End-to-End Test-Time Training for Long Context
Abstract: We formulate long-context language modeling as a problem in continual learning rather than architecture design. Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention. However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights. In addition, we improve the model's initialization for learning at test time via meta-learning at training time. Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms. We conduct extensive experiments with a focus on scaling properties. In particular, for 3B models trained with 164B tokens, our method (TTT-E2E) scales with context length in the same way as Transformer with full attention, while others, such as Mamba 2 and Gated DeltaNet, do not. However, similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it 2.7 times faster than full attention for 128K context. Our code is publicly available.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper tries to make LLMs better at understanding very long texts without slowing down. Instead of building a brand-new type of model, the authors use a regular Transformer with a “sliding window” that looks only at recent words. Their key idea is to let the model keep learning during test time (when it’s reading your input), so it can “compress” what it sees into its own memory and use that to make better predictions. They also train the model in a special way so it’s good at this test-time learning.
Goals and questions the paper asks
The paper focuses on simple, practical questions:
- Can a LLM use very long context well without getting much slower as the text gets longer?
- Can we help the model “learn on the fly” from the exact text it’s reading, instead of only relying on past training?
- Can we make this learning process “end-to-end,” meaning it directly improves the final prediction we care about?
- How does this approach compare to popular long-context methods in both accuracy and speed as context gets longer?
How the method works (explained simply)
Think of reading a huge textbook. You probably won’t remember every detail, but you do keep helpful ideas in your mind as you go.
That’s the main trick here: the model keeps learning while it reads.
- Sliding window attention: The model looks back over a fixed-sized “window” of recent words (like the last few pages you just read), which keeps things fast. Unlike full attention that scans everything from the start, sliding windows are much cheaper.
- Test-Time Training (TTT): As the model reads your long input, it repeatedly practices predicting the next word and uses its mistakes to slightly adjust itself. This “on the fly” practice helps it compress what it has read into its internal weights, so it doesn’t need to keep re-reading the entire text.
- Meta-learning: During normal training (before deployment), the model is trained to become good at this test-time learning. It’s like practicing how to take great notes while reading, so that later, during a real test, the model learns quickly and safely.
- Practical tweaks for stability and speed:
- Mini-batches: Instead of updating on every single word (which can be unstable), the model updates after small groups of words. This keeps learning smooth and fast.
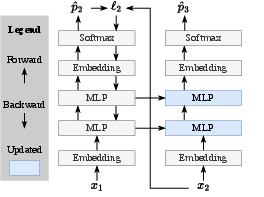
- Only update part of the network: During test-time learning, the model only updates certain layers (specifically, some of the MLP layers in the last quarter of the network). This reduces the risk of “forgetting” and saves compute.
- Add a “safe” MLP: A second, fixed MLP is added in those updated blocks to keep important pre-trained knowledge intact.
In short: the model reads, practices predicting the next word as it goes, and slightly adjusts itself using the exact text you give it—just enough to remember what matters, without getting slow.
Main findings and why they matter
Here are the key results, tested on medium-sized models (around 3 billion parameters) trained on a large amount of text (about 164 billion tokens):
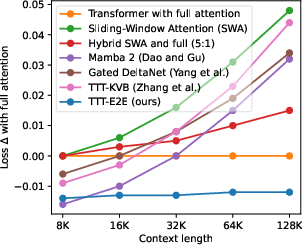
- Keeps accuracy strong as context grows: The proposed method (TTT-E2E) improves with longer inputs in a way similar to full attention (the gold standard for accuracy), while other fast long-context methods (like Mamba 2 and Gated DeltaNet) don’t scale as well in accuracy as the context gets very long.
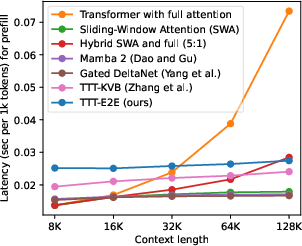
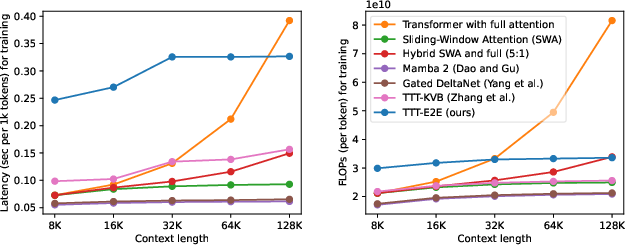
- Constant speed with long inputs: TTT-E2E runs at about the same speed no matter how long the input is, similar to RNNs. At 128,000 tokens of context, it’s roughly 2.7× faster than full attention on the tested hardware (H100 GPU).
- Works end-to-end: Because the model learns using the same “next-word prediction” objective you ultimately care about, improvements directly translate to better final predictions.
- Careful design choices matter:
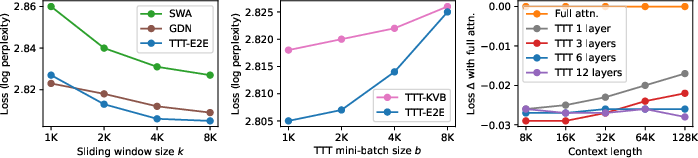
- A window size around 8,000 tokens worked well in tests.
- Updating mini-batches of about 1,000 tokens balanced stability and speed.
- Updating the last quarter of layers gave the best trade-off between speed and memory.
- Surprisingly, this test-time learning even helped when using full attention at short context, meaning it’s an orthogonal boost, not just a workaround for limited attention.
- Scales with training compute like full attention: When you train with enough data and model size, this approach follows the same “more compute → better results” trend as full attention. That suggests it will behave well in large production training runs.
Why this matters: Full attention is accurate but gets slow as context grows. Pure RNN-style approaches are fast but often lose accuracy on long contexts. This method gives you the best of both worlds: accuracy that scales with context plus speed that stays flat.
What this could mean going forward
- Faster long-context assistants: Systems that need to read long documents, codebases, chats, or books can stay fast while still using the entire context effectively.
- Lower costs: Constant-time inference at long context means fewer compute resources and shorter waiting times.
- Practical path, not a radical redesign: It uses standard Transformers with a sliding window and adds smart test-time learning, so it’s easier to adopt than building entirely new architectures.
- New research directions: The results hint that teaching models to learn at test time—possibly using self-generated summaries or reviews—could further improve stability and quality in messy real-world data.
In short: Letting models keep learning as they read makes long-context understanding both accurate and fast, opening the door to more practical, powerful AI systems that can handle huge inputs without slowing down.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces TTT-E2E for long-context language modeling and presents promising results, but several aspects remain missing or insufficiently explored. Future work could address the following gaps:
- Quantify training-time overhead of E2E meta-learning (outer-loop gradients of gradients), including memory footprint, wall-clock time, and scalability beyond 3B (e.g., 7B–70B+), compared to standard pretraining and to TTT-KVB-style methods.
- Provide a rigorous stability analysis of inner-loop TTT updates (e.g., gradient explosion, sensitivity to single-token noise), including the role of gradient clipping, learning-rate schedules, and optimizer choice (the inner loop currently uses simple GD; momentum/Adam were not explored).
- Evaluate catastrophic forgetting and knowledge drift induced by test-time updates, especially on downstream tasks (QA, summarization, long-range reasoning) and across domains (code, multilingual), not just next-token loss.
- Assess safety/alignment robustness: can adversarial or toxic contexts hijack inner-loop updates to degrade safety policies or factuality? What mitigation (e.g., guards, regularization, gating, frozen safety heads) is needed?
- Investigate the impact of test-time training on generation quality when training on self-generated tokens (proposed as future direction): measure drift, hallucination, and compounding error rates; compare filtered/rephrased tokens vs raw generations.
- Clarify reset policies and persistence: when and how are updated weights reset between documents/sessions? What are the trade-offs between persistence (carry-over memory) vs fresh initialization (avoiding interference)?
- Provide comprehensive latency and memory breakdowns for prefill and decode phases under TTT-E2E, including backward-pass memory costs, optimizer state (if any), and throughput across hardware (A100, H100, TPU) and multi-GPU settings.
- Extend window-size ablations (k) beyond the 8K pretraining regime to longer contexts (32K, 64K, 128K) and different model sizes; derive guidelines for choosing k and mini-batch size b at 256K–1M contexts.
- Benchmark long-context task performance beyond language modeling loss (e.g., book-level QA, long-document retrieval, Needle-in-a-Haystack, passkey retrieval, code repositories) to test non-local recall vs compression trade-offs.
- Quantify exact-recall vs compression trade-offs: under what conditions does TTT-E2E fail to retrieve precise details (e.g., exact quotations) compared to full attention? Can hybrid schemes selectively retain exact spans?
- Systematically study which layers to update at test time: the paper freezes attention/norms and updates MLPs in the last 1/4 of blocks; evaluate alternatives (earlier blocks, attention layers, norms, adapters) across model sizes and tasks.
- Explore parameter-efficient inner-loop updates (e.g., LoRA/IA3/adapters) for large models to reduce memory/compute while preserving context scaling; compare to full MLP updates used here.
- Analyze the effect of multi-head vs single-head MLP designs during TTT-E2E (the paper reverts to regular MLPs for larger state): can structured subspaces or low-rank constraints improve efficiency without hurting scaling?
- Provide theoretical characterization (e.g., convergence, stability, generalization bounds) of E2E TTT with sliding-window attention; formalize when it matches full attention’s scaling and when it diverges.
- Measure sensitivity to tokenizers and data quality in a controlled study (beyond anecdotal observations): run scaling experiments across multiple tokenizers (Llama 2/3, tiktoken) and datasets (FineWebEdu, DCLM, SlimPajama, curated books).
- Evaluate decoding-time TTT (training on generated batches) empirically: quantify net benefits vs risks, scheduling strategies (batch size, cadence), and methods to prevent degenerate updates.
- Report comprehensive fairness controls for baselines: ensure equal parameter budgets and comparable optimizations (e.g., training-time improvements applied to Mamba/Gated DeltaNet/TTT-KVB), and disclose any residual mismatches.
- Test multi-stage long-context extension recipes used in production (e.g., progressive 16K→64K→128K→1M), and analyze how TTT-E2E interacts with curriculum lengthening and data mixing strategies.
- Examine multilingual and code-specific performance and scaling, including tokenizer compatibility, subword segmentation effects, and domain-specific long-range dependencies.
- Investigate robustness to noisy or adversarial tokens within the window (k≥b): can gating, confidence weighting, or self-generated summaries mitigate harmful updates while preserving useful compression?
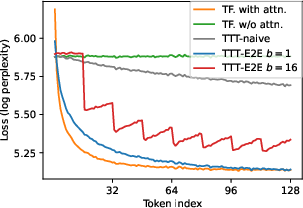
- Detail how loss improvements distribute across tokens at longer contexts (≥128K) for multiple model sizes; current token-level breakdowns are limited and suggest early-token gains dominate—understand and optimize late-token behavior.
- Study interactions with retrieval augmentation and memory modules: can TTT-E2E complement external memory/retrieval to balance compression and exact recall, and what are the best integration points?
- Provide deployment guidance: reproducibility under TTT (nondeterminism from gradient updates), caching strategies, rollback mechanisms, and monitoring for model drift during inference.
Glossary
- Ablations: Systematic experiments that vary components or hyper-parameters to assess their effect on performance. "We will justify these details with ablations in Section~\ref{sec:results}."
- Automatic differentiation: Software technique for efficiently computing derivatives of functions expressed as programs. "modern frameworks for automatic differentiation can efficiently compute gradients of gradients with minimal overhead~\cite{jax2018github, engstrom2025optimizing}."
- Beginning of Sequence (BOS): A special token that marks the start of a sequence for LLMs. "where is the Beginning of Sequence (<BOS>) token."
- Chinchilla recipe: A compute-optimal guideline relating model size and training tokens for LLMs. "our basic number of tokens for pre-training is taken from the Chinchilla recipe~\cite{hoffmann2022training}"
- Cross entropy (CE): A standard loss function measuring the difference between a predicted distribution and the true label. "The test loss is then , where CE is the cross entropy and is generated by nature."
- Deeply Supervised Nets: A training strategy that attaches auxiliary losses to intermediate layers to improve optimization. "Then there is a backward pass, with contributions from many losses in the fashion of Deeply Supervised Nets~\cite{lee2015deeply}."
- Dynamic evaluation: The practice of updating a model’s parameters at test time using observed test data to improve predictions. "This form of Test-Time Training (TTT), similar to an old idea known as dynamic evaluation~\cite{mikolov2013efficient, krause2018dynamic}, still has a missing piece:"
- End-to-End (E2E): An approach where the training objective directly matches the test objective and optimization flows from inputs to final outputs. "Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms."
- Fast weights: Rapidly updated parameters that act as short-term memory to store recent contextual information. "Our work is also inspired by the literature on fast weights~\cite{hinton1987using, schmidhuber1992learning, schlag2020learning, irie2021going}, especially \cite{clark2022meta} by Clark et al., which shares our high-level approach."
- Full attention: Standard self-attention over the entire context, with quadratic prefill cost and linear decode cost. "Self-attention over the full context, also known as full attention, must scan through the keys and values of all previous tokens for every new token."
- Gated DeltaNet: A recurrent architecture that extends linear-attention style sequence models with gating mechanisms. "RNNs such as Mamba\,2~\cite{gu2023mamba} and Gated DeltaNet~\cite{yang2024gated} have constant cost per token"
- Gradients of gradients: Higher-order derivatives required when optimizing objectives that themselves depend on gradient-based updates. "computing for the E2E entails computing gradients of gradients, since the update rule in Equation~\ref{eq:toy} itself contains a gradient operation."
- Inner loop: The fast adaptation phase (e.g., at test time) in meta-learning where parameters are updated using local data. "In the field of meta-learning, gradient steps on are called the outer loop, and on the inner loop."
- Key-Value Binding (KVB): A layer-wise TTT objective that learns to map keys to values, implicitly storing associations in fast weights. "This subsection discusses an alternative derivation of our main method, starting from prior work on long-context TTT based on Key-Value Binding (KVB)~\cite{sun2024learning, zhang2025test}."
- Linear attention: Attention mechanisms with linear complexity that approximate full attention via kernelization or related tricks. "linear attention~\cite{schmidhuber1992learning, katharopoulos2020transformers} and many of its variants, such as Gated DeltaNet~\cite{yang2024gated}, can also be derived from this perspective."
- LoRA: Low-Rank Adaptation; a parameter-efficient method that updates low-rank adapters instead of full weight matrices. "Moreover, these MLPs are updated with LoRA~\cite{hu2022lora}, so their effective capacity is even smaller."
- Mamba 2: A modern recurrent/state-space model architecture designed for efficient long-sequence processing. "RNNs such as Mamba\,2~\cite{gu2023mamba} and Gated DeltaNet~\cite{yang2024gated} have constant cost per token"
- Meta-learning: Learning procedures that optimize a model to learn effectively from new data, often by training initializations or update rules. "we improve the model's initialization for learning at test time via meta-learning at training time."
- Mini-batch gradient descent: An optimization method that updates parameters using gradients computed on small batches of data. "TTT(-KVB) layers can effectively use (inner-loop) mini-batch gradient descent when preceded by sliding-window attention layers~\cite{zhang2025test}."
- Next-token prediction: The language modeling task of predicting the next token given a sequence of prior tokens. "Consider the standard task of next-token prediction, which consists of two phases at test time:"
- Outer loop: The slower, meta-level optimization phase that adjusts initial parameters to improve inner-loop adaptation. "In the field of meta-learning, gradient steps on are called the outer loop, and on the inner loop."
- Prefill: The inference phase where the model processes the given context to set up its state before decoding new tokens. "Prefill: conditioning on given tokens , where is the Beginning of Sequence (<BOS>) token."
- Sliding-window attention (SWA): A restricted attention mechanism that attends only within a fixed-size context window to reduce complexity. "Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention."
- Test-Time Training (TTT): Updating a model’s parameters during inference using the test context to improve predictions. "This form of Test-Time Training (TTT), similar to an old idea known as dynamic evaluation~\cite{mikolov2013efficient, krause2018dynamic}, still has a missing piece:"
Practical Applications
Overview
This paper introduces TTT‑E2E: a long‑context inference method that (a) uses a standard Transformer with sliding‑window attention, (b) continues learning at test time via next‑token prediction on the given context (compressing context into fast weights), and (c) meta‑learns the initialization for robust test‑time learning. Empirically, TTT‑E2E:
- Matches full‑attention’s quality scaling with context length while maintaining constant per‑token latency (like RNNs), and is 2.7× faster than full attention at 128K tokens on an H100.
- Works with mini‑batch TTT during inference (e.g., b≈1K), updates only MLPs in the last ~1/4 blocks, and keeps a static MLP per updated block to preserve pretraining knowledge.
- Scales comparably to full attention with adequate training compute and benefits from modern tokenizers and data quality.
Below are practical applications grouped by time horizon.
Immediate Applications
These are deployable with current hardware and MLops stacks, assuming availability of a TTT‑E2E model trained per the paper’s recipe and serving adapted to allow per‑session gradient updates.
- Software and Cloud Platforms
- Long‑context LLM endpoints with lower latency/cost
- Sector: software/cloud. Offer 128K context APIs with constant latency and reduced GPU hours vs full attention.
- Tools/workflows: “TTT‑E2E Serving Layer” (JAX/PyTorch) with per‑session fast‑weight state, automatic reset after session, configurable window size k≈8K and TTT batch b≈1K.
- Assumptions/dependencies: GPU inference must permit gradient steps; session isolation and stateless teardown; hyperparameter tuning; model must be meta‑trained to support TTT.
- TTT‑augmented RAG
- Sector: enterprise search. Absorb retrieved chunks into fast weights to reduce KV cache scans and repeated retrieval costs during a session.
- Tools/workflows: “Indexless RAG (128K)” mode; per‑query memory budget; fallback to retrieval on window boundaries.
- Assumptions/dependencies: Retrieval quality remains critical; careful scheduling of TTT steps to balance throughput/latency.
- Legal
- E‑discovery and contract portfolio review
- Sector: legal. Ingest and reason over hundreds of long documents per case with lower latency; refine internal state as the session progresses.
- Tools/workflows: “Session‑adaptive reviewer” that progressively compresses facts/definitions into fast weights; live clause comparison across contracts.
- Assumptions/dependencies: Document volumes can exceed 128K tokens—requires session chunking strategy; provenance and citation checks are needed; data privacy controls.
- Finance
- Filings and transcript analysis for due diligence and research
- Sector: finance. Rapidly scan 10‑Ks/10‑Qs, earnings call transcripts, and analyst notes in one session; dynamic adaptation to issuer‑specific terminology.
- Tools/workflows: “TTT Due Diligence Assistant” with portfolio‑level session state; note‑taking and risk tagging as the model learns.
- Assumptions/dependencies: Auditability of dynamically updated state; guardrails against hallucinations; compliance logging.
- Healthcare
- Patient‑level longitudinal EHR summarization
- Sector: healthcare. Summarize years of records per patient on‑premises; adapt to facility‑specific templates and abbreviations.
- Tools/workflows: “Patient‑session adapters” with ephemeral fast weights; structured summary output (meds, labs, trends).
- Assumptions/dependencies: PHI handling, on‑prem GPU; clinical oversight; model updates must be ephemeral (no cross‑patient contamination).
- Customer Support and Contact Centers
- Long conversation/thread analysis for agent assist
- Sector: CX/BPO. Maintain consistent context across long tickets and call transcripts without rising latency.
- Tools/workflows: “Conversation memory compression” that updates fast weights each mini‑batch; suggest next actions and summarize outcomes.
- Assumptions/dependencies: Real‑time latency budgets; noise‑robust adaptation; session reset on handoff.
- Software Engineering
- Repo‑level code understanding and refactoring
- Sector: developer tools. Adapt to project conventions across large repos; maintain constant latency as more files are read.
- Tools/workflows: IDE plugin with “TTT session mode” for dependency mapping, code review, and pervasive refactors.
- Assumptions/dependencies: Repos often exceed 128K tokens—requires chunking and incremental passes; tests/CI integration for validation.
- Scientific Research and Education
- Literature review across many papers/book chapters
- Sector: academia/edtech. Summarize and cross‑reference related work; build “live” synthesis that improves through the session.
- Tools/workflows: “Long‑context literature assistant” for grant/related‑work drafting; course companion ingesting textbook and notes.
- Assumptions/dependencies: Citation fidelity; content licensing; b/k tuning for mixed‑length materials.
- DevOps/SRE/Security
- Streaming log analytics and anomaly triage
- Sector: software/security. Learn service‑specific patterns over long windows; constant latency for incident response.
- Tools/workflows: “TTT log copilot” ingesting rolling logs and incidents; suggestion of runbooks and root‑cause hypotheses.
- Assumptions/dependencies: Robustness to noisy logs; integration with SIEM/observability stacks; rollback/reset policies.
- Government and Policy
- Drafting and analysis across long bills or regulatory comment corpora
- Sector: public sector. Faster, more private on‑prem analysis of multi‑hundred‑page documents with evolving context.
- Tools/workflows: “Policy doc assistant” with secure, ephemeral adaptation per docket.
- Assumptions/dependencies: Procurement and security constraints; FOIA and audit requirements.
- Personal Productivity and Privacy
- On‑device email/notes summarization with ephemeral learning
- Sector: consumer productivity. Private, session‑adaptive assistant for personal archives without server‑side retention.
- Tools/workflows: Desktop “TTT mode” leveraging local GPU/NPU; per‑session reset to protect privacy.
- Assumptions/dependencies: Local compute must support gradient updates; power/thermal constraints; model size selection.
Long‑Term Applications
These require further research, scaling, tooling maturity, or regulatory work before broad deployment.
- Million‑token and beyond contexts
- Sector: cross‑industry. Analyze entire bookshelves, national archives, or massive monorepos in a single session.
- Tools/workflows: “1M+ token analyzers” with multi‑stage extension and smarter scheduling of b, k across stages.
- Assumptions/dependencies: Further scaling of TTT‑E2E, memory optimizations, distributed/streaming TTT, specialized hardware.
- Safe continual learning across sessions
- Sector: all. Consolidate valuable fast‑weight knowledge into stable memory without catastrophic forgetting or drift.
- Tools/workflows: “TTT memory manager” for consolidation, audits, and decay; policy‑driven retention; uncertainty‑aware updates.
- Assumptions/dependencies: New algorithms for selective consolidation, safety/eval suites, and governance controls.
- Agentic systems with self‑generated review and curriculum during TTT
- Sector: software/edtech. The model writes mini‑batch “reviews” or rationales to stabilize and guide its own TTT.
- Tools/workflows: “Self‑curation TTT” that synthesizes structured notes/checklists per batch, then trains on them.
- Assumptions/dependencies: Reliable self‑evaluation and guardrails; research on when self‑generated data helps vs. harms.
- Edge/Embedded and Robotics
- Sector: robotics/IoT. On‑robot adaptation to long‑horizon instructions, environment logs, and user preferences, with constant latency.
- Tools/workflows: “TTT‑enabled planners” and instruction followers with fast‑weight updates on embedded accelerators.
- Assumptions/dependencies: Real‑time training compute on edge chips, robust safety envelopes, low‑precision TTT.
- Regulated Healthcare CDS
- Sector: healthcare. Real‑time clinical decision support assimilating full patient histories inside care workflows.
- Tools/workflows: Bedside “chart copilot” integrated with EHR and order entry; continual adaptation to clinician style.
- Assumptions/dependencies: Clinical trials, FDA/EMA approvals, traceability of fast‑weight updates, medico‑legal liability frameworks.
- Live Trading/Risk Systems with Model Updates at Inference
- Sector: finance. Streaming assimilation of market context and firm‑specific signals.
- Tools/workflows: “Regulated TTT serving” with deterministic seeds, rollbacks, and lineage logs for every update.
- Assumptions/dependencies: Compliance rules for adaptive models; stress testing; strict auditability and reproducibility.
- Multi‑tenant TTT Orchestration at Scale
- Sector: cloud/MLops. Shared clusters scheduling per‑session gradient steps, state isolation, rate limiting, and fairness.
- Tools/workflows: “TTT scheduler/orchestrator,” admission control, state quotas, preemption policies.
- Assumptions/dependencies: Serving frameworks that unify inference/training paths, kernel fusion for backward passes, cost accounting.
- Energy/Manufacturing/IoT Long‑Horizon Analytics
- Sector: energy/industrial. Assimilate months‑to‑years of sensor logs for maintenance, forecasting, and anomaly detection.
- Tools/workflows: “Long‑horizon anomaly detector” with domain‑adapted TTT and hybrid symbolic checks.
- Assumptions/dependencies: Domain shift handling, label scarcity mitigation, integration with SCADA/OT systems.
- Education: Lifelong Learning Companions
- Sector: edtech/consumer. Personal tutors that accumulate and refine knowledge over years while preserving privacy and control.
- Tools/workflows: Consent‑aware profiles, parental/learner controls, episodic resets with selective consolidation.
- Assumptions/dependencies: Privacy law compliance (FERPA/GDPR), explainability, safe memory policies.
- CI/CD and Build Intelligence
- Sector: software. Ingest test logs, build errors, and code diffs across many runs to recommend fixes and flaky test triage.
- Tools/workflows: “CI TTT Assistant” connected to version control and issue trackers.
- Assumptions/dependencies: Integration complexity, false positive management, cost controls.
- Enterprise Security (SIEM/XDR)
- Sector: security. Cross‑product, long‑horizon event triage and correlation with constant latency.
- Tools/workflows: “TTT SIEM copilot” with automatic hypothesis generation and fast‑weight accumulation of campaign TTPs.
- Assumptions/dependencies: High precision requirements, red‑team validation, incident forensics alignment.
Cross‑cutting Assumptions and Dependencies
- Serving requirements: inference with gradient steps (TTT) needs training‑capable hardware and frameworks; state must be ephemeral per session unless explicitly consolidated.
- Model availability: benefits rely on meta‑trained initialization optimized for post‑TTT loss; porting existing models requires retraining or adaptation.
- Stability and safety: TTT hyperparameters (mini‑batch size b≈1K, window k≈8K, which layers to update) affect stability, latency, and forgetting; monitoring and rollback are essential.
- Data quality and tokenizer: modern tokenizers and higher‑quality data improved outcomes in the paper; domain data preparation matters.
- Governance: dynamic behavior complicates auditability, reproducibility, and compliance; require logs of update steps, seeds, and checkpoints.
- Scalability: contexts beyond 128K and stringent latency SLAs will need further engineering (distributed TTT, kernel optimizations, memory planning).
Collections
Sign up for free to add this paper to one or more collections.