- The paper introduces a hybrid expert framework that integrates VLM-based scene understanding, Mixture-of-Transformers for trajectory planning, and video generative modeling.
- It employs a multistage training paradigm using long-tail driving datasets to achieve superior performance in object detection, causal reasoning, and motion prediction.
- Empirical results demonstrate enhanced small object detection, robust accident prediction, and improved planning outcomes, underscoring the model’s impact on interpretable autonomous systems.
Unified Multimodal Reasoning for Autonomous Driving: An Expert Overview of UniUGP
Introduction
The "UniUGP: Unifying Understanding, Generation, and Planning For End-to-end Autonomous Driving" (2512.09864) paper presents a unified architecture for autonomous driving that synthesizes scene understanding, future video generation, and trajectory planning. By integrating pre-trained Vision-LLMs (VLMs) and video generative models into a hybrid expert framework, UniUGP aims to address the limitations of prior vision-language-action (VLA) paradigms and world model-based approaches—specifically targeting the challenges of long-tail scenario generalization, cross-modal causal reasoning, and system interpretability.
Hybrid Expert Architecture
UniUGP utilizes a tripartite expert system comprising understanding, planning, and generation agents. The understanding expert leverages VLMs for next-token prediction, enabling robust causal scene reasoning. The planning expert implements a Mixture-of-Transformers (MoT) framework with flow matching for continuous, physically consistent trajectories. The generation expert, drawing on world model principles, produces future video sequences conditioned on scene semantics and planning outputs.
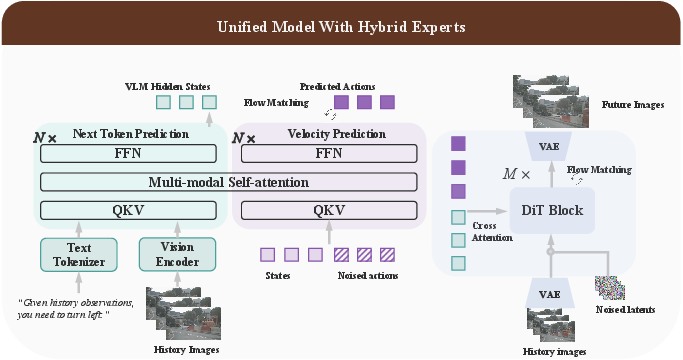
Figure 1: The UniUGP hybrid expert configuration: understanding drives causal reasoning, planning produces trajectories via flow matching, and generation synthesizes future video.
Dataset Construction and Benchmarking
A bespoke data pipeline aggregates long-tail driving datasets—including Waymo-E2E, DADA2000, Lost and Found, StreetHazards, SOM, and AADV—covering rare accident anticipation, object-centric hazards, and complex scene interactions. This data is recast into a unified QA benchmarking format, spanning understanding (small object and accident detection), chain-of-thought (CoT) reasoning, trajectory planning, and instruction-conditioned action execution.
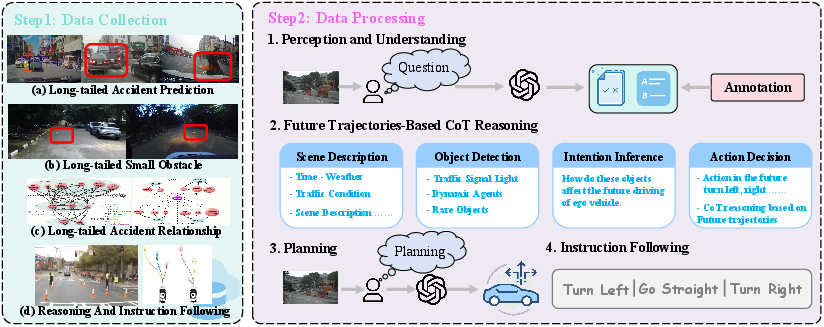
Figure 2: Multi-dataset integration for task-specific processing: scene understanding, CoT reasoning, planning, and instruction following.
Multistage Training Paradigm
UniUGP is trained in four sequential stages:
- Stage 1: Perceptual scenario understanding using annotated long-tail and ImpromptuVLA datasets.
- Stage 2: Visual dynamics modeling and planning via public video-trajectory corpora (nuScenes, NuPlan, Waymo, Lyft, Cosmos).
- Stage 3: Augmentation with CoT causal reasoning (custom labeled).
- Stage 4: Fusion training for cross-expert synergy using a fixed ratio dataset blend.
Consistent temporal and modality-specific alignment is enforced through a multi-term loss function regulating CoT logic, trajectory smoothness, and video coherence.
Ablative and Comparative Experimental Validation
Empirical evaluation across novel benchmarks demonstrates strong compositional improvements. UniUGP outperforms GPT-4o, Qwen2.5-VL-72B, and its own ablated variants in understanding (small objects: 89.3%, relationship: 88.6%, accident prediction: 95.8%), reasoning (CoT GPT score: 0.88, BLEU: 0.240), planning (L2 3s: 1.45), and instruction following (L2 3s: 1.40).

Figure 3: Ablation study: World model-aware VLA prioritizes distant object semantics and future causal dependencies.
In addition, the generation expert yields trajectory-conditional synthesis with competitive FID (7.4) and FVD (75.9) on future frame generation tasks.
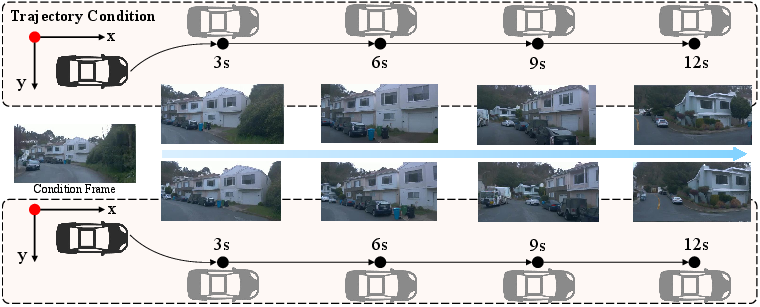
Figure 4: Trajectory-aware controllable video generation: future frames are directly influenced by planning outputs.
CoT reasoning in UniUGP exhibits more actionable and scene-specific planning than general-purpose LLMs (e.g., GPT4o), substantiating the synergy between semantic understanding and decision generation.


Figure 5: CoT comparison: UniUGP delivers detailed, context-sensitive plans beyond GPT4o's generic outputs.
Generalization to Long-Tail and Multi-Condition Scenarios
UniUGP demonstrates robustness in rare and ambiguous driving contexts, leveraging integrated causal reasoning and multimodal predictions. The generation expert facilitates controllable synthesis under weather and trajectory variations:


Figure 6: Video generation under variable weather conditions, evidencing condition-dependent synthesis.

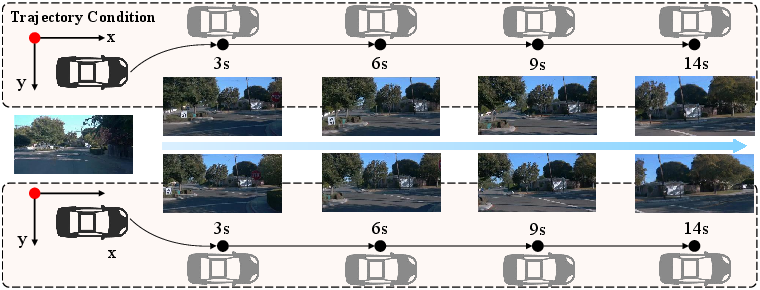
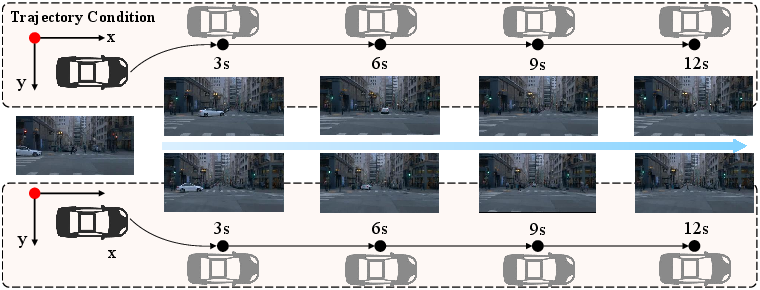
Figure 7: Video generation under controlled trajectory constraints, validating multimodal action-to-video alignment.
Benchmark results on DriveLM show UniUGP achieves superior scene-language system metrics (BLEU: 0.78, ROUGE: 0.76, accuracy: 0.74, final score: 0.59), exceeding FSDrive, OmniDrive, and recent language-action baselines.
Implications and Theoretical Impact
UniUGP exemplifies an explicit approach to scalable, interpretable autonomous driving systems:
- Multimodal Integration: By fusing VLM world knowledge with video generative modeling, UniUGP achieves exogenous causal reasoning and physically valid predictions.
- Alignment and Interpretability: The chain-of-thought module enhances transparency in planning decisions, a critical property for regulatory and safety auditing.
- Synthetic Data Utilization: World model augmentation enables learning from massive unlabeled videos, offering avenues for domain adaptation and zero-shot generalization.
The framework, however, poses computational bottlenecks in generation, and future work may address expert distillation and adaptive training strategies. Extending interactive capabilities (real-time feedback, multi-agent interplay) and continual adaptation for rare-event robustness are open research trajectories.
Conclusion
UniUGP (2512.09864) establishes a unified, hybrid-expert paradigm for autonomous driving, delivering SOTA results across understanding, reasoning, planning, and video generation tasks. Its multi-stage training and hybrid architecture substantiate coherent multimodal knowledge transfer, robust long-tail generalization, and interpretable decision frameworks. This research provides a substantial reference model for future embodied intelligence systems, with practical implications for scalable, safety-critical deployment in open-world environments.