When "Likers'' Go Private: Engagement With Reputationally Risky Content on X
Abstract: In June 2024, X/Twitter changed likes' visibility from public to private, offering a rare, platform-level opportunity to study how the visibility of engagement signals affects users' behavior. Here, we investigate whether hiding liker identities increases the number of likes received by high-reputational-risk content, content for which public endorsement may carry high social or reputational costs due to its topic (e.g., politics) or the account context in which it appears (e.g., partisan accounts). To this end, we conduct two complementary studies: 1) a Difference-in-Differences analysis of engagement with 154,122 posts by 1068 accounts before and after the policy change. 2) a within-subject survey experiment with 203 X users on participants' self-reported willingness to like different kinds of content. We find no detectable platform-level increase in likes for high-reputational-risk content (Study 1). This finding is robust for both between-group comparison of high- versus low-reputational-risk accounts and within-group comparison across engagement types (i.e., likes vs. reposts). Additionally, while participants in the survey experiment report modest increases in willingness to like high-reputational-risk content under private versus public visibility, these increases do not lead to significant changes in the group-level average likelihood of liking posts (Study 2). Taken together, our results suggest that hiding likes produces a limited behavioral response at the platform level. This may be caused by a gap between user intention and behavior, or by engagement driven by a narrow set of high-usage or automated accounts.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
In June 2024, X (formerly Twitter) made a big change: your “likes” became private to everyone except you and the post’s author. The paper asks a simple question: If people can like posts without others seeing, will they like more “risky” posts—like political or adult-content posts—that might hurt their reputation if others knew?
The main questions the researchers asked
They focused on three clear questions:
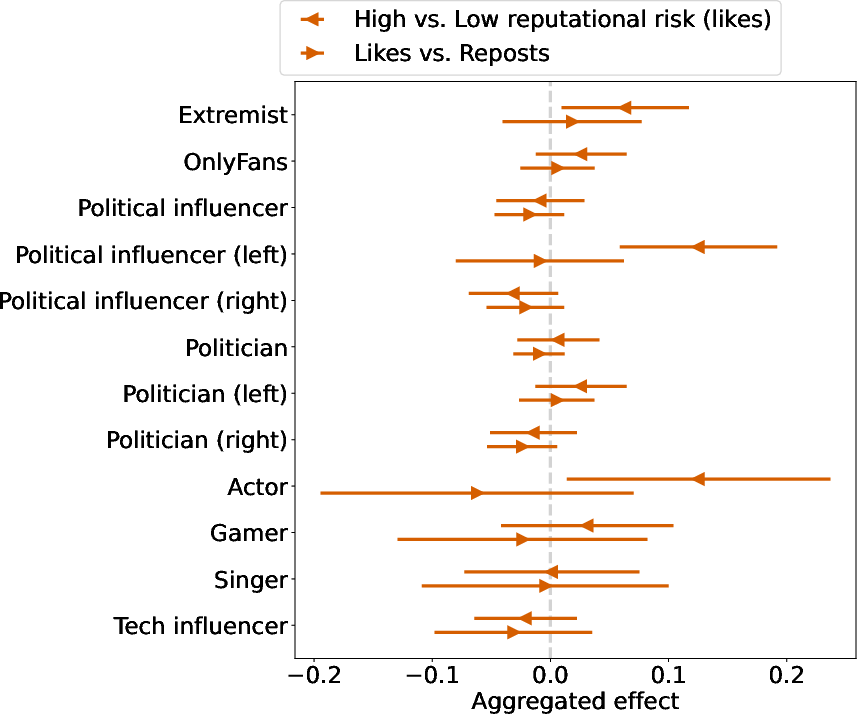
- Did hiding who liked a post make people give more likes to “reputationally risky” accounts (like partisan politicians, political influencers, OnlyFans creators, or extremist-labelled figures) compared to “low-risk” accounts (like actors, singers, gamers, tech influencers)?
- For those risky accounts, did likes increase compared to a different kind of engagement (reposts/shares) that didn’t change?
- Do people say they would be more likely to like controversial posts if their likes are private?
How they studied it (without the jargon)
They ran two studies:
- Study 1: Watching real behavior on the platform
- They collected 154,122 posts from 1,068 accounts.
- They looked at 8 weeks before and 4 weeks after likes became private.
- They compared:
- High-risk vs. low-risk accounts (to see if the change helped the risky ones more).
- Likes vs. reposts on the same high-risk accounts (reposts didn’t change in visibility, so they act like a “yardstick” to check if any increase in likes is special).
- Think of it like this: You have two groups (risky and not risky). If a rule changes, you see how each group’s likes changed before and after. If the risky group jumps up more, the rule likely had an effect. This “before-and-after with a comparison group” is called Difference-in-Differences, but you can think of it as a fair race comparison: both groups run before and after a rule change; you check if one group sped up more than the other.
- Study 2: Asking people what they would do
- They surveyed 203 active X users in the U.S.
- Each person saw topics that were either controversial (like abortion, immigration, gun control, transgender rights, BLM) or not controversial (like art, charities fighting hunger, pop culture).
- For each topic, they rated how likely they’d be to like a post if likes were public vs. private.
- Because the same person answered under both conditions, this is called a “within-subject” design—like asking you twice in two different scenarios to see if you change your mind.
They also ran extra checks to make sure results weren’t caused by random blips or small timing issues (think: double-checking your math and using backup methods to confirm the answer).
What they found (and why it matters)
- Platform behavior didn’t really change:
- After likes became private, there was no clear platform-wide increase in likes for high-risk accounts compared to low-risk accounts.
- For high-risk accounts, likes did not increase compared to reposts either.
- Put simply: making likes private didn’t move the needle in a noticeable way across the platform.
- What people said vs. what people did:
- In the survey, people said they were a little more willing to like controversial posts when likes were private.
- But on average, this small bump in willingness wasn’t big enough to change overall liking much.
- For non-controversial topics (like art or charities), privacy didn’t make much difference.
- Why might this be?
- Intention–behavior gap: People may say they’ll do something but not actually do it. It’s like promising to study more next week and then… not really doing it.
- Engagement might be dominated by a small number of super-active or automated accounts (bots). If most likes come from a small group that doesn’t change its behavior, the overall numbers won’t shift much even if many regular users slightly change their habits.
What this could mean going forward
- Hiding who liked a post may not be enough by itself to change what people engage with on a large platform.
- If a platform wants to change engagement with sensitive or controversial content, it may need more than just privacy tweaks—maybe changes to how posts are shown, when feedback appears, or who sees what.
- Even though privacy reduces social pressure, algorithms still use engagement (like likes) behind the scenes. If only a small set of heavy users or bots drives most engagement, design changes that target ordinary users’ reputational worries won’t have a big effect.
- For researchers and designers: it’s important to test both what people say they’ll do and what they actually do. The two don’t always match.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
Data and measurement gaps
- The “reputational risk” construct is operationalized at the account level (e.g., politicians, OnlyFans), not at the post level; future work should label each post’s topic, controversy/moralization, and tone to avoid diluting effects with benign posts from “high-risk” accounts and controversial posts from “low-risk” accounts.
- Exposure/impressions and feed placement are not measured; without reach data, it is unclear whether private likes changed distribution even if counts did not. Incorporate view counts or panel telemetry to track visibility dynamics.
- The composition of likers (human vs. bot, heavy vs. typical users) is unknown; apply bot detection, usage intensity stratification, and account-age/activity features to test heterogeneous treatment effects.
- Lack of identity-level liker data prevents detecting whether privatization shifted engagement to previously hesitant segments; explore author-side collaborations (authors can see likers) or privacy-preserving aggregation to infer composition shifts post-change.
- Only likes and reposts are analyzed; replies, quote tweets, bookmarks, follows, and clicks may substitute or complement likes under privatization. Measure cross-channel substitution patterns.
- No assessment of posting behavior (e.g., authors’ frequency, topic mix, sentiment) in response to private likes; analyze whether authors change content strategy when endorsements are less publicly traceable.
- The four-week post-change window is short; extend to multi-month horizons to capture lagged awareness, habit formation, and algorithmic re-tuning, while controlling for seasonality and event shocks.
- Concurrent platform changes or exogenous news cycles are not ruled out; compile and control for contemporaneous feature rollouts and major events that could confound engagement trends.
Methods and analysis limitations
- Parallel trends may be fragile for both DiD designs; bolster with alternative identification (e.g., synthetic controls, event-study with richer pre-trends, hierarchical models capturing account-level heterogeneity and random slopes).
- The equivalence bounds used for TOST (±0.01) are chosen ad hoc; pre-register practically meaningful thresholds informed by power analyses and stakeholder-relevant minimal detectable effects.
- The likes-vs-reposts comparison assumes reposts are unaffected; verify stability of repost norms, quote-tweet usage, and any policy changes influencing sharing behavior during the study period.
- Heterogeneity analysis is coarse at category level; conduct fine-grained moderation by author ideology, audience size, follower growth, post media type, and time-of-day to detect pockets of impact masked at aggregate level.
- Use post-level content features (e.g., topic classification, moral-emotional language, toxicity/hate-speech scores) to test whether privatization affects specific content attributes rather than account categories.
Scope and generalizability constraints
- The account sample skews toward high-follower, U.S.-centric elites; include ordinary users, small accounts, and non-U.S. contexts to assess broader normative pressures and reputational calculus.
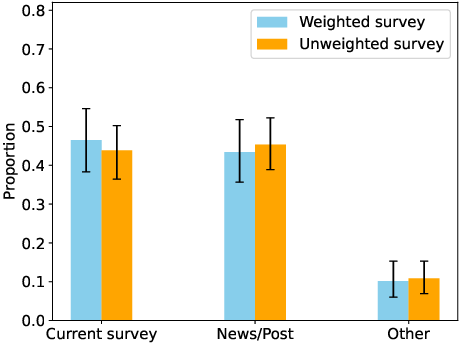
- The survey sample (N=203, U.S.-only) limits cultural generalizability; replicate with larger, cross-national samples and platform-verified X users matched on usage intensity.
- Findings are X-specific; test whether similar privacy changes on other platforms (e.g., Instagram, TikTok) produce different dynamics given distinct social proof conventions and ranking systems.
Mechanisms left untested
- The intention–behavior gap is inferred rather than causally tested; run pre-registered experiments with real in-app actions (e.g., browser extensions, lab-in-the-field designs) and measure mediators (perceived reputational risk, norm sensitivity, privacy understanding).
- Awareness and comprehension of the policy (especially that authors still see likers) are coarse; measure nuanced understanding and test whether misconceptions moderate the effect.
- The social proof channel via like counts remains public; isolate whether identity privacy vs. count visibility differentially affects engagement by experimentally manipulating visibility of counts and identities.
- Potential fear of author retaliation or targeted harassment persists because authors still see likers; measure whether this residual visibility blunts the reputational relief privatization aims to provide.
Algorithmic distribution and downstream effects
- Whether private likes alter ranking weights, content amplification, or network diffusion is not examined; audit feed outcomes (e.g., exposure lift, dwell time) using observational models or controlled experiments with platform collaboration.
- Explore whether privatization disproportionately amplifies fringe/extremist content within niche clusters despite null average effects; conduct community-level and network-structural analyses (e.g., modularity, echo chambers, supersharers).
- Assess downstream civic outcomes (e.g., misinformation spread, polarization proxies) to determine whether small engagement shifts translate into meaningful societal impacts.
Open questions for future research
- Do private likes increase engagement among specific subpopulations (e.g., politically moderate users, privacy-sensitive users, protected accounts) even if platform-wide averages are unchanged?
- Are effects larger for posts with high moralization/controversy, low baseline engagement, or ambiguous reputational signals than for routine political or adult content?
- Do users substitute toward bookmarks, private sharing (DMs), or quote tweets when liker identities are hidden, and how do these shifts affect algorithmic visibility?
- Does privatization change authors’ behavior (e.g., posting more controversial content, soliciting likes differently, targeting niche audiences) over longer horizons?
- Under what combined design interventions (e.g., audience segmentation, delayed feedback, altered count visibility) does reducing reputational pressure translate into measurable behavioral change?
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, organized by sector and grounded in the paper’s findings and methods.
- Social platforms (Product, Data Science): Visibility-change impact audit
- Application: Stand up a rolling Difference-in-Differences (DiD) monitoring program to quantify the behavioral effects of visibility interventions (e.g., private likes) on predefined “risk” segments.
- Tools/Workflows: Between-group DiD (high vs. low reputational risk), within-engagement DiD (likes vs. reposts), negative binomial models, fixed effects, HonestDiD and equivalence testing.
- Assumptions/Dependencies: Access to high-quality event logs or APIs; reasonably parallel pre-trends; stable algorithmic weights; reliable risk-category labeling.
- Trust & Safety and Moderation teams (Industry): “Bundle-then-ship” intervention playbooks
- Application: Treat hiding liker identities as insufficient on its own; pair visibility changes with distribution levers (downranking, timing tweaks, audience segmentation, warning labels).
- Tools/Workflows: Intervention orchestration playbooks; A/B test harness; category-specific moderation templates.
- Assumptions/Dependencies: Capacity to alter ranking inputs; accurate topic/model classification; monitoring to avoid collateral suppression.
- Ranking/Recommendation engineering (Software): Decoupled-signal sanity checks
- Application: Audit whether private likes (still strong algorithmic signals) produce unintended amplification of controversial content despite the lack of social proof.
- Tools/Workflows: Offline simulations; guardrail metrics; counterfactual evaluation using within-engagement DiD (likes vs. reposts).
- Assumptions/Dependencies: Clear documentation of signal weights; robust bot/supersharer filtering; stable feed logic.
- Integrity teams (Industry): Heavy-user and automated engagement audits
- Application: Quantify engagement concentration (supersharers/bots) and dampen their outsized influence on ranking and perceived popularity.
- Tools/Workflows: Supersharer detection, bot classifiers, dynamic quotas, engagement-weight rebalancing.
- Assumptions/Dependencies: High-precision detection to minimize false positives; privacy compliance; transparent escalation policies.
- Marketing and brand strategy (Advertising/Media): Campaign risk planning for sensitive topics
- Application: Adjust expectations and KPIs—private likes alone are unlikely to raise visible engagement on reputationally risky content; emphasize reposts/comments or community-building instead.
- Tools/Workflows: Creative testing across engagement types; social listening by topic; sentiment-risk scoring.
- Assumptions/Dependencies: Audience composition comparable to study context; platform algorithms unchanged.
- Academic researchers (Academia): Robust impact-evaluation templates
- Application: Reuse the paper’s dual DiD designs and survey experiment structure to evaluate other platform policy changes (e.g., comments visibility, reply throttling).
- Tools/Workflows: Open notebooks for DiD/HonestDiD/equivalence tests; stratified sampling with raking; within-subject survey vignettes.
- Assumptions/Dependencies: Data access; IRB/ethics approvals; adequate pre-change observation windows.
- Regulators and policy analysts (Policy): Evidence-based transparency checklists
- Application: Require platforms to publish pre/post impact reports showing null or non-null effects of visibility changes on controversial content engagement.
- Tools/Workflows: Standardized reporting templates; third-party audit protocols.
- Assumptions/Dependencies: Legal authority for transparency mandates; data sharing frameworks.
- Newsrooms and fact-checkers (Media/Civil society): Claims verification and audience guidance
- Application: Use the paper’s null platform-level effect to temper public claims about the behavioral impact of private likes.
- Tools/Workflows: Rapid-response explainer pieces; methodology primers for DiD and survey interpretation.
- Assumptions/Dependencies: Access to platform statements; willingness to publish nuanced null results.
- UX Research (Software/Product): Intention–behavior gap probes in design testing
- Application: Incorporate within-subject vignettes (public vs. private modes) to detect when stated willingness won’t translate to measurable behavior.
- Tools/Workflows: Paired-condition surveys; in-product experiments; friction and timing manipulations.
- Assumptions/Dependencies: Participant representativeness; careful interpretation of small within-person effects.
- Digital literacy programs (Education/Daily life): User-facing guidance on private likes
- Application: Inform users that private likes are still visible to authors and may not change reach or algorithmic exposure; recommend bookmarks or notes for genuinely private curation.
- Tools/Workflows: Tip sheets; microlearning modules; platform FAQs.
- Assumptions/Dependencies: Current product behavior persists; clear communication from platforms.
Long-Term Applications
The following use cases require further research, scaling, and/or product development to realize their potential.
- Contextual visibility controls (Social platforms/Product)
- Application: Per-topic or per-audience toggles for engagement visibility (e.g., private likes for political topics), coupled with distribution adjustments to prevent unintended amplification.
- Tools/Workflows: Audience segmentation engines; topic-sensitive privacy policies; real-time classification.
- Assumptions/Dependencies: Accurate topic detection; consentful UX; regulatory compliance.
- Private-signal reweighting in ranking (Software/AI)
- Application: Recalibrate algorithmic weights for likes/reposts under private modes to mitigate concentration from supersharers or automated accounts.
- Tools/Workflows: Causal inference in production; counterfactual pipelines; safety guardrails.
- Assumptions/Dependencies: Reliable detection of automated/high-usage accounts; measurable business impacts.
- Multi-lever moderation bundles (Trust & Safety/Policy)
- Application: Combine visibility changes with warning labels, feedback timing, audience notes, and distribution nudges for sensitive content.
- Tools/Workflows: Orchestration platforms integrating policy rules and experimental results; staged rollout frameworks.
- Assumptions/Dependencies: Interoperable moderation tools; careful measurement to avoid chilling legitimate speech.
- Standardized platform-change evaluation (Industry–Academia collaboration)
- Application: Create an open methodology and library for analyzing platform interventions using DiD variants, HonestDiD, and equivalence testing.
- Tools/Workflows: Open-source packages; shared benchmark datasets; reproducibility protocols.
- Assumptions/Dependencies: Cross-platform data access; governance for researcher–platform collaboration.
- Regulatory audit mandates (Policy/Governance)
- Application: Require periodic audits of engagement concentration, bot activity, and intervention efficacy following major design changes.
- Tools/Workflows: Compliance workflows; independent auditors; public summary reports.
- Assumptions/Dependencies: Enforceable regulations; privacy-preserving aggregation.
- Intention-to-action mechanisms (Behavioral science/Product)
- Application: Design and test features that bridge the intention–behavior gap (e.g., commitment prompts, timed reminders, friction changes tailored to sensitive topics).
- Tools/Workflows: Behavioral experimentation platforms; multi-arm bandits; ethics review pipelines.
- Assumptions/Dependencies: User trust; non-coercive designs; robust measurement of downstream effects.
- Supersharer dampening systems (Integrity/Ranking)
- Application: Detect and rate-limit the influence of high-usage or automated accounts on engagement signals to reduce skewed exposure.
- Tools/Workflows: Dynamic quotas; influence caps; anomaly detection.
- Assumptions/Dependencies: High-fidelity identification; safeguards against suppressing legitimate high-volume voices.
- Audience awareness tracking (Product/Research)
- Application: Continuously measure user awareness of major policy changes and its relationship to behavior (short- vs. long-term).
- Tools/Workflows: In-app surveys; passive telemetry; cohort-based analyses.
- Assumptions/Dependencies: Representative sampling; respectful telemetry practices.
- Reputation-safe engagement modes (Wellbeing/Education)
- Application: Offer “quiet engagement” features (private bookmarks, collections, or delayed likes) to let users explore sensitive content without boosting reach.
- Tools/Workflows: Privacy-by-default curation tools; engagement throttling; audience-specific defaults.
- Assumptions/Dependencies: Adoption incentives; clarity on what remains visible to authors.
- Sensitive-topic communication playbooks (NGOs/Politics/Civil society)
- Application: For organizations operating in polarizing domains, shift tactics from relying on likes to deeper interaction (community events, DMs, newsletters), knowing private likes won’t move platform-level engagement.
- Tools/Workflows: Grassroots mobilization toolkits; omnichannel outreach; sentiment and risk analytics.
- Assumptions/Dependencies: Platform policies remain similar; audience segmentation data is available.
Glossary
- Affordances: Design possibilities that a platform’s features provide or signal to users, shaping how they can act. Example: "Social media affordances refer to the perceived, actual, and imagined properties of platforms"
- Algorithmic layer: The part of a platform where algorithms use engagement signals to rank and recommend content. Example: "Beyond social dynamics, like visibility also matters for the platformâs algorithmic layer."
- Audience segmentation: Deliberate targeting or differentiation of user audiences to tailor exposure or effects. Example: "visibility changes that target reputational risk may require complementary levers (e., distribution, feedback timing, or audience segmentation)"
- Bandwagon dynamics: Social processes where visible popularity encourages more people to engage, reinforcing the trend. Example: "visible engagement metrics amplify bandwagon dynamics and moralized responses"
- Between-group comparison: An analysis comparing outcomes across distinct groups to infer differential effects. Example: "between-group comparison of high- versus low-reputational-risk accounts"
- Conditional Least Favorable Hybrid (C-LF): A robust inference method in HonestDiD that bounds violations of parallel trends. Example: "Specifically, we implement the Conditional Least Favorable Hybrid (C-LF) method,"
- Control group: The group not expected to be affected (or less affected) by a treatment, used as a baseline for comparison. Example: "Low-reputational-risk accounts, for which engagement is less socially costly, serve as the control group."
- Deplatforming: Removing users or groups from a platform to limit their access and influence. Example: "the editing or removal of posts and the deplatforming of user accounts"
- Difference-in-Differences (DiD): A causal inference method comparing pre/post changes across treated and control groups to estimate treatment effects. Example: "We employ Difference-in-Differences (DiD) to estimate the effect of private likes"
- Downranking: Algorithmically reducing a post’s ranking to limit its visibility without removing it. Example: "downranking, and visibility reduction directly targets the visibility affordance"
- Equivalence bounds: Predefined thresholds used to assess whether an effect is practically negligible. Example: "The grey dash lines in (c) and (d) represent equivalence bounds."
- Equivalence test: A statistical test to determine if an observed effect is small enough to be considered practically zero. Example: "conduct an equivalence test to determine whether the nonâstatistically significant effects can be dismissed as practically null,"
- Fixed effects: Model terms that control for unobserved, time-invariant characteristics of entities or time periods. Example: "post-specific and week-specific fixed effects are included"
- Full-archive search endpoint: An API feature that allows querying all historical posts for specified accounts or terms. Example: "X Pro API's full-archive search endpoint"
- HonestDiD: A framework for robust DiD inference that allows bounded deviations from parallel trends. Example: "HonestDiD provides a framework for robust inference in DiD settings where the strict parallel trends assumption may not fully hold"
- Intention–behavior gap: The observed disconnect where stated intentions do not fully translate into actual behavior. Example: "consistent with an intentionâbehavior gap"
- Iterative proportional fitting (raking): A reweighting technique to adjust sample distributions to match known population margins. Example: "we subsequently apply iterative proportional fitting (raking)"
- Leads-and-lags: Event-time specification estimating effects in periods before (leads) and after (lags) a treatment to assess dynamics and pre-trends. Example: "with both weekly leads-and-lags and aggregated pre-post specifications."
- Negative binomial regression: A count-data regression model accommodating overdispersion relative to Poisson. Example: "we estimate our models using negative binomial regression."
- Normative social influence: Pressure to conform to social norms or expectations that can shape visible engagement. Example: "more susceptible to normative social influence"
- Parallel trends assumption: The key DiD assumption that treated and control groups would have followed similar trends absent the treatment. Example: "The parallel trends is a key assumption for DiD identification"
- Pre-trends: Differences in outcome trends between groups before a treatment, used to assess DiD validity. Example: "probe pre-trends and inference robustness with HonestDiD and equivalence test."
- Quasi-experiment: An observational study leveraging exogenous changes that approximate random assignment. Example: "we use X's policy change as a quasi-experiment"
- Reputational risk: Potential social or professional cost from publicly endorsing or engaging with certain content. Example: "high-reputational-risk content"
- Self-censorship: Deliberately withholding or altering expression to avoid negative consequences. Example: "leading to self-censorship"
- Stratified sampling: Sampling method that partitions the population into strata and samples within each to improve representativeness. Example: "we employ a stratified sampling procedure"
- Treatment group: The group expected to be affected by the intervention in a causal analysis. Example: "making them our treatment group."
- Visibility affordance: The aspect of platform design that determines how observable information and actions are to others. Example: "represents a significant reconfiguration of the visibility affordance"
- Visibility interventions: Design changes that alter how content or engagement is displayed to influence behavior. Example: "Design implications for visibility interventions:"
- Within-subject design: An experimental setup where each participant experiences multiple conditions for comparison. Example: "a within-subject survey experiment"
- X Pro API: The professional API for X (formerly Twitter) enabling programmatic access to platform data. Example: "We use the X Pro API's full-archive search endpoint"
Collections
Sign up for free to add this paper to one or more collections.