- The paper introduces an end-to-end framework that directly generates binaural audio from video, bypassing two-stage methods and improving spatial fidelity.
- It employs dual-branch audio generation and a conditional spacetime module to capture precise interchannel dependencies and robust video-audio synchronization.
- Experimental results on BiAudio and other datasets demonstrate significant improvements in both perceptual and objective metrics, validating enhanced spatial and temporal accuracy.
End-to-End Binaural Spatial Audio Generation from Video: The ViSAudio Framework
Introduction and Motivation
Spatial audio synthesis, particularly binaural rendering from video, is significant for immersive virtual and augmented reality systems. Traditional approaches largely focus on mono audio generation or employ a two-stage paradigm where mono audio is first synthesized and then spatialized, often leading to misalignment and accumulation of errors in spatial cues. The paper "ViSAudio: End-to-End Video-Driven Binaural Spatial Audio Generation" (2512.03036) introduces an end-to-end pipeline for generating spatially immersive binaural audio directly from silent video, targeting the limitations of existing two-stage frameworks by ensuring tighter audio-visual alignment, increased spatial fidelity, and robust generalization across varied acoustic environments.
BiAudio: A Large-Scale Dataset for Binaural Audio Synthesis
The lack of sufficiently large and diverse open-domain datasets for spatial audio generation is a bottleneck for training and evaluating advanced generative models. The BiAudio dataset presented in this work comprises approximately 97,000 video-binaural audio pairs, totaling 215 hours, featuring diverse real-world scenarios and extensive camera motion configurations. Unlike extant datasets biased towards constrained domains (e.g., music, street scenes) or synthetic settings, BiAudio employs a semi-automated construction pipeline, including 360° video projection for viewpoint diversification and head-related impulse response (HRIR)-based convolution for binaural rendering. Notably, a two-stage LLM pipeline generates structured captions annotating visible and invisible (off-screen, environmental) sound sources in each clip, facilitating nuanced supervision.
ViSAudio Framework: Architectural Innovations
ViSAudio departs from the prevalent two-stage audio spatialization pipeline by introducing an end-to-end architecture that is explicitly conditioned on video (and optionally text), jointly generating the left and right binaural audio channels. The architecture employs two core modules:
- Dual-Branch Audio Generation: Two dedicated neural branches estimate latent flows for the left and right channels, facilitating spatially coherent but distinct outputs. This design is critical for capturing interchannel dependencies necessary for accurate binaural perception, unlike approaches directly using stereo VAEs that ignore explicit spatial correspondence.
- Conditional Spacetime Module: This module aggregates spatiotemporal and synchronization features from the video. Specifically, it leverages CLIP for visual/text embeddings, Synchformer for temporal alignment, and a perception encoder with positional embeddings for spatial features. These are injected into channel-specific transformer blocks, enabling the model to capture spatial layout and transients in sound events.
The overall pipeline is built upon conditional flow matching (CFM), which provides an efficient and consistent generative modeling trajectory from noise to audio latent codes. The model decodes these latents with variational autoencoders (VAEs), with subsequent vocoding to reconstruct waveform-level binaural signals.
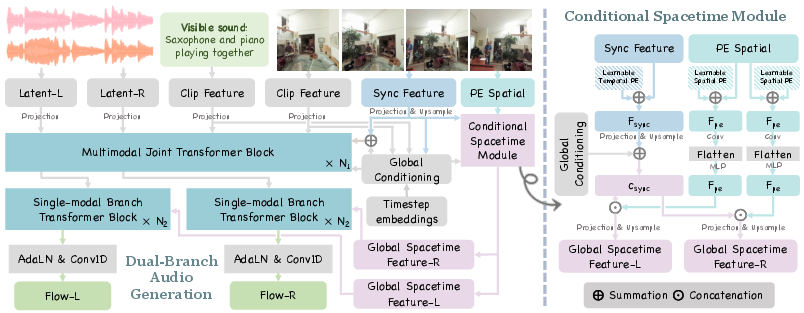
Figure 1: The ViSAudio network utilizes dual-branch audio generation along with a conditional spacetime module, ensuring explicit modeling of binaural channel correlations and spatiotemporal video-audio consistency.
Experimental Evaluation
Objective and Subjective Metrics
The experimental evaluation benchmarks ViSAudio against prior state-of-the-art methods (ThinkSound, AudioX, ViSAGe, See2Sound) across three datasets: BiAudio, MUSIC-21, and FAIR-Play (OOD). Performance is reported using several distributional and perceptual alignment metrics (Fréchet Distance/FD, KL-divergence, DeSync, IB-Score). ViSAudio dominates all metrics, in some cases by substantial margins—on BiAudio, FDVGGavg drops from 3.81 (second best) to 2.48, and IB-Score climbs from 0.235 to 0.299. Notably, it retains strong generalization on out-of-domain scenarios (FAIR-Play), supporting the dataset design and model architecture claims.
A user study with expert raters further corroborates the objective findings; ViSAudio attains mean opinion scores above 4/5 on spatial impression, spatial consistency, temporal alignment, semantic align, and audio realism—significantly surpassing all baselines. These results underline the representational benefits of end-to-end learning and targeted architectural components.
Qualitative Analysis
Qualitative examples demonstrate the model's ability to synthesize binaural cues dynamically as the camera moves and the sound source location shifts in the visual field—a key requirement for perceptual plausibility in immersive applications. In the provided example, as the sound source (a sitar player) traverses from the right to the left of the camera's field, the model accurately adjusts the interaural differences in the synthesized audio, tracking the source in a temporally consistent and spatially plausible manner.
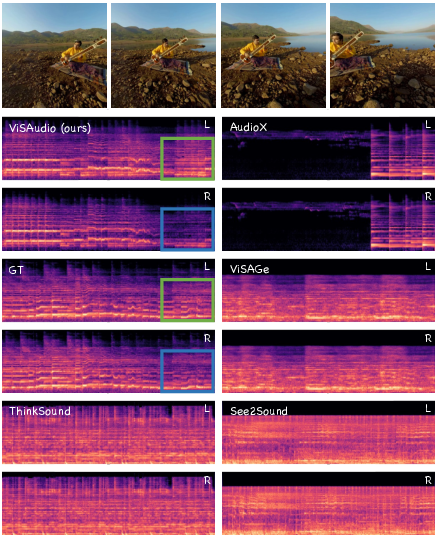
Figure 2: ViSAudio generates binaural audio closely matching the ground truth, dynamically modeling the spatial trajectory of the sound source as the camera pans.
Ablation and Dataset Design Insights
Ablation studies confirm the necessity of both the dual-branch audio generation and the conditional spacetime module. Omitting either module degrades the spatial distinctiveness and alignment properties of the output. An additional study contrasts training with/without BiAudio, showing that the absence of large-scale spatialized data severely impacts downstream spatial audio synthesis on open-domain scenes.
Implications and Future Directions
The results position ViSAudio as a reference model for end-to-end spatial audio generation, suggesting immediate utility for VR/AR content creation, automated video post-production, and foundation model research on multimodal perceptual grounding. The approach opens several avenues for future research:
- Extending temporal modeling for long-form scenes to capture persistent acoustic events and environments.
- Expanding to higher-order ambisonics or multi-channel spatial rendering beyond binaural.
- Jointly modeling listener position/orientation or adaptive HRTF selection for personalized spatial audio experiences.
- Unifying audio-visual generative modeling with reinforcement learning for closed-loop immersive systems.
Conclusion
ViSAudio effectively addresses critical limitations of prior video-to-spatial-audio synthesis approaches by integrating dual-branch generative modeling and advanced spatiotemporal conditioning in an end-to-end pipeline. Supported by the BiAudio dataset, it achieves state-of-the-art objective and subjective performance in binaural audio generation and demonstrates strong cross-domain generalization. This work sets a new foundation for research in multimodal audio rendering, highlighting both methodological advances and practical implications for future spatial computing systems.