
- Workflow/product: Regulated “SimGen” platform with domain-specific SFT/RL; VSA-linked objective timelines; human evaluation for safety/accuracy.
- Assumptions/dependencies: Expert-authored reward models; strict validation and audit trails; bias and ethics oversight.
- Personalized education at scale (sector: education)
- Use case: Generate individualized micro-lectures and role-play scenes from instructor–student dialogues, aligned to learning objectives.
- Workflow/product: LMS-integrated “Dialogue-to-Lesson Video” with adaptive scripts, actor consistency, and pacing control via CriticAgent.
- Assumptions/dependencies: Student privacy; pedagogical validation; diverse cultural tuning.
- Virtual production integration (sector: media/film tech)
- Use case: Merge generative previz with LED volume workflows, translating shot plans into camera-tracking cues and environmental states.
- Workflow/product: “DirectorAgent–Stagecraft Bridge” that maps shot instructions to real-time environment renders and camera moves.
- Assumptions/dependencies: Hardware integration; standardized scene graphs; SMPTE/production standards alignment.
- Standards and certification for synthetic media alignment (sector: policy/regulation)
- Use case: Certify that generated videos adhere to scripts and timing, mitigating misleading content.
- Workflow/product: “VSA-based Compliance Suite” used by platforms and auditors; standardized reporting; watermarking hooks.
- Assumptions/dependencies: Consensus metrics; regulatory adoption; robust multilingual support.
- Creative marketplace and collaboration platform (sector: creator economy/software)
- Use case: Commission dialogue-to-video projects with transparent model choices (faithfulness vs. aesthetics), versioning, and automated critique.
- Workflow/product: “Agentic Studio” with task boards for ScripterAgent plans, DirectorAgent runs, and CriticAgent reviews; support for human editors.
- Assumptions/dependencies: Rights management; content safety; scalable compute.
- Cross-domain agentic continuity (sector: robotics/software)
- Use case: Apply frame-anchoring and shot-aware segmentation analogs to multi-step robotic or software workflows requiring state continuity.
- Workflow/product: “Continuity Orchestrator” that conditions each task segment on prior end-state representations to reduce drift.
- Assumptions/dependencies: Domain-specific state encoders; safe RL; benchmarking beyond video.
- High-fidelity acting control and lip-sync (sector: media/AI research)
- Use case: Precisely control micro-expressions, gestures, and speech alignment across long scenes.
- Workflow/product: GRPO extensions with richer human preference models; multimodal alignment losses tied to audio prosody; actor-specific tuning.
- Assumptions/dependencies: Larger curated datasets; new reward models; improved generative backbones.
- Legal and IP workflows for synthetic series production (sector: legal/media operations)
- Use case: Manage licenses, disclosures, and asset reuse for serialized synthetic characters and sets.
- Workflow/product: “Synthetic IP Ops” toolkit that tags scripts, anchors, and renders with provenance; integrates policy metadata.
- Assumptions/dependencies: Industry guidelines; provenance tooling; platform cooperation.
Glossary
- Agentic framework: A multi-agent system design where autonomous components coordinate to accomplish a complex task. "we introduce a novel, end-to-end agentic framework for dialogue-to-cinematic-video generation."
- BERT-based regression model: A model using BERT to predict continuous-valued scores, such as human preference ratings. "we trained a BERT-based regression model to predict a normalized preference score in [0, 1]"
- Blocking: The precise planning of actors’ positions and movements within a scene. "exact character positioning or ``blocking''."
- Cinematic Camera Articulation: The sophistication of camera operations (shot types, framing, movement) that support storytelling. "Cinematic Camera Articulation. Measures the sophistication of camera work, including shot types, framing transitions, and dynamic movements that support the scripted narrative."
- CLIP Score: A metric that measures global semantic alignment between text and visual content using CLIP embeddings. "including the CLIP Score~\citep{radford2021learning} for global semantic alignment"
- Cross-Scene Continuous Generation: A strategy to maintain coherence across multiple generated segments by conditioning later segments on earlier ones. "The core novelty of the DirectorAgent is a Cross-Scene Continuous Generation Strategy"
- CriticAgent: An automated evaluator that scores scripts and videos on technical and cinematic dimensions. "(3) a CriticAgent, which evaluates the generated film from both technical and cinematic perspectives."
- Depth of Field: The range of distances in a shot that appears acceptably sharp; shallow depth isolates the subject. "“Shallow Depth of Field + panoramic shot”"
- DirectorAgent: An orchestration component that executes the script into a coherent video while preserving continuity. "The DirectorAgent is designed to bridge this execution gap, acting as an automated orchestrator that transforms the generated script into a coherent, high-fidelity video sequence."
- Diffusion transformer: A generative model that combines diffusion processes with Transformer architectures for video synthesis. "a diffusion transformer model generating high-fidelity, physically plausible videos with complex scenes."
- Dialogue Completeness: A verification check ensuring all spoken lines are included or explicitly marked. "Dialogue Completeness, which ensures that all spoken content is either explicitly transcribed or marked as [No Dialogue];"
- Dramatic Tension: The build-up and modulation of suspense and emotional intensity across a scene. "the score for Dramatic Tension improves from 3.6 to 4.1"
- First-Last Frame Connection Mechanism: A continuity method that conditions a new segment on the last frame of the previous one. "the DirectorAgent employs a First-Last Frame Connection Mechanism."
- Frame-Anchoring Mechanism: A technique that uses the final frame of one scene to visually condition the first frame of the next. "Illustration of the Frame-Anchoring Mechanism."
- Group Relative Policy Optimization (GRPO): A preference-alignment RL algorithm that optimizes policies using group-wise relative advantages. "We employ Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath}"
- Hybrid reward function: A composite reward combining rule-based structural checks with learned human-preference scores. "A key novelty of our RL stage is a hybrid reward function"
- Identity drift: The unintended change of a character’s identity/appearance across generated segments. "reduces the identity drift and jarring scene changes that plague naive segmentation approaches."
- KL-divergence penalty: A regularization term in RL that constrains the learned policy from deviating too far from a reference policy. "constrained by a KL-divergence penalty to prevent large deviations from the SFT initialization:"
- Long-horizon coherence: The maintenance of consistent narrative and visual elements over extended durations. "to produce long-horizon, coherent videos"
- Multimodal attention sink mechanism: An attention design to stabilize long multimodal generation beyond training sequence lengths. "utilizing a multimodal attention sink mechanism to maintain consistency and enable generation beyond training sequence lengths."
- Narrative Coherence: The logical flow and connectedness of the visual storytelling relative to the dialogue. "Narrative Coherence. Determines whether the sequence of shots is logically connected and if the visual storytelling flows smoothly to complement the dialogue's context."
- Physical Rationality: The plausibility of spatial relations and camera geometry in the staging of scenes. "Positional and Physical Rationality, which verifies spatial relations against plausible blocking and camera geometry."
- Preference alignment: Aligning model outputs with human preferences, often via RL or learned reward models. "an advanced preference alignment method whose group-based relative scoring is well-suited for creative tasks"
- Script Faithfulness: The degree to which a generated video adheres to the specified script content and structure. "boosting metrics like Script Faithfulness by up to +0.4 points."
- ScriptBench: A large-scale benchmark dataset for dialogue-to-cinematic-script generation with rich multimodal context. "we introduce ScriptBench, a new large-scale benchmark with rich multimodal context"
- ScripterAgent: The agent that transforms coarse dialogue into a fine-grained, executable cinematic script. "Central to our framework is ScripterAgent, a model trained to translate coarse dialogue into a fine-grained, executable cinematic script."
- Shot division rationality: The appropriateness of shot boundaries relative to narrative beats and emotional shifts. "Shot Division Rationality. Evaluates the logical segmentation of the script into shots, ensuring that breaks align with narrative beats and emotional shifts"
- Shot Integrity: The principle of keeping shots as self-contained units without cutting mid-take. "Shot integrity enforces self-contained units, introducing cuts only upon clear camera or scene changes."
- Shot-Level Semantic Planning: The process of planning shots under semantic and technical constraints to ensure continuity. "Stage 2: Shot-Level Semantic Planning."
- Supervised fine-tuning (SFT): Adapting a pre-trained model to a task using labeled examples. "We employ a two-stage training paradigm: supervised fine-tuning (SFT) to learn the script's structure"
- Temporal fidelity: The correctness of event timing in the video relative to script-defined intervals. "To quantify temporal fidelity, we introduce a novel metric, Visual-Script Alignment (VSA)"
- Trimodal context: An input setting involving three modalities, here dialogue, audio, and character positions. "a rich, trimodal context (dialogue, audio, and character positions)"
- U-ViT: A ViT-based architecture variant employed for video generation tasks. "A U-ViT-based model excelling in temporal consistency and generation speed."
- VBench: A suite of standardized metrics for evaluating video generation quality. "and a subset metrics (e.g., subject and background consistency, motion smoothness) of VBench~\citep{huang2024vbench}."
- Visual Descriptive Fidelity: The degree to which visual details match the script’s descriptive cues. "Visual Descriptive Fidelity. Evaluates how well the visual details (e.g., character appearance, clothing textures, scene layout, lighting) match the descriptive cues in the script."
- Visual-Script Alignment (VSA): A metric assessing temporal-semantic alignment between scripted instructions and generated visuals. "Visual-Script Alignment (VSA), a novel metric designed to evaluate temporal-semantic fidelity."
Collections
Sign up for free to add this paper to one or more collections.